怎样排查calico的网络故障?
目录
说明
Calico实际应用中踩过的一些坑发布后,不少朋友添加了我的微信。很多在 踩坑calico的朋友无私的把自己在实践中遇到的一些问题,分享给了我。然而每个人的情况 各不相同,各自的环境也不完全一致,我未能给这些朋友做出很好的解答,对此,我一直感到很抱歉。
我试图通过这篇推送,帮助还在对calico感到迷惑朋友建立起清晰的认识,进而掌握排查问题的方法。 “授人以鱼,不如授人以渔”,我对这句话的理解是:
要建立清晰的知识体系,面对千变万化的各种问题时,能够有明确的排查思路,以不变应对万变。
这比直接得到答案要有用太多了。在这篇推送中,我会给出一些我认为有用的内容,虽然不会细致地 说明每个知识点,但我一定会告诉你,到哪里可以找到答案。后半部分,以“网络不通”为例, 给出了一个排查问题的思路。
善用官方文档
官方文档是最好的资料,没有之一。在写作此文的时候,我看了一下,Calico已经更新到了3.0,文档 也同步更新。稍微晚一点接触一个开源项目是幸福的,因为有潜力的项目,它的文档会越来越详尽,譬如现在 的k8s文档。Calico的官方文档是最好的,要使用calico的朋友,应当尽可能多看一些。
不足的是,Calico的文档没有做到循序渐进,将很多内容一起罗列了出来,对初学者造成不少困扰。 我当初也是花费了大量的时间,耐着性子一页一页地读,然后结合实践和源码,才建立起了比较完备 的认识。
补充基础知识
在学习Calico之前,我对BGP协议有一定的了解,这对我的帮助很大。想通了BGP之后,才会明白 Calico的原理,才会在脑海中会浮现出一个猜想的实现。猜想带来的方向感,比猜想本身更重要。
想通原理后,研读Calico的资料时,实际就是在验证自己的猜想。如果猜想得到了验证,就会 感觉很踏实,猜想没有得到验证,通常会感到疑惑,内心彷佛缺失了一块,非常不舒服。疑惑是好事, 说明马上就要进步了。
关于BGP,可以读一下《CCNP Router (642-902)学习指南》的第6.1节:《BGP术语、概念和工作原理》。

这里插一句,为什么要去看CCNP,而不是网上找点博客笔记看呢?我的态度是,要用,就用最权威的资料。 这里其实隐藏了另一个问题:什么资料最权威?如果你知道了一个领域中最权威的资料在哪里,基本上 就是这个领域里的半个专家了。不信的话,你可以在工作生活中留意下,有多少人、哪些人在使用最权威的资料。
在这之前,我在网络协议、云计算、SDN网络里浸泡了些许时间,这些经历都是很有帮助的。在这方面多 做一些储备也是有益无害的。这些方面的储备,可以让你明白,要解决的问题是什么。具体到Calico就是:
Calico要解决的问题是什么?为什么可以用BGP实现?优点和缺点分别是什么?
