《High Performance MySQL, 4th Edition》高性能 MySQL 第四版阅读笔记
本篇目录
- 本篇目录
- 说明
- Chapter 1. MySQL Architecture
- Chapter 2. Monitoring in a Reliability Engineering World
- Chapter 3. Operating System And Hardware Optimization
- Chapter 4. Optimizing Server Settings
- Chapter 5. Optimizing Schema And Data Types
- Chapter 6. Indexing For High Performance
- Chapter 7. Query Performance Optimization
- Chapter 8. Scaling MySQL
- 参考
说明
《High Performance MySQL, 4th Edition,》还没有正式出版(2021-10-27 15:48:25),在 O’Reilly 的网站上可读,新注册用户可以免费阅读全文 10 天。
Chapter 1. MySQL Architecture
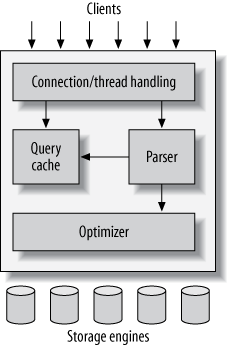
最外层:承接网络连接、认证等功能。
中间层:查询分析、优化、缓存、内置函数等。
最底层:存储引擎,向中间层提供操作 API,存储引擎不理解 SQL 也不产生通信。
MySQL 服务端已经支持了连接池,也提供对接第三方连接池等接口。
优化器执行优化动作时,需要获得存储引擎的特性、存储引擎执行特定操作的耗时、表中数据情况的统计值。
MySQL5.7.20 移除了查询缓存,它会成为并发时的性能瓶颈,结果缓存要由客户程序实现。
并发读写
并发读写的管理方法:
- 首先,用读写锁解决同一段数据的并发读写问题
- 其次,通过降低锁的粒度,提高并发读写性能,但是锁的粒度越小,锁管理带来的开销越大
- 表锁:server 实现了独立于存储引擎的表锁,譬如 alter table 时使用 server 实现的表锁
- 行锁:行锁由存储引擎实现,server 通常不感知存储引擎内部实现的锁
事务
事务内容这里主要讲解了熟知的 ACID 和隔离级别,提供了两篇参考阅读:
在事务中进行更新操作时,如果两个事务中的更新顺序不同,可能出现死锁。
事务1,先更改 stock_id = 4:
START TRANSACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2020-05-01';
UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = '2020-05-02';
COMMIT;
事务2,先更改 stock_id = 3:
START TRANSACTION;
UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = '2020-05-02';
UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = '2020-05-01';
COMMIT;
innodb 会识别这种循环依赖,发现后直接报错,其它数据库有可能使用超时的方式。
innodb 发现死锁后,会把加锁数量最少(使用估计数值)的事务回滚,客户程序需要处理这种情况,譬如重试。
事务日志/Transaction Logging 用来提高事务效率,将随机IO操作尽可能转变成顺序IO操作。
MySQL事务的特点:
- insert/update/delete 语句自动提交事务,可以用会话变量 AUTOCOMMIT 关闭自动提交
- set AUTOCOMMIT = 0,执行 commit 或者 rollback 后会立即开启一个新事务,即
会话一直处于事务中 - set AUTOCOMMIT = 1,用 begin、start transaction 开启需要执行多语句的事务
- 有些语句在事务中使用时,会自动提交当前事务,然后再执行自身,譬如 alter table、lock tables 等
- 事务由存储引擎实现,一个事务不能跨两个不同的存储引擎
- 事务由存储引擎实现,
如果在一个不支持事务的表上执行事务,MySQL 不会给出提示 - 事务中加的锁,都在 commit 或者 rollback 时释放
如果两个表使用不同的存储引擎,其中一张表不支持事务。在一个事务中同时操作这两张表,事务执行不会报错,回滚时,不支持事务的表上的数据不会回滚。
可以按会话设置事务的隔离级别:
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
显式加锁方法:
SELECT … LOCK IN SHARE MODE // MySQL 8.0 之前
SELECT ... FOR SHARE // MySQL 8.0 之后
SELECT ... FOR UPDATE
MVCC
MVCC 目的是减少行锁的使用。
读已提交和可重复读中使用了 MVCC,读未提交和串行化不需要使用 MVCC。
MVCC 没有统一的实现标准,各个引擎按自己理解实现。
Replication
MySQL的 Replication 含义是: 一个节点把收到的请求分发到其它多个节点上。
这部分内容后面有个专门章节说明。
存储引擎
Innodb 引擎情况:
- InnoDB 5.7 开始 支持动态 DDL,不需要锁全表
- InnoDB 5.7 开始支持 json
- InnoDB 8.0.7 开始支持 json 多值索引
MySQL支持的其它存储引擎以及特点:
- MyISAM engine:MySql 8.0 已经移除,不再支持
- Archive engine,只支持 select 和 insert,用于高速写入和存储压缩,每行数据用zlib压缩后存储,查询时全表扫描,不支持事务
- Blackhoe engine,只写日志,不存储数据
- CSV engine,直接读写 csv 文件
- Federated engine,代理到其它 server,容易引发各种问题 MySQL 默认关闭,mariadb 开发了继任 FederatedX
- Memory engine,不支持行锁,varchar等都是存放固定大小
- Merge storage engine,把几个 MyISAM 表虚拟成一个表,已经不建议使用
- NDB Cluster engine,对接 NDB 集群存储
Chapter 2. Monitoring in a Reliability Engineering World
略
Chapter 3. Operating System And Hardware Optimization
略
Chapter 4. Optimizing Server Settings
默认配置文件路径:
$ /usr/sbin/mysqld --verbose --help | grep -A 1 'Default options'
Default options are read from the following files in the given order:
/etc/mysql/my.cnf ~/.my.cnf /usr/etc/my.cnf
每个程序在配置文件中有自己的同名配置章节,譬如服务端的 mysqld 对应的配置章节是 [mysqld]。
配置项的作用域:
- global scope:对后续所有新建会话有效
- session scope:只对当前会话有效,断开连接后丢失
能在运行时修改的配置为动态配置(mysql重启后丢失),session scope 和 global scope 的修改方法:
SET sort_buffer_size = <value>;
SET GLOBAL sort_buffer_size = <value>;
SET @@sort_buffer_size := <value>;
SET @@session.sort_buffer_size := <value>;
SET @@global.sort_buffer_size := <value>;
MySQL 8.0 开始支持「持久化的修改」:
SET PERSIST ...
