数据仓库解惑: 零基础入门(一)
本篇目录
说明
从零开始学习数据仓库,经过连续多天的资料翻阅、看书看视频以及公开案例研究,总算搞清楚了数据仓库是干嘛的,以及要怎么建设。
文中引用的视频来自 youtube,需要翻qiang观看。
为什么要有数据仓库?
以前是因为吧啦吧啦各种各样我们现在已经不关心的原因,现在,数据仓库的目的是把分散在各处 ER 模型中的数据重新抽出来,按照 维度模型 重新整理。
youtube 上的 Bobbie Wang 小姐姐把这个问题讲的特别明白(视频翻墙):
下面是一个非常简单的 ER 模型,现在请面对这张图,用 sql 语句制作一张报表出来:
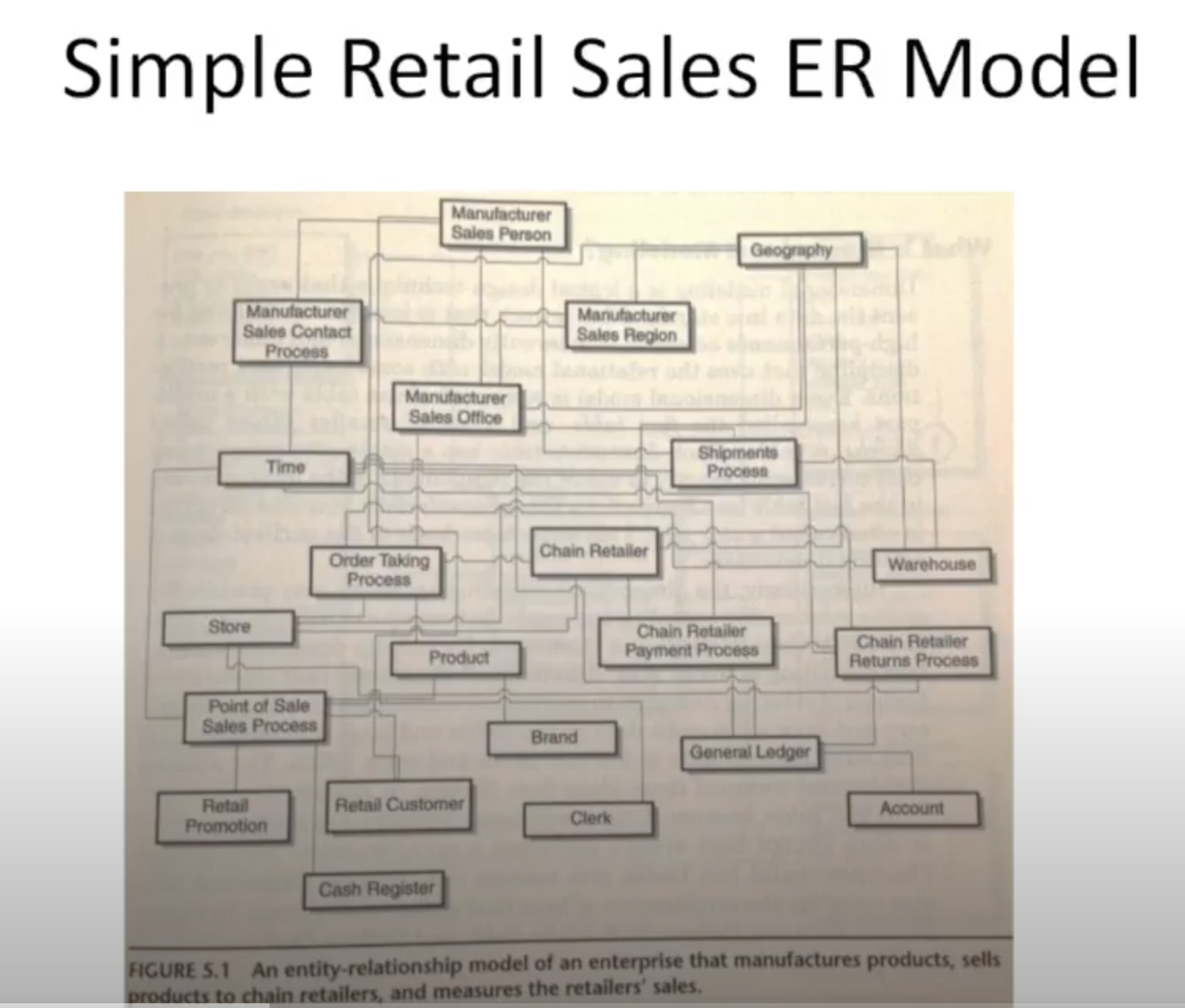
在 ER 模型中,做报表的同学为了完成「出报表」这件小事,硬是把自己逼成了 SQL 专家,从几十上百个表中抽取需要的表,然后各种 join、group by,当然还有其它吧啦吧啦各种不便…