随着基础知识的增加,这个问题的答案会越来越清晰。我在上一篇推送写下的这段话,或许会对你有帮助:
宿主机变身路由器后,现实的网络是怎么联通的,虚拟机们就怎么联通,技术都是现成的,
并且都已经支撑起连接全地球的互联网了。你只要把握住了这一点,你就搞懂了Calico。
另外iptables的知识是必须掌握的,不仅calico会设置大量的iptables规则,docker和kuberntes也会设置,所以 掌握iptables是必须的。可以参考linux的iptables使用中的内容。
准备实践环境
Calico另一个对初学者不友好的地方是,它难以单独部署。鉴于绝大多数人都是将其用于Kubernetes,所以 最简单的实践环境还是使用calico官方提供的yaml,在k8s中部署。
凡事都有两面性,容器技术带来了极大的便利,越来的越多的系统以镜像的形式发布。到了Kubernetes时代, 更是直接提供一个yaml文件,这种方式确实很便利,但是也隐藏了大量细节。
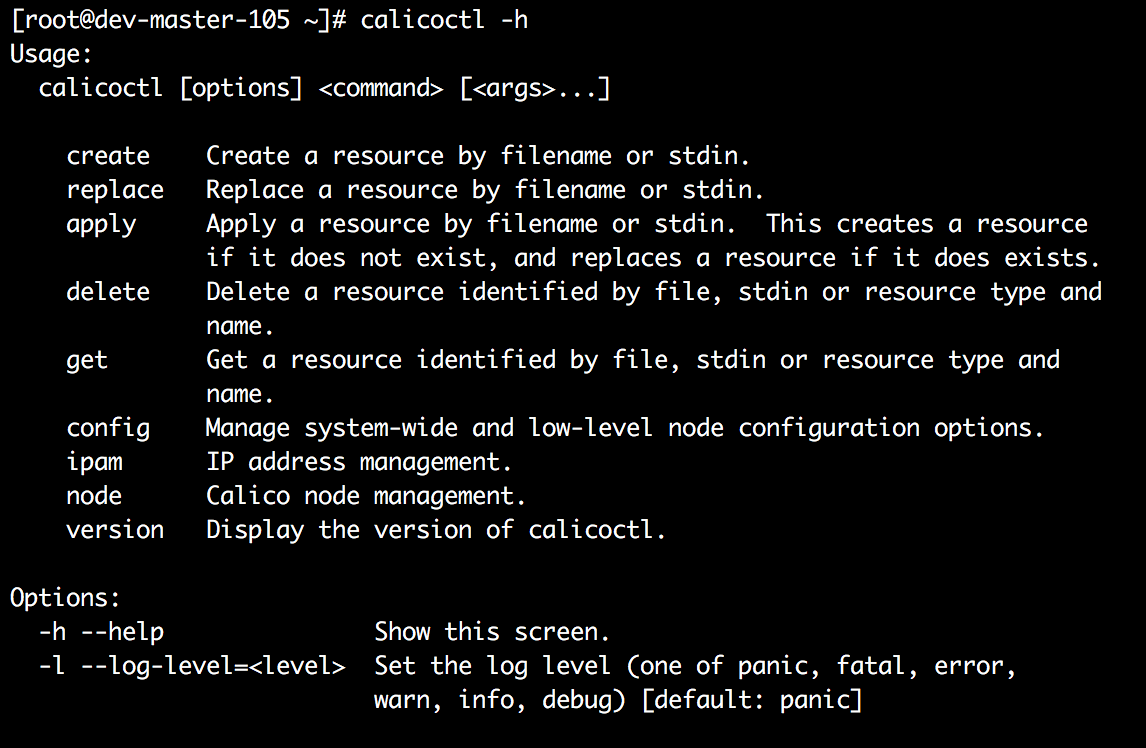
在实践中了解calico的时候,首先要有一个calicoctl命令。实践学习、排查问题的时候 主要就是用这个命令从calico中查询信息。calicoctl现在是一个独立的项目,可以从github上下载。
掌握基本概念
Calico中的资源主要有以下几个:

可以用calicoctl命令操作这些资源,calico的网站上已经有非常详细的介绍:

BGP Peer:
Calico中的每个node在网络中扮演了BGP发言人的角色,这里的BGP Peer是外部BGP Peer。
可以将Node设置为与外部的BGP Peer通信。
HostEndpoint与WorkloadEndpoint:
Endpoint是Calico网络中网络接口,HostEndpoint是承担Calico的Host上的网卡。
WorkloadEndpoint是Calico中分配给容器或者虚拟机的网卡。
NetworkPolicy:
这是Calico的网络隔离策略。
更多内容,应当到Calico的官网上了解。
贡献一个猜想
如果你的基础知识已经准备完毕,知道了什么是BGP协议,如何用BGP协议达到目的。那么你就可以 猜想Calico的实现了。无非就是:
信息如何汇聚?指令如何下发?指令被谁执行?