查看所有全局变量:
show global variables\G;
内存相关:
- 每个执行语句的连接占用的内存需要得到保证,否则会因为内存不足而执行失败
- 预留操作系统使用的内存
- InnoDB Buffer poll 是内存大户,缓存索引、行数据、change buffer、锁等,需要得到足够的保障
磁盘IO:
- InnoDB 通过日志文件,减少随机写
- tablespace 相关
Chapter 5. Optimizing Schema And Data Types
字段类型原则:
- smaller is usually better
- simple is good,能用数值不用字符串
- avoid null if possible,不允许存在 NULL 会有一定的提升,但是有限!
数值
整数/whole numbers:
tinyint 8 bits
smallint 16 bits
mediumint 24 bits
int 32 bits
bigint 64 bits
实数/real numbers:
- float 和 double 使用标准的浮点数运算计算出近似值
- float 32 bits,double 64 bits
- decimal 是精确的实数,没有精度损失
注意事项:
- MySQL 进行整数运算使用的是 bigint,float 和 double 的运算使用的是 double
- decimal 能够提供精确运算可以用于金融数字,但是运算开销大。建议把小数扩大一定倍数后,按整数对待
字符串
对于字符串,不同的存储引擎实现方式不同,下面都是 innodb 的行为。
变长字符串/varchar:
- 额外使用 1~2个字节存储字符串长度,超过 255 时使用两个字节记录
- varchar 节省存储空间,但是被更改时,一行数据的长度发生变化,会产生碎片或者页面分裂,导致额外的处理
- varchar 适用于最大长度比较大,很少被修改的场景
- MySQL 在处理 varchar 时会对它占用的内存进行悲观假设,varchar 的最大长度不要超过实际需要
定长字符串/char:
- 适用于短小的定长字符串,譬如密码的 md5 数值
- 通常比 varchar 更高效,并且对修改友好
变长字节/varbinary:
- 和 varchar 类似,存放变长的二进制字符串
定长字节/binary:
- 和 char 类似,存放二进制字符串
注意事项:
- binary 字符串的比较操作比 char 字符串更高效
- 如果 varchar(5) 满足需求,不要使用 varchar(200),MySQL 内部处理会对需要的内存进行悲观假设,譬如临时表
文本
文本被作为一个单独对象处理,innodb 会把大的文本单独存放。
字符文本/text:
tinytext
smalltext
text 等同于 smalltext
mediumtext
longtext
二进制文本/blob:
tinyblob
smallblob
blob 等同于 smallblob
mediumblob
longblob
注意事项:
- 对文本进行比较,MySQL 只比较最前面 max_sort_length 个字符
- 不能建立索引
- 不要把图片存放成 blob,建议存到磁盘上,在数据库里记录位置
枚举
enum 会根据枚举值集合的大小,选择适当的数值存储。
enum 的每个值被存储成按表定义中声明顺序排列的整数:
mysql> CREATE TABLE enum_test(
-> e ENUM('fish', 'apple', 'dog') NOT NULL
-> );
mysql> INSERT INTO enum_test(e) VALUES('fish'), ('dog'), ('apple');
mysql> SELECT e + 0 FROM enum_test;
+-------+
| e + 0 |
+-------+
| 1 |
| 3 |
| 2 |
+-------+
如果要按照字符顺序排序:
mysql> SELECT e FROM enum_test ORDER BY FIELD(e, 'apple', 'dog', 'fish');
+-------+
| e |
+-------+
| apple |
| dog |
| fish |
+-------+
注意事项:
- enum 被存储为数值,相比字符串,更节省存储空间
- enum 和字符串拼接时,会有一个从数值到字符串的转换过程,额外开销明显
- enum 和 enum 的拼接会更快
- enum 被转换成数值存储,但是在字符串上下文中会被转换成字符串
时间
datetime:
- 时间范围广 1000~9999年,精度毫秒,8 字节,日期部分 YYYYMMDDHHMMSS 存储为整数,和时区分开存放
- 跨时区使用时,显示存入的字面时间,不转换
timestamp:
- 1970 年开始的秒数,GMT 时间,精度为秒,4 字节,最多到 2038年1月19日
- 跨时区使用时,显示在当前时区的时间,会转换
注意事项:
- 为了避免 timestamp 的 2038 问题,直接用整数类型存放时间戳,unsigned 32-bit 支持到 2106 年
位
bit 底层使用的是能够容纳它的最小整数类型,和数值类型相比,没有节省空间。
MySQL 默认把 bit 类型的字段值看作字符串。
例如 b’00111001’ 转换成十进制是 57 ,对应 ascii 字符 ‘9’,如果直接读取,MySQL 认为它是字符 ‘9’:
mysql> CREATE TABLE bittest(a bit(8));
mysql> INSERT INTO bittest VALUES(b'00111001');
mysql> SELECT a, a + 0 FROM bittest;
+------+-------+
