用爬虫插件 webscraper 抓取网页内容的方法
目录
说明
WebScraper 是一个浏览插件,支持 Chrome/Firefox 等主流浏览器,能够快速方便地爬去网页内容,不需要写代码。
安装方式
Chrome 和 Firefox 的应用商店中都有,直接安装即可:
使用方法
WebScraper 和其他常规插件不同,需要到开发者工具中查看,
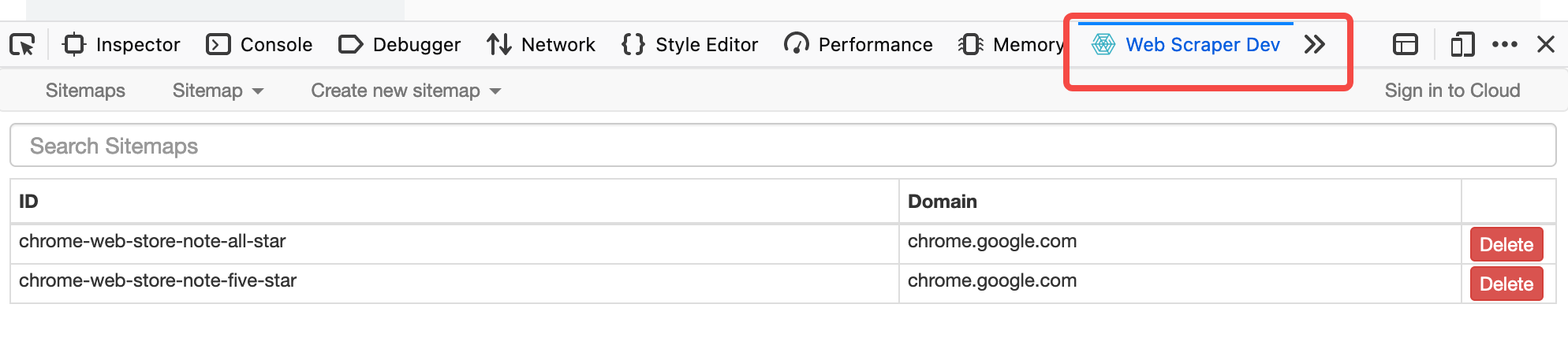
当前网页是 Chrome Web Store 时,开发者工具中不会出现的 WebScraper。如果要爬取 Chrome Web Store 的数据,可以换个浏览器比如 Firefox。
第一步:Create New sitemap
输入目标网址,支持添加多个目标网址。
第二步:在新建的 sitemap 中添加 Selector,即要爬取的元素
selector 的类型比较多,这里不展开。
第三步:点击中间的 sitemap,从下拉列表中选择 scraper
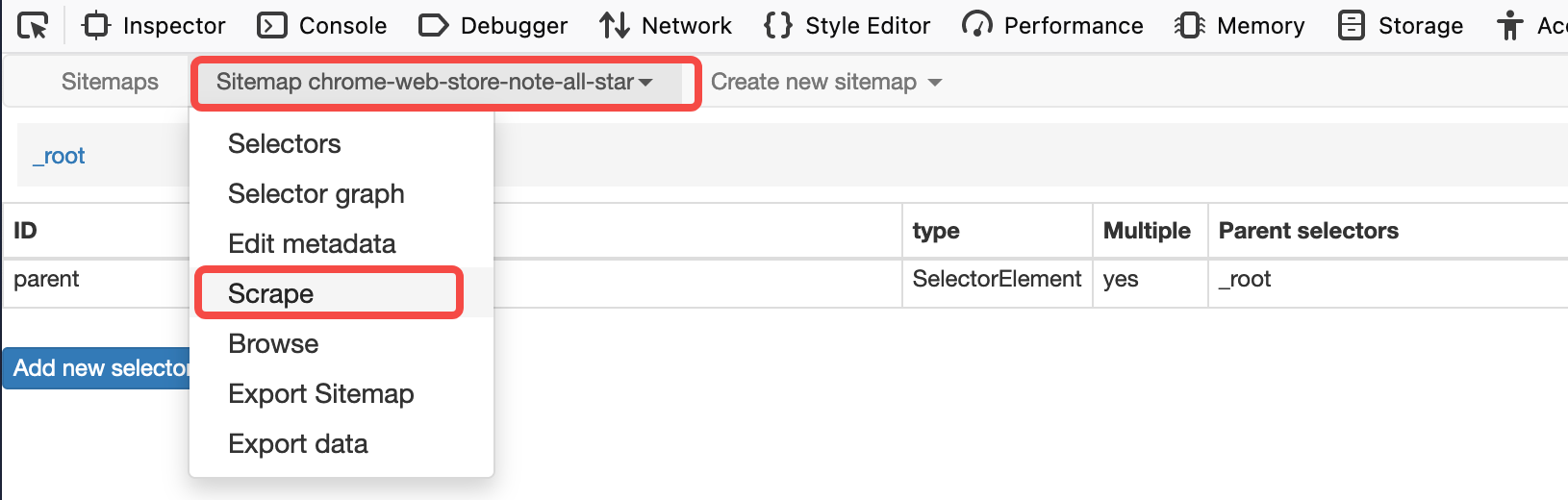
之后会进入请求间隔时间和页面等待时间的设置页面,完成设置后,即开始在打开一个新的浏览器窗口开始爬取操作。
爬取完成后,新开的浏览器会自动关闭,在原先的浏览器开发者中工具中点击刷新,查看数据。或者从对应 sitemap 的下拉列表中选择 export data。
Selector 简要说明
Selector 按照树型组织,即一个根 Selector,根 Selector 下面多个子 Selector,子 Selector 可以继续下挂 Selector。
在 WebScrper 的窗口中打开目标页面后,点击 “Selector” 进入筛选模式,直接用鼠标点击目标网页中需要爬取的元素,WebScraper 会自动分析出这些元素选择器。
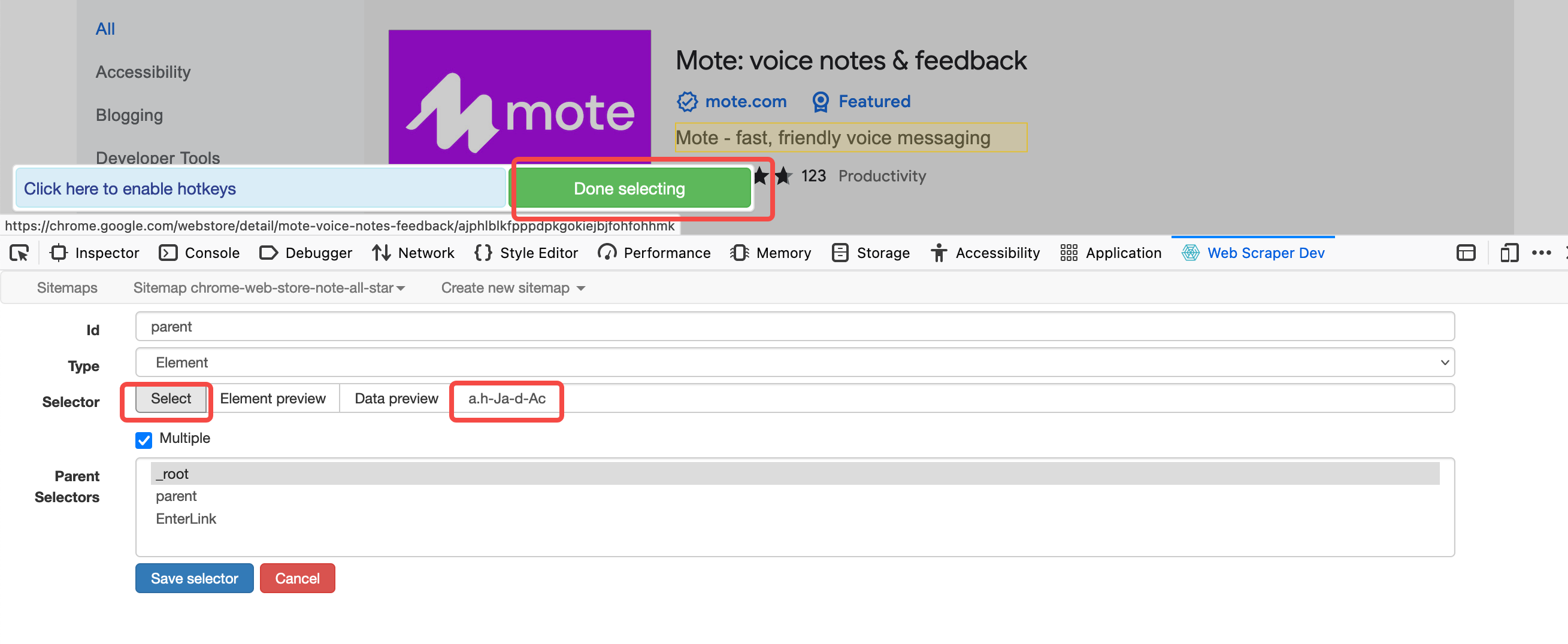
勾选 Multiple 后,从选中所有命中的 element,否则只选择第一个。
Link 类型
Link 类型的选择器如果没有子节点,就直接爬去当前 Link 的 href 的等信息。
Link 类型的选择器如果有子节点,会打开对应的链接,从新打开的网页中爬取数据。
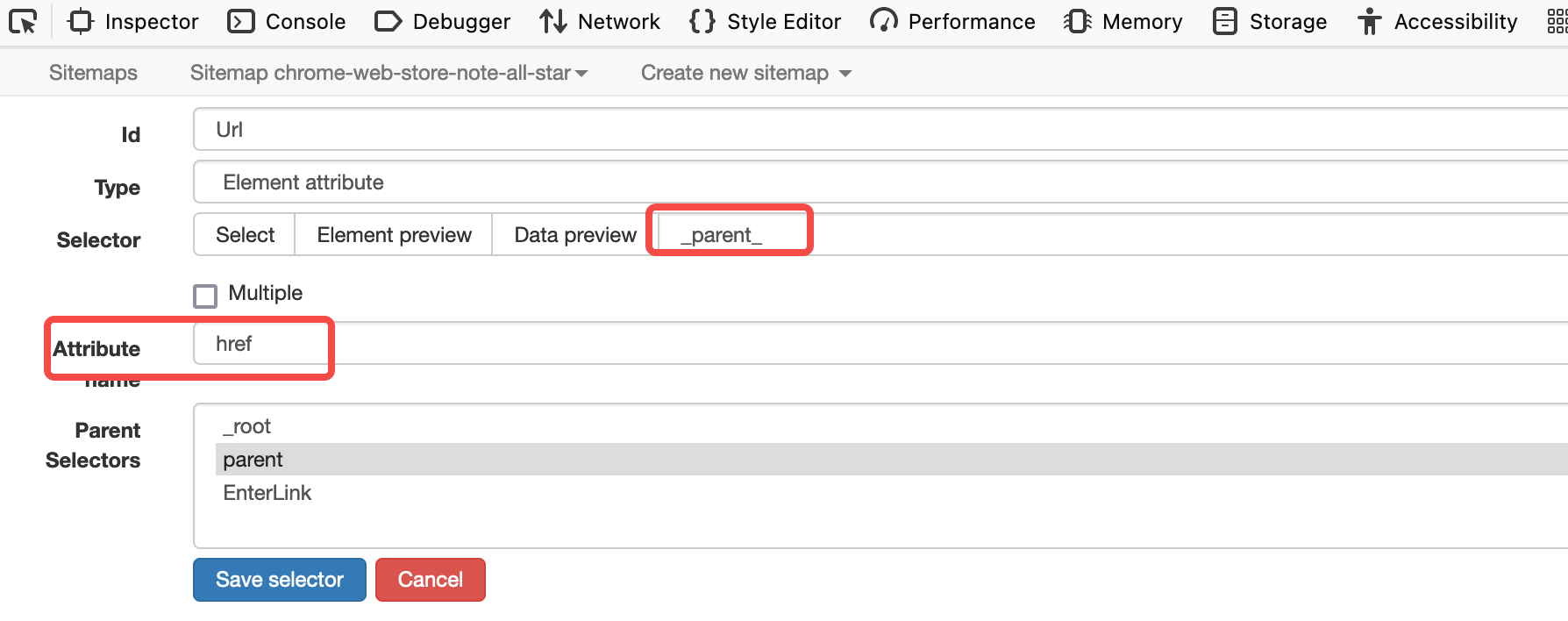
Element attribute 类型