为了节省你的时间,我这里直接告诉你:
每一个calico-node启动后都直接接入到etcd中,它们通过etcd感知彼此的变化。
calicoctl也是从etcd中读取系统的状态信息,指令是通过改写etcd中的数据下发。
指令的执行者有两个,一个是calio-node上的felix,它就是一个agent,负责设置iptable等。 另一个执行者是cni插件,kubelet创建Pod的时候会调用cni插件,cni插件负责为Pod准备 workloadendpoint。
此外还有一个名为bird的小软件,它和felix位于同一个镜像中,负责BGP通信,向外通告路由、设置本地路由。 它的详情自然应该到它的官网上了解了。
网络不通怎样查?
网络不通,这大概是最最常见的问题了。这个问题排查思路其实很简单,报文是怎样流动的, 那就怎样查,它在哪里丢失了,问题就在哪里。
如果你用Google、百度去搜索答案的话,你会得到各种各样的回答,一通试验,只会把自己的环境 越搞越乱。即使搞通了,很多时候也是运气的成分居多,当事人并没有真正地理解问题。
随着工作时间增加,解决过的问题越来越多,我愈发感觉到,很多问题的解决,其实只需要运用常识。 在Calico中,这个常识就是报文肯定不会凭空消失,它是一个真实的存在,不会突然出现,也不会突然湮灭, 而且肯定是可以被跟踪的。
当你遇到一个无论如何也找不到根源、非常棘手的问题时,反复思考,反复地运用常识,会是 一个很好的解决疑难杂症的方法。人造的事物,不会超出人的认识。
一个例子
太多形而上的内容,未免过于玄幻,还是有个例子更好。这里直接给出一个排查过程。
假设从容器A中无法访问容器B,我们要做的就是从两个方向跟踪。
(第一个方向,发送)
1. 容器A内生成的报文是否被送到了容器A所在的node
2. 容器A所在的node是否将报文送了出去
3. 容器B所在的node是否收到了容器A所在的node发送来的报文
4. 容器B所在的node是否将报文送到容器B中
(第二个方向,回应)
5. 容器B的回应报文是否被送到了容器B所在的node上
6. 容器B所在的node是否将回应报文送了出去
7. 容器A所在的node是否收到了容器B所在的node转发的回应报文
8. 容器A所在的node是否将回应报文送到了容器A中
发送方向
从calico中获取发送端容器A的workloadEndpoint:
$calicoctl get workloadendpoint --workload=<NAMESPACE>.<PODNAME> -o yaml
- apiVersion: v1
kind: workloadEndpoint
metadata:
labels:
calico/k8s_ns: <NAMESPACE>
name: sshproxy-internal
pod-template-hash: "3693247749"
name: eth0
node: dev-slave-107
orchestrator: k8s
workload: <NAMESPACE>.<PODNAME>
spec:
interfaceName: cali69de609d5af
ipNetworks:
- 192.168.8.42/32
mac: b2:21:5b:82:e1:27
profiles:
- k8s_ns.<NAMESPACE>
我们可以得到发送端容器A的以下信息:
1. 容器内的IP为192.168.8.42/32,mac地址是b2:21:5b:82:e1:27
2. 容器位于node端的网卡为cali69de609d5af
3. 容器位于名为dev-slave-107的node上
特别注意第二条,我们将通过这个网卡确认容器是否已经将报文送到所在的node。
检查发送端的容器A
查看容器A内的网卡是否正确,ip和mac是否与从calico中查询到的一致:
sh-4.2# ip addr
...