| a | a + 0 |
+------+-------+
| 9 | 57 |
+------+-------+
如果用于数值运算, b’00111001’ 会被转换成数值 57,bit 的数值行为容易让人困惑,尽量避免使用。
- 如果表示一个Y/N,建议用 tinyint,耗费的存储空间和 bit(1) 相同
- 如果要表示多个Y/N,建议用 Set 或整数(在代码中标记每个位的含义)
Set
用 Set 存放多个 Y/N:
mysql> CREATE TABLE acl (
-> perms SET('CAN_READ', 'CAN_WRITE', 'CAN_DELETE') NOT NULL
-> );
mysql> INSERT INTO acl(perms) VALUES ('CAN_READ,CAN_DELETE');
mysql> SELECT perms FROM acl WHERE FIND_IN_SET('CAN_READ', perms);
+---------------------+
| perms |
+---------------------+
| CAN_READ,CAN_DELETE |
+---------------------+
用整数存放多个 Y/N:
mysql> SET @CAN_READ := 1 << 0,
-> @CAN_WRITE := 1 << 1,
-> @CAN_DELETE := 1 << 2;
mysql> CREATE TABLE acl (
-> perms TINYINT UNSIGNED NOT NULL DEFAULT 0
-> );
mysql> INSERT INTO acl(perms) VALUES(@CAN_READ + @CAN_DELETE);
mysql> SELECT perms FROM acl WHERE perms & @CAN_READ;
+-------+
| perms |
+-------+
| 5 |
+-------+
注意事项:
- Set 方式优点是直观,查询时直接显示实际含义,缺点是增加新值时,要修改字段定义
Json
相比拆分成多个列,json 的存储空间增加,查询开销也小幅增加。
主键的选择
- 设定主键后,其它表引用主键时,一定要用同样的定义,避免额外转换开销或转换错误
- 主键类型占用的空间应尽可能小
- 优先选择整数类型,避免使用字符串
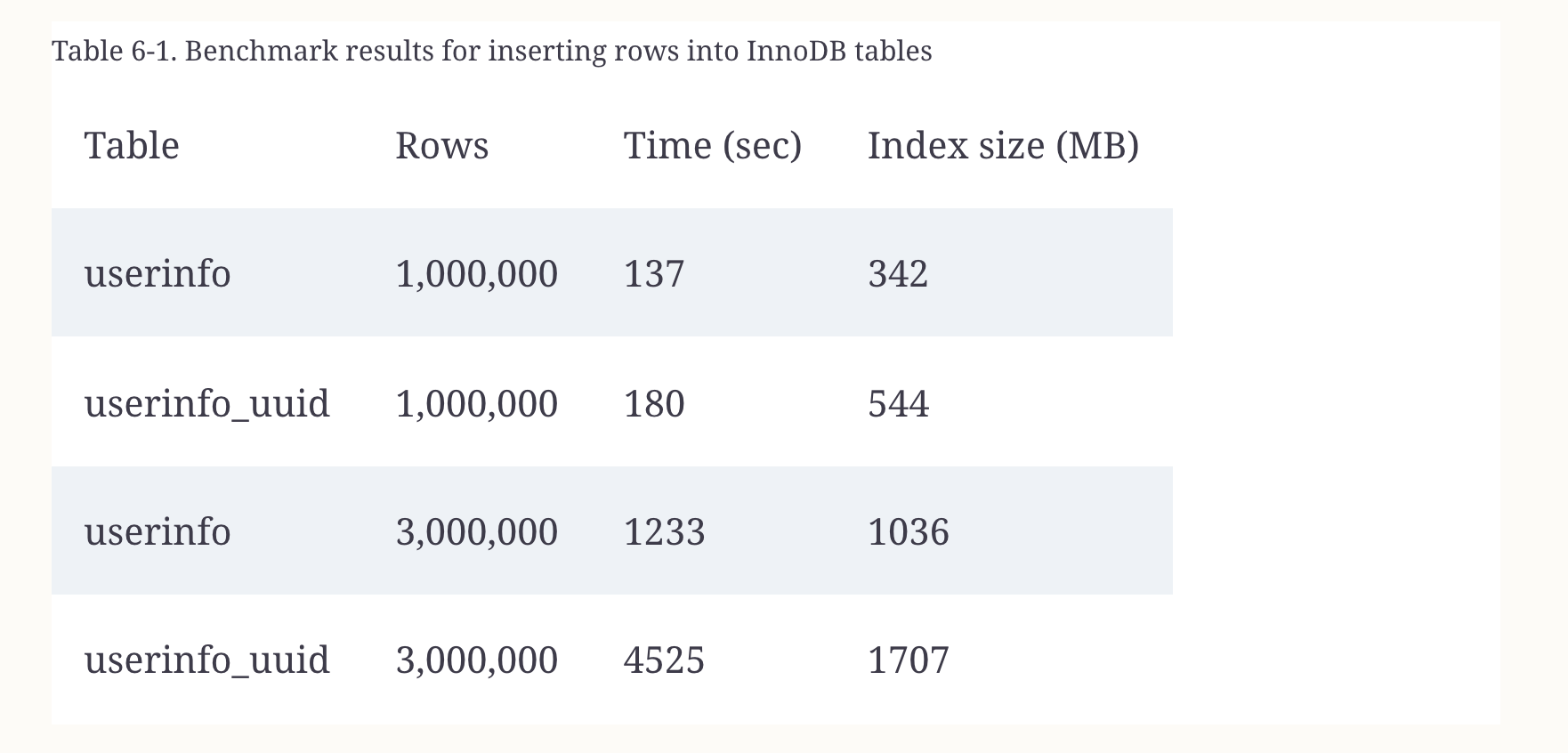
- 避免使用完全随机数,随机会导致数值分布空间大,数值分布不可预测,影响缓存加载,增加插入和查询开销
- 如果要存放UUID,转换成16字节的数字存放
注意事项:
- ORM 以及一些框架自动生成的表定义,很可能使用了不合理的字段类型
其它注意事项
- 表的列数如果有上百行,会带来大量的 cpu 开销,即使只使用几列,innodb 也需要解析所有数据列
- 太多表 join 会成为严重问题,MySQL 设置的上限为 61 张表
Chapter 6. Indexing For High Performance
索引分类:
- B树索引
- 全文索引
MySQL实现的B树索引的限制:
- 不支持非最左匹配场景
- 不能跳过索引中的某一列,索引中的列整体构成 key,不能跳过中间某一个,以右侧的列为索引(还是最左匹配的问题)
索引推荐读物:Relational Database Index Design and the Optimizers, by Tapio Lahdenmaki and Mike Leach (Wiley)
B树索引优点:
- 数值临近的索引,在存储空间上临近,可以为 order by 、 group by 提供优化手段
- 索引中备份了构成给索引的字段值,如果查询请求只需要这些字段,可以避免回表查询整行数据
索引评价三星指标:
- 是否将相关的行临近存放
- 存放顺序是否和查询顺序一致
- 是否包含查询需要的列
索引适合中型表和大型表,如果特别小的表,直接扫表更高效。如果表的规模非常大,索引的额外开销会很高,可以使用分区的方式处理。
提高索引性能的策略
目标索引包含的列在 where 条件中单独呈现,不要加函数处理,或者放在运算表达式中:
mysql> SELECT actor_id FROM actor WHERE actor_id + 1 = 5; -- 不会命中 actor_id 索引
如果区分度足够,没必要使用整个列,可以使用这个列中数值的前缀,以减少索引占用的空间。对于 blog/text,以及过长的 varchar,MySQL 不允许对完整值建索引。
如果发现某个语句使用了 index_merge,需要考虑下索引能不能优化:
mysql> EXPLAIN SELECT film_id, actor_id FROM film_actor
-> WHERE actor_id = 1 OR film_id = 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: index_merge
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY,idx_fk_film_id
key_len: 2,2
ref: NULL
rows: 29
Extra: Using union(PRIMARY,idx_fk_film_id); Using where
TODO: Multicolumn Indexes 这节没有看明白,说是如果为每个列单独建索引,MySQL 可能使用 index_merge 技术,并发过滤多个索引,然后将结果汇和,这个汇和可能非常耗费内存和CPU。
包含多列的索引:
- 如果不考虑排序和 group by,把区分度最高的列放在最左边
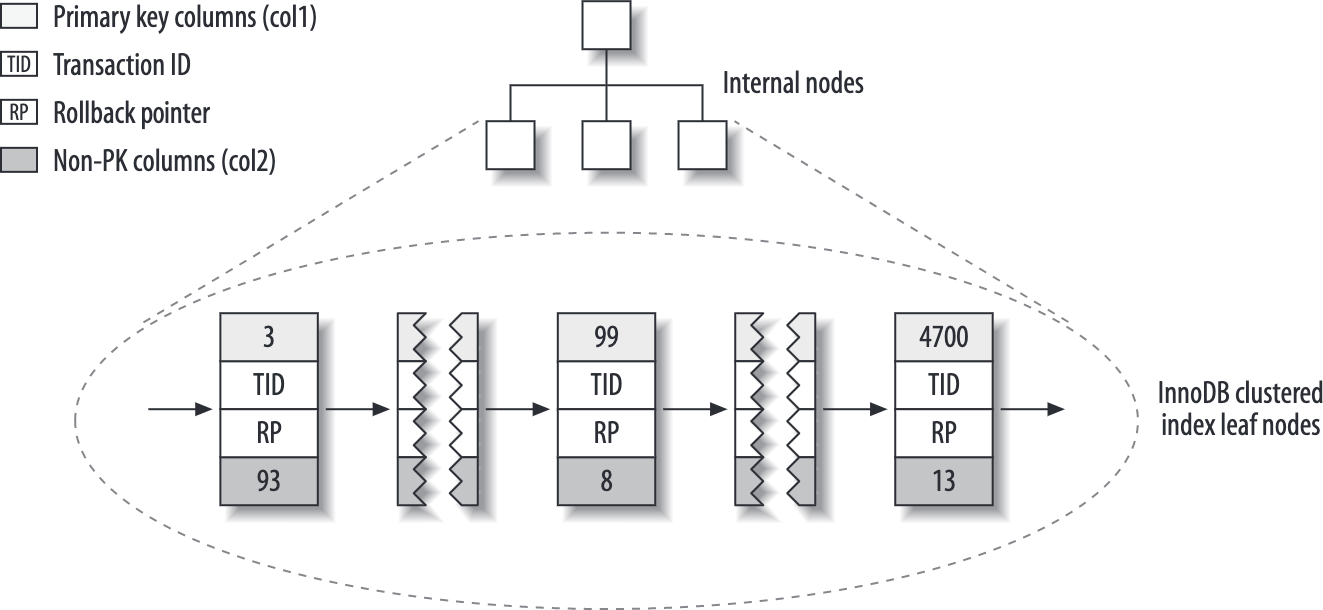