Element attribute 类型用来提取 element 的属性,可以提取上层 element 选择器选中的元素的属性(Selector 中填写为_parent_)
例子
{"_id":"chrome-web-store-note-all-star","startUrl":["https://chrome.google.com/webstore/search/note?_category=extensions"],"selectors":[{"id":"parent","parentSelectors":["_root"],"type":"SelectorElement","selector":"a.h-Ja-d-Ac","multiple":true,"delay":0},{"id":"Name","parentSelectors":["parent"],"type":"SelectorText","selector":"div.a-na-d-w","multiple":false,"delay":0,"regex":""},{"id":"ScoreUsers","parentSelectors":["parent"],"type":"SelectorText","selector":"div.nAtiRe","multiple":false,"delay":0,"regex":""},{"id":"Url","parentSelectors":["parent"],"type":"SelectorElementAttribute","selector":"_parent_","multiple":false,"delay":0,"extractAttribute":"href"},{"id":"WebSite","parentSelectors":["parent"],"type":"SelectorText","selector":"span.e-f-y","multiple":false,"delay":0,"regex":""},{"id":"Description","parentSelectors":["parent"],"type":"SelectorText","selector":"div.a-na-d-Oa","multiple":false,"delay":0,"regex":""},{"id":"Category","parentSelectors":["parent"],"type":"SelectorText","selector":"div.a-na-d-ea","multiple":false,"delay":0,"regex":""},{"id":"EnterLink","parentSelectors":["parent"],"type":"SelectorLink","selector":"_parent_","multiple":false,"delay":0},{"id":"UsersNum","parentSelectors":["EnterLink"],"type":"SelectorText","selector":"span.e-f-ih","multiple":false,"delay":0,"regex":""},{"id":"LastUpdateTime","parentSelectors":["EnterLink"],"type":"SelectorText","selector":"span.h-C-b-p-D-xh-hh","multiple":false,"delay":0,"regex":""},{"id":"Version","parentSelectors":["EnterLink"],"type":"SelectorText","selector":"span.h-C-b-p-D-md","multiple":false,"delay":0,"regex":""},{"id":"OverView","parentSelectors":["EnterLink"],"type":"SelectorText","selector":"pre","multiple":false,"delay":0,"regex":""},{"id":"ReviewsNum","parentSelectors":["EnterLink"],"type":"SelectorText","selector":"span.dc-db","multiple":false,"delay":0,"regex":""},{"id":"Stars","parentSelectors":["EnterLink"],"type":"SelectorElementAttribute","selector":"div.Y89Uic","multiple":false,"delay":0,"extractAttribute":"title"}]}
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文