3: eth0@if57: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether b2:21:5b:82:e1:27 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.8.42/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::b021:5bff:fe82:e127/64 scope link
valid_lft forever preferred_lft forever
查看容器的默认路由是否是168.254.1.1,且没有额外的路由:
sh-4.2# ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
在容器所在的node上读取node对应的calico网卡的mac,确认是否与calico中查询到的mac一致:
$ip link show cali69de609d5af
57: cali69de609d5af@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT
link/ether ea:88:97:5f:06:d9 brd ff:ff:ff:ff:ff:ff link-netnsid 2
查看容器内记录的168.254.1.1的mac地址是否是node上的calico网卡的mac:
sh-4.2# ip neigh
169.254.1.1 dev eth0 lladdr ea:88:97:5f:06:d9 REACHABLE
这里需要一点说明,使用calico后,在容器内只有一条默认路由,所有的报文都通过169.254.1.1送出。 但是这个IP是被保留的无效IP,那么报文怎么还能送出去呢?
秘密就是容器内的arp记录,在容器内记录的169.254.1.1的mac地址是:node上的caliXX网卡的mac。
node上的caliXX网卡和容器内的eth0网卡,是一对veth设备。veth网卡的特性是,向eth0写入的报文, 通过caliXX流出。容器中向eth0写入的报文的目的mac是caliXX网卡的mac,当报文经caliXX流出时,就 进入到了node的协议栈中,开始在node的网络空间中流转。
检查发送端的node
在发送端容器所在的node上用tcpdump监听cali69de609d5af网卡,查看是否能够收到容器A发出的报文:
$tcpdump -i cali69de609d5af
检查发送端node上的路由,目标IP的下一跳地址是否正确,目标IP是容器的地址,下一跳是否对应了正确的node ip:
$ip route
...
192.168.60.128/26 via 10.39.0.140 dev eth0 proto bird
...
这条路由就是通过BGP协议得知的,它的意思是说192.168.60.126这个IP可以通过10.39.0.140到达。
然后还需要检查发送端node上的iptables规则,看一下iptable是否拒绝了这个报文。iptables的规则比较多, 这里就不展开了。需要注意很多组件都会这是iptables规则,有可能是别的组件,譬如docker,设置的规则导致不通。
检查接收端的node
从calico中获取接收端容器B的信息:
$calicoctl get workloadendpoint --workload=<NAMESPACE>.<PODNAME> -o yaml
- apiVersion: v1
kind: workloadEndpoint
metadata:
labels:
calico/k8s_ns: <NAMESPACE>
name: sshproxy-cluster
pod-template-hash: "162298777"
name: eth0kj
node: dev-slave-140
orchestrator: k8s
workload: <NAMESPACE>.<PODNAME>
spec:
interfaceName: calie664becc2fd
ipNetworks:
- 192.168.60.173/32
mac: da:ba:8d:7a:45:dc
profiles:
- k8s_ns.<NAMESPACE>
可以得到接收端容器的以下信息:
1. 接收端node上的calio网卡为calie664becc2fd
2. 容器位于dev-slave-140
监听容器B所在node的网卡,检查是否收到了容器A所在的node发送来的报文:
$tcpdump -i eth0 (在node上抓包)
检查容器B所在node上的路由,检查目标IP是否对应了正确的calico网卡:
$ip route
...
192.168.60.173 dev calie664becc2fd scope link
...
前面我们说明了报文如何从容器A到达容器所在的node,那么还有一个问题是, 报文又是怎样从node到达容器内部的呢?
秘密是node上的路由。
上面那条路由的意思是,192.168.60.173这个IP对应的网卡是caliXXX,于是报文被写入到了这个网卡。 我们前面说过了,这个网卡和容器内的网卡是一对veth设备,因此报文会通过容器内的eth0流出,从而 进入到容器的网络空间中。
这里同样需要检查接收端node上的iptables规则,看一下报文是否被iptables拒绝。
检查接收端的容器B
这一步很简单,直接在容器B内,用tcpdump抓包,看一下报文是否成功的进来了。
回应方向
回应方向的跟踪方法和发送方向相同,只需要把前面步骤中的发送端和接收端对调即可。
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文