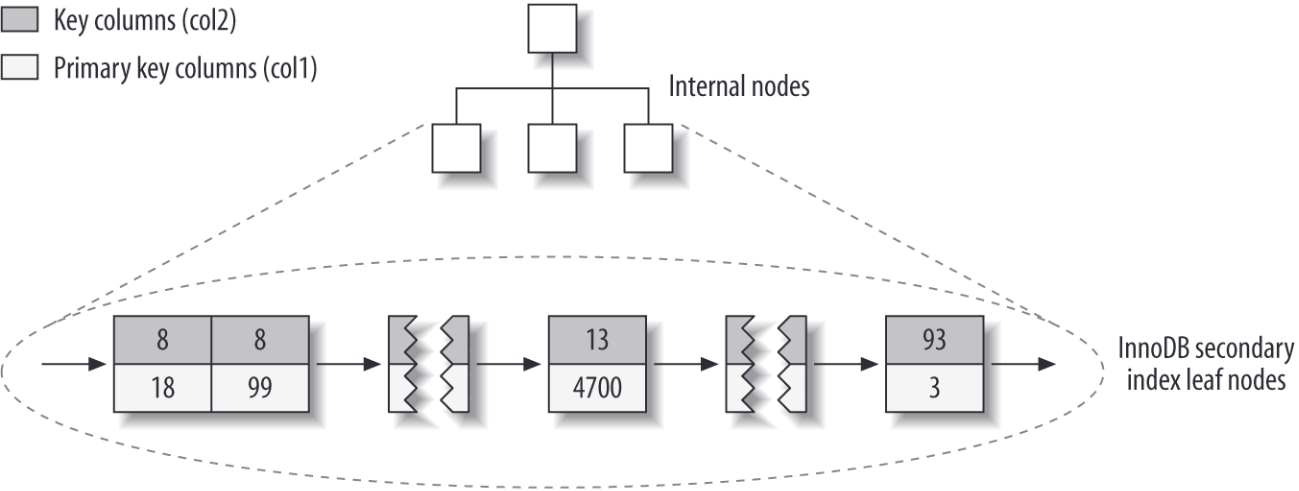
普通索引的叶子节点中存放的是主键数值,不是行的地址,如果主键过大,其它索引开销相应增加。
主键索引/聚簇索引的示意图,叶子节点存放的是完整行:
普通索引的示意图,叶子节点存放的是主键数值:
避免用 uuid 做主键,会导致写入性能大幅下降,uuid 数值随机导致插入时写入位置随机:
用 ANALYZE TABLE 重建索引的统计数值。
Chapter 7. Query Performance Optimization
执行过程与开销度量
MySQL 语句执行过程:
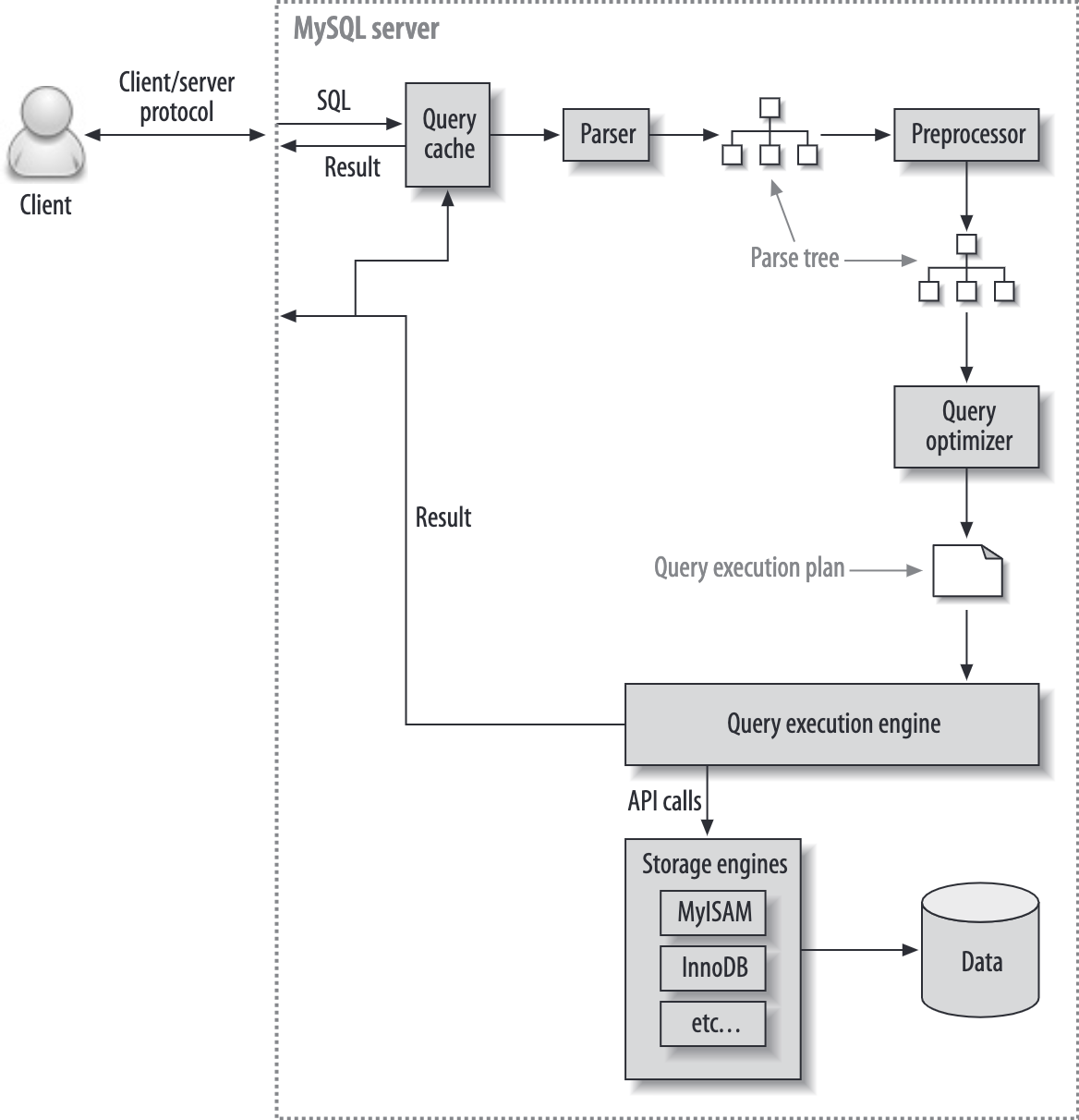
响应时间由两部分组成:
- servcie time:MySQL 真正执行语句的时间
- queue time: 等待执行的时间,IO、锁等各种原因导致的排队
客户端与 MySQL Server 的通信是半双工的,发送方的数据发送过程不会被打断。SQL 语句长度受到 max_allowed_packet 的限制。
MySQL 每找到一条满足条件的数据后,就立即发送给客户端,边找边发送(排序情况除外)。
服务端向客户端发送数据时,语句处于 sending data 状态,不会释放锁以及其它资源。
服务端线程状态:
- sleep;等待客户端的查询语句
- query:正在执行查询或者返回数据中
- locked:等待服务端实现的表锁
- analyzing and statistics:分析存储引擎的统计数据,进行查询优化
- coping to tmp table [on disk]:数据拷贝到零时表中
- sorting result:结果排序
- sending data
上一条语句的执行开销记录在当前会话的 Last_query_cost 变量中,意思是执行了多少次数据页面随机读取动作( 这是实际代价,和 explain 语句中的估计代价不同):
mysql> show status like 'Last_query_cost';;
+-----------------+--------------+
| Variable_name | Value |
+-----------------+--------------+
| Last_query_cost | 20276.199000 |
+-----------------+--------------+
1 row in set (0.00 sec)
导致 SQL 执行慢的原因:
- 获取了过多的行、以及过多的列
- 扫描太多的行才找到匹配的数据
MySQL访问数据方式由快到慢:
- constants
- unique index lookups
- range scans
- index scans
- full table scans
where 语句有三个作用位置:
- 作用于存储引擎查询:查询存储引擎时直接排除不需要的数据
- 作用于索引字段排除:使用了 covering index 时,排除索引中不需要的字段
- 作用于 MySQL Server: 对从存储引擎中取出的数据进一步过滤
如果 MySQL 检查的数据行数,远远大于最终查找到的行数,尝试用以下几种优化方式:
- 使用 covering indexes,减少回表
- 重新设计表,譬如针对数据聚合场景,设计里一个专用的 Summary 表
- 重构查询语句,让 MySQL 能够有效优化
查询语句的重构思路主要有以下几个:
- 单条复杂语句与多条语句的权衡: 相比数据读取,网络延迟更大,如果可能,减少查询是一个好的策略。
- 分治处理:譬如要检索全表删除一部分数据,可以每万条执行一次。
- join 语句拆解:把一个 join 语句拆成多个独立语句,相应数据处理放在应用层实现。
优化器与语句
优化器的两个基本的优化方法:
- static 静态优化:通过分析 sql 语句解析出来 parse tree,静态计算 where 语句开销,与查询语句中的数值无关
- dynamic 动态优化:根据 where 语句中的数值、数据行数、索引情况等「变动的数据」估算代价,进行语句优化
MySQLserver 不记录数据的的统计数值,统计数值由存储引擎维护。
优化器未选出实际最优方案的原因:
- 受到事务/mvcc等影响,优化器使用的统计数据错误(没有更新到准确数值)
- 估计的执行代价和实际执行代价不同,MySQL 优化器不假定数据在缓存中,全部按磁盘读取估计代价
- 优化器的优化策略是代价尽可能小,而不是尽可能快
- 优化器不考虑并行的其它语句可能带来的改善(譬如缓存)
- 优化器有些固化的规则,导致没有选出最优方案。譬如如果存在 match,无脑选择 fulltext 索引
- 优化器不考虑不再掌控范围内的操作代价,譬如sql中使用的自定义函数、存储过程函数
- 优化器不会评估所有的执行计划,可能漏掉了最佳方案
优化器能够识别的优化项目:
- reordering join:join 语句重排,优化器能够判断出最佳的 join 顺序
- couverting out joins to inner joins:转换成等价的 inner join
- Applying algebraic equivalence rules:譬如 5=5 and a>5 会被转换成等价的 a>5
- count(), min(), and max() optimizations:利用B树索引特点,直接从第一个/最后一个位置取出最小/最大值
- Evaluating and reducing constant expressions:直接把结果为常量的表达式计算成常量
优化时发现条件不可能满足,直接终止:
mysql> EXPLAIN SELECT film.film_id FROM film WHERE film_id = −1;
+----+...+-----------------------------------------------------+
| id |...| Extra |
+----+...+-----------------------------------------------------+
| 1 |...| Impossible WHERE noticed after reading const tables |
+----+...+-----------------------------------------------------+
结果排序过程
MySQL 不能直接获取到有序的结果(除非是按照有索引的列排序),通常需要执行专门的排序操作。无论是内存中排序还是利用磁盘 文件排序,在 MySQL 中统一称为 filesort,选用的排序算法是快排。
排序时,以行的最大可能长度为单位申请内存,使用 varchar 时要特别小心:
- 如果使用了 varchar,采用 varchar 的最大长度
- 如果使用了 utf-8,每个字符默认占用 3 字节
如果 order by 使用了非第一个表中的列,MySQL 将结果存放在临时表,然后在临时表上排序,explain 中显示 Using temporary; Using filesort。
limit 作用于排序后的结果,不能减少排序开销。
in 语句特点
MySQL 把 in 语句中的多个数值构建成一个二叉搜索树,实现 O(logn) 的时间复杂度。有些数据库选用等价于 or 语句的方案,时间复杂度为 O(n)。
优化时,如果发现一个查询任务的 in() 列表,适用于另一个查询任务,优化器会将 in() 条件加入另一个查询任务中。如果 in() 列表过大,反而会导致整体变慢。
最重要的 join 优化
MySQL将每条语句都当作 join 语句处理,或者说会把众多语句都归化为 join 场景,单表查询被看作是一个特殊的 join,因此 join 优化是最重要的优化。
MySQL 执行的 join 的过程: 从一张表中找到一条符合条件的记录后,立即转入下一个表寻找符合条件的记录,如果没找到回退到上一张表,如果所有表中符合条件的行都找到了,提取每个表中的相关的列组成一条结果。 把各种类型的 join 都转换 left outer join / inner join 场景,不支持 full outer join。
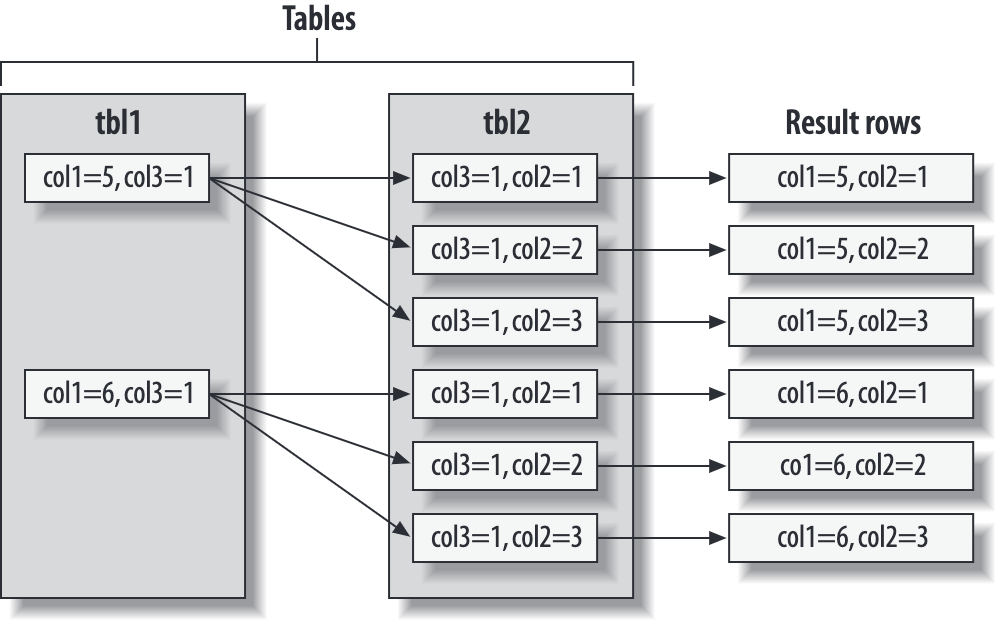
MySQL 的 join 实现方法导致执行计划是一棵向左倾斜的树:
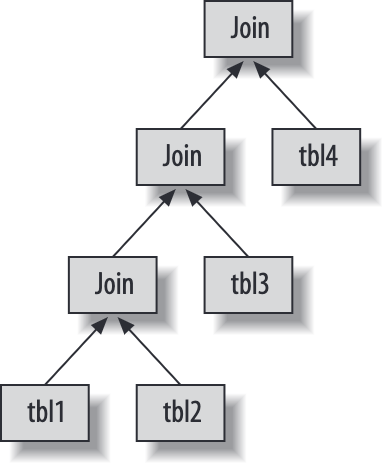
join 优化中最重要的一项是通过调整表的顺序,即通过调整驱动表,用更小的代价得到同样的结果。
注意:如果表的数量过多,排列组合的总数会指数式增加,MySQL 不会评估所有组合,表的数量超过 optimizer_search_depth 时,使用贪心策略寻找较优方案,因此
可能漏掉最优方案。
另外,MySQL 会根据表中数据以及查询语句特点,提前结束或者缩小数据遍历范围。
file.file_id = 1 的记录只有一条时,对应的 ref 类型为 const:
mysql> EXPLAIN SELECT film.film_id, film_actor.actor_id
-> FROM film
-> INNER JOIN film_actor USING(film_id)
-> WHERE film.film_id = 1;
+----+-------------+------------+-------+----------------+-------+------+
| id | select_type | table | type | key | ref | rows |
+----+-------------+------------+-------+----------------+-------+------+
| 1 | SIMPLE | film | const | PRIMARY | const | 1 |
| 1 | SIMPLE | film_actor | ref | idx_fk_film_id | const | 10 |
+----+-------------+------------+-------+----------------+-------+------+
对于一个 film_id 只要在 file_actor 表中找到一条对应记录,就排除它,不再检查 file_actor 表中的其它数据:
mysql> SELECT film.film_id
-> FROM film
-> LEFT OUTER JOIN film_actor USING(film_id)
-> WHERE film_actor.film_id IS NULL;
MySQL 会识别出 film_id > 500 也适用于 film_actor,限制 对 film_actor 表的扫描范围:
mysql> SELECT film.film_id
-> FROM film
-> INNER JOIN film_actor USING(film_id)
-> WHERE film.film_id > 500;
优化器的局限
MySQL 的 join 优化机制,有一些不适应的场景,需要避免使用一些语句用法。
关联子查询缺陷
如果在 in 中使用关联子查询(correlated subqueries), MySQL 的优化结果会很差,例如:
mysql> SELECT * FROM film
-> WHERE film_id IN(
-> SELECT film_id FROM film_actor WHERE actor_id = 1);
MySQL 将其优化成类似下面的语句:
SELECT * FROM film
WHERE EXISTS (
SELECT * FROM film_actor WHERE actor_id = 1
AND film_actor.film_id = film.film_id);
它没有取出有限的 film_id 作为约束,而是对 film 进行全表扫描,判断每行数据是否满足约束:
mysql> EXPLAIN SELECT * FROM film ...;
+----+--------------------+------------+--------+------------------------+
| id | select_type | table | type | possible_keys |
+----+--------------------+------------+--------+------------------------+
| 1 | PRIMARY | film | ALL | NULL |
| 2 | DEPENDENT SUBQUERY | film_actor | eq_ref | PRIMARY,idx_fk_film_id |
+----+--------------------+------------+--------+------------------------+
改进方法一:用 exists 语句代替 in,等价效果的 exists 语句通常好于 in。(书中未说明原因 TODO)
mysql> SELECT * FROM film
-> WHERE EXISTS(
-> SELECT * FROM film_actor WHERE actor_id = 1
-> AND film_actor.film_id = film.film_id);
改进方法二:用 join 语句替换子查询,MySQL 选择则符合条件的数据量更少的 film_actor 表做驱动表。
mysql> SELECT film.* FROM film
-> INNER JOIN film_actor USING(film_id)
-> WHERE actor_id = 1;
改进方法三:拆成两条语句,先查出 film_id,第二条语句的 in 中直接填入 id,这种方式会比较 join 快。
mysql> SELECT film_id FROM film_actor WHERE actor_id = 1);
mysql> SELECT * FROM film WHERE film_id IN(XXX)
需要注意,并非所有 join 语句都比使用子查询高效,例如下面的 join 语句:
mysql> SELECT DISTINCT film.film_id FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id);
用 join 语句会把一个 film_id 能够关联的行全部生成,再执行去重动作。
实际并不需要生成所有行,只要找到一个关联行就可以确定当前 film_id 在结果中,子查询更高效:
mysql> SELECT film_id FROM sakila.film
-> WHERE EXISTS(SELECT * FROM sakila.film_actor
-> WHERE film.film_id = film_actor.film_id);
使用 join 语句时,要注意以下事项:
- 用于连接的列上有索引
- group by 和 order by 使用的列位于一张表,使 MySQL 能够选出可用的索引
- 不同版本的 MySQL 的 join 行为可能不同,升级版本时要特别注意
union 语句缺陷
union 中的限制条件不会被用于子语句。
下面的语句会把 actor 和 customer 两张表的所有数据全部导入到临时表中 ,然后从临时表中取 20 行:
(SELECT first_name, last_name
FROM sakila.actor
ORDER BY last_name)
UNION ALL
(SELECT first_name, last_name
FROM sakila.customer
ORDER BY last_name)
LIMIT 20;
改成下面的方式可以避免两张表的全量数据排序(但是结果会有变化,需要根据实际情况决定):
(SELECT first_name, last_name
FROM sakila.actor
ORDER BY last_name
LIMIT 20)
UNION ALL
(SELECT first_name, last_name
FROM sakila.customer
ORDER BY last_name
LIMIT 20)
LIMIT 20;
使用 union 还需要注意,
- MySQL 默认对 union 的结果进行排序,如果不需要排序,使用
union all
Index Merge 缺陷
当 where 后面的条件比较复杂时,用一个表的多个索引分别查出多个结果,然后对多个结果集合进行集合运算得出最终结果,这个特性叫做 Index Merge。
但是 MySQL 不支持在多个 cpu 上并发执行一个会话线程,index merge 中的多个索引独立查询是串行的。
另外 MySQL 不支持通用的稀疏索引(只在个别 group by 场景有一定支持),需要明确建立更多索引。
例如语句 SELECT ... FROM tbl WHERE b BETWEEN 2 AND 3;,如果支持稀疏索引,在不为 b 建索引的情况下,先对 a=1 的行对应对 b 列快速查找(稀疏索引应该自动实现 b 列上索引),查找完后 a=1 的行后,再从 a=2 处重复上述动作。
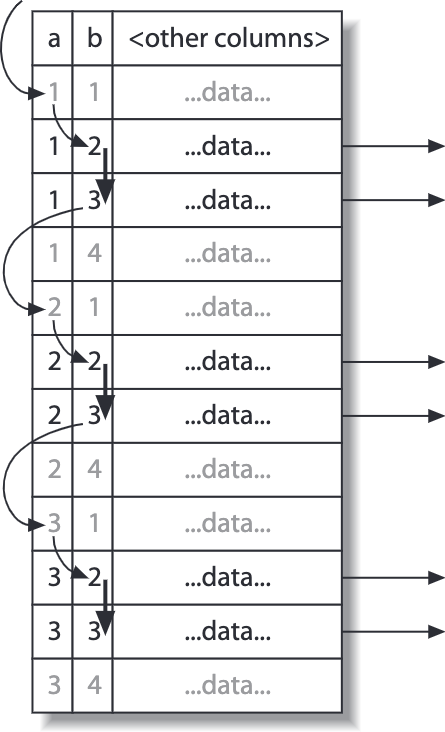
禁止同时读写
MySQL 不允许一个 sql 语句同时读写同一张表:
mysql> UPDATE tbl AS outer_tbl
-> SET cnt = (
-> SELECT count(*) FROM tbl AS inner_tbl
-> WHERE inner_tbl.type = outer_tbl.type
-> );
ERROR 1093 (HY000): You can't specify target table 'outer_tbl' for update in FROM
clause
常用技巧与注意事项
利用索引特性找最大/最小值
first_name 上没有索引,actor_id 是有索引, actor_id 是已经排好顺序的。
如果用下面的写法,MySQL 需要对全表进行扫描,找出所有 first_name = ‘PENELOPE’ 的列 ,然后取 actor_id 的最小值:
mysql> SELECT MIN(actor_id) FROM sakila.actor WHERE first_name = 'PENELOPE';
利用 actor_id 已经有序的特性,写出更高效的语句,找出 first_name = ‘PENELOPE’ 的第一个记录:
mysql> SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
-> WHERE first_name = 'PENELOPE' LIMIT 1;
这种写法的问题是,语句含义不直观,表面看是查找满足条件的第一行数据,实际目的是找 min(actor_id)。
用 count() 统计记录数
count() 函数有两个工作场景:
- count(列名):统计列中非 NULL 的数值数量,注意是不去重的数值数量,等同于有数值的行数
- count(*):统计行数
以下表中的数据为例:
mysql> select * from scores;
+----+---------+-----------+-------+---------------------+---------------------+
| id | name | home | score | create_at | update_at |
+----+---------+-----------+-------+---------------------+---------------------+
| 1 | 小明 | NULL | 104 | 2021-01-01 00:00:00 | 2021-09-23 17:14:57 |
| 2 | 小明 | NULL | 100 | 2021-01-02 00:00:00 | 2021-08-10 18:19:25 |
| 3 | 小红 | NULL | 20 | 2021-11-02 18:37:00 | 2021-11-02 18:37:00 |
| 4 | 小红 | NULL | 98 | 2021-02-01 00:00:00 | 2021-08-10 18:19:25 |
| 5 | 小王 | NULL | 10 | 2021-09-01 14:01:33 | 2021-09-01 14:01:33 |
| 6 | 小王 | NULL | 11 | 2021-09-01 14:02:58 | 2021-09-01 14:02:58 |
| 7 | 王二 | 黑龙江 | 0 | 2021-09-24 16:01:58 | 2021-11-02 19:35:09 |
| 8 | wanger | 黑龙江 | 0 | 2021-09-24 16:08:31 | 2021-09-24 16:08:31 |
| 9 | wanger2 | NULL | 0 | 2021-09-24 16:16:59 | 2021-09-24 16:16:59 |
+----+---------+-----------+-------+---------------------+---------------------+
count(home) 的结果是 2,两个「黑龙江」,排除了 NULL:
mysql> select count(home) from scores;
+-------------+
| count(home) |
+-------------+
| 2 |
+-------------+
1 row in set (0.00 sec)
count(*) 的结果是表的行数:
mysql> select count(*) from scores;
+----------+
| count(*) |
+----------+
| 9 |
+----------+
1 row in set (0.00 sec)
可以用一个语句同时计算出一个列中不同数值出现的次数。
方法1:用 count(col) 实现,非关心的数值标记为 NULL
mysql> select count(name='小明' or NULL),count(name='王二' or NULL) from scores;
+------------------------------+------------------------------+
| count(name='小明' or NULL) | count(name='王二' or NULL) |
+------------------------------+------------------------------+
| 2 | 1 |
+------------------------------+------------------------------+
方法2:用 sum() 实现,非关心的数值累加 0
mysql> select sum(if(name='小明',1,0)) ,sum(if(name='王二',1,0)) from scores;
+----------------------------+----------------------------+
| sum(if(name='小明',1,0)) | sum(if(name='王二',1,0)) |
+----------------------------+----------------------------+
| 2 | 1 |
+----------------------------+----------------------------+
count() 计算的是精确数量,需要把所有数据查出后才能获得。
如果对精确性要求低,可以直接使用 explain 估计的行数:
mysql> explain select * from scores;
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | scores | ALL | NULL | NULL | NULL | NULL | 7 | |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
group by 和 distinct 注意事项
group by 和 distinct 的内部实现类似,优化的时候经常彼此转换,主要优化方式:
- 使用的聚集列上要有索引
- 需要读取非聚集列,建议在 SQL_MODE 中添加 ONLY_FULL_GROUP_BY,在读取非聚集列时报错
- 如果不需要排序,用 order by null 取消,MySQL 默认 group by 的结果排序
- 不要在语句中使用 with rollup,把汇总操作放在应用层实现
group by 使用的列上没有索引时,MySQL 要使用临时表或者 filesort 处理。
with rollup 说明:将 group by 的分组聚合数值累加后作为最后一列。
mysql> select coalesce(name,'合计') name,sum(score) from scores group by name with rollup;
+---------+------------+
| name | sum(score) |
+---------+------------+
| 王二 | 0 |
| wanger | 0 |
| wanger2 | 0 |
| 小王 | 21 |
| 小红 | 118 |
| 小明 | 204 |
| 合计 | 343 |
+---------+------------+
7 rows in set, 1 warning (0.01 sec)
limit 优化
常规的 limit 写法会检索 offset+limit 条数据,如果 offset 非常大,会导致检索大量数据。
下面的语句检索 55 条数据后,抛弃前 50 行:
mysql> SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;
优化方法1:用 join 语句减少列数据读取。
子查询中先完成排序,获得要输出的 film_id,这一步只读取 film_id,不读取其它列,film_id 要有索引,利用 covering index 避免回表。 然后 MySQL 使用子查询生成的表作为驱动表,只扫描 5 个 film_id 对应的行:
mysql> SELECT film.film_id, film.description
-> FROM sakila.film
-> INNER JOIN (
-> SELECT film_id FROM sakila.film
-> ORDER BY title LIMIT 50, 5
-> ) AS lim USING(film_id);
优化方法2:使用游标。
mysql> SELECT * FROM sakila.rental
-> WHERE rental_id < 16030
-> ORDER BY rental_id DESC LIMIT 20;
不要使用 SQL_CALC_FOUND_ROWS,SQL_CALC_FOUND_ROWS 是把所有行都查出来再统计数值:
mysql> select SQL_CALC_FOUND_ROWS * from scores limit 2,2;
+----+--------+------+-------+---------------------+---------------------+
| id | name | home | score | create_at | update_at |
+----+--------+------+-------+---------------------+---------------------+
| 3 | 小红 | NULL | 20 | 2021-11-02 18:37:00 | 2021-11-02 18:37:00 |
| 4 | 小红 | NULL | 98 | 2021-02-01 00:00:00 | 2021-08-10 18:19:25 |
+----+--------+------+-------+---------------------+---------------------+
2 rows in set (0.00 sec)
mysql> SELECT FOUND_ROWS();
+--------------+
| FOUND_ROWS() |
+--------------+
| 9 | <-- 把所有数据都查出后统计的数字
+--------------+
1 row in set (0.01 sec)
如果要获取数据总行数:
- 用 explain 获取估计数值(google 搜索结果中的数量就是估计数值)
- 用 count(*) 单独查出来
Chapter 8. Scaling MySQL
略
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文