用维度模型(Dimensional Modeling) 重新整理后,出报表就简单了,整个系统中只有两种类型的表:事实表和维度表。后来为了进一步提高查询效率,又在事实表和维度表上堆砌了「宽表」等各种形态的表。
总之,以后出报表很方便了,下面是有赞的实现:
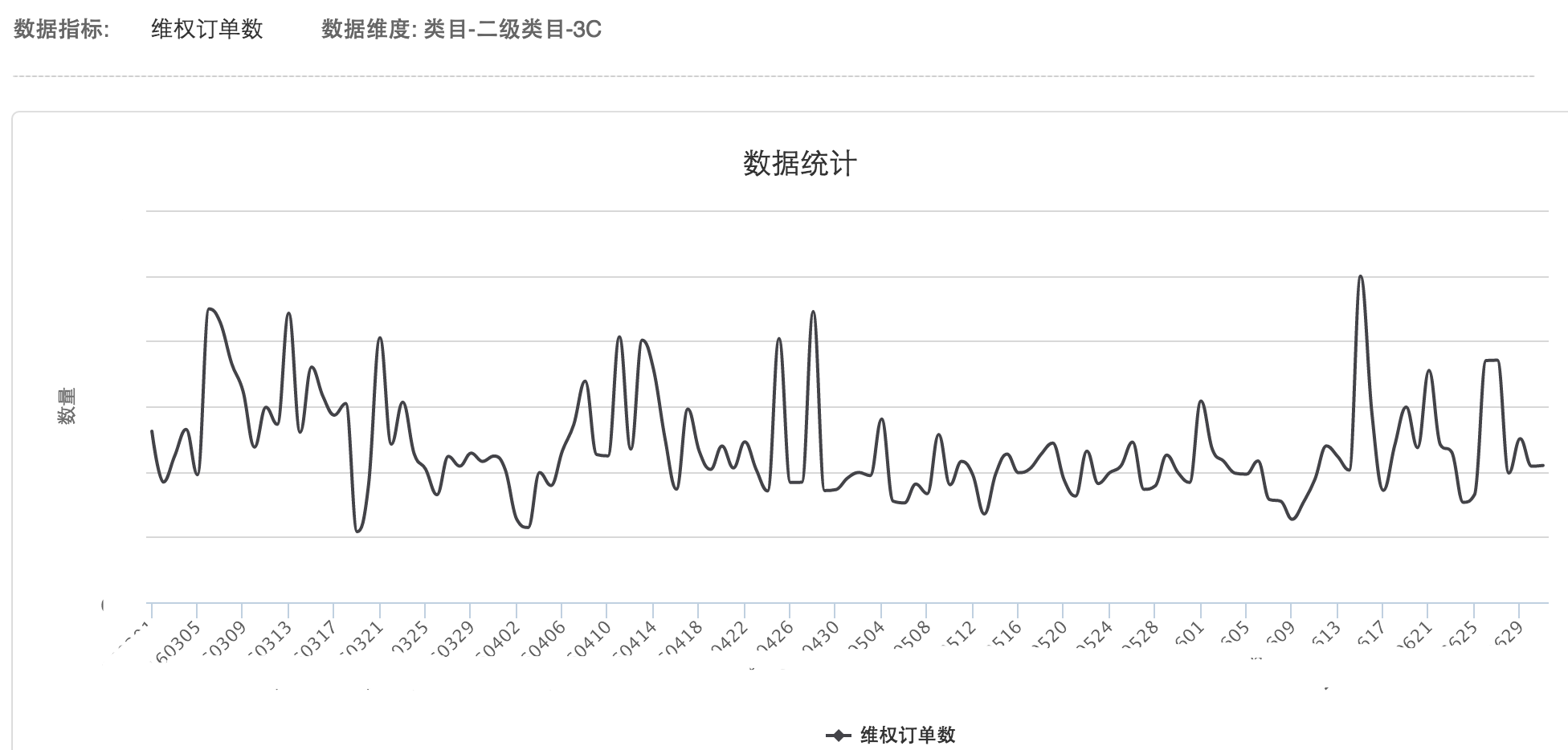
3C类目下的维权订单数的历史趋势:
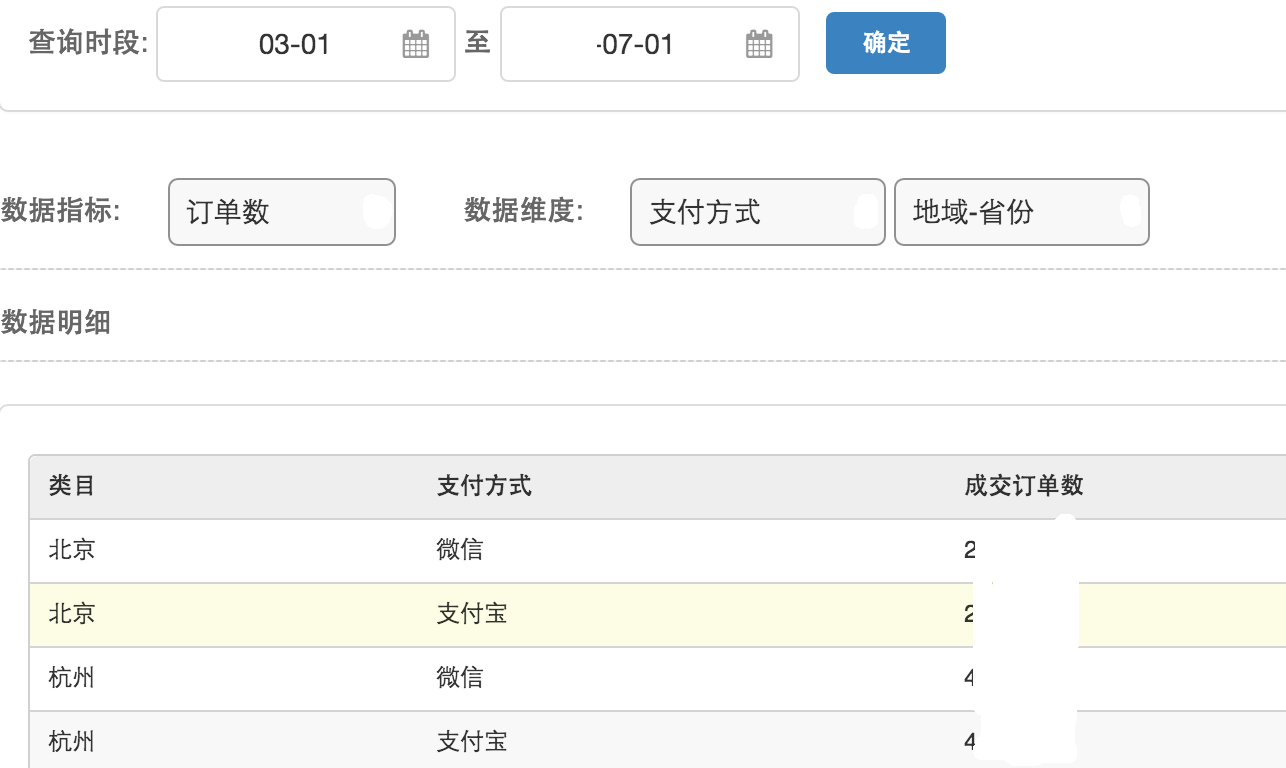
3~7月份,不同地区、不同支付方式 的订单数:
- 搜索分析系统:基于对于纬度建立索引的查询系统
根据销量和维权数维度筛选出A(优质)/B(精品)/C(劣质)类商品,在 A 类中继续根据其它属性筛选。
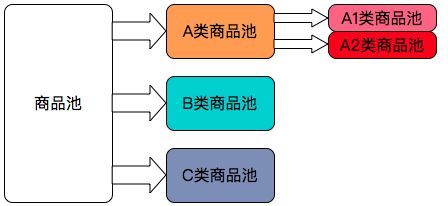
- 固定报表系统:特定数据需求
GMV报表、店铺报表、每周订单数等
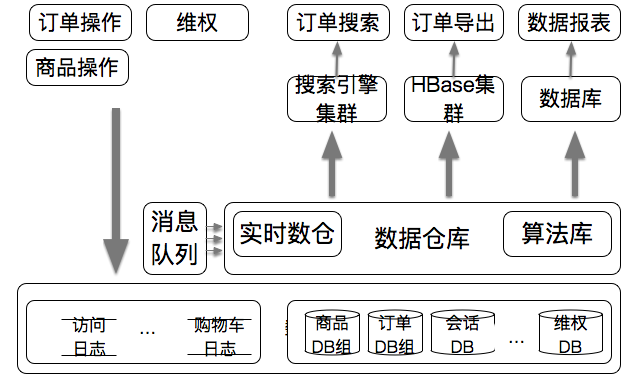
数据仓库充当业务数据层,以数据仓库为中心的架构:
维度模型中的事实表和维度表
维度模型分为星型模型和雪花模型,星型模型和雪花模型中的表都是事实表和维度表。
雪花模型是星型模型的进一步层次化,表现为一个维度表会连接其它维度表。
我认为一般情况下星型模型足够了。
事实表由 维度的ID 和 度量值 组成:
id dim1 dim2 dim3 ... measure1 meaure2...
维度表由维度属性组成,维度属性可以是有层次的:
level1id level1name 属性...
level2id level2name 属性...
...
例如: 国家、省、地级市、县级市、镇、村
事实表建成之后,永远都是追加记录,不会更改也不会删除。
维度表的属性是可以更新的,但怎么更新是一个大问题。维度属性更新问题叫做缓慢变化维,已知有三种处理方式:
- 直接 update,「旧属性值」彻底丢失不可以找回
- 新增一条使用「新属性值」记录,新记录与老记录有各自的有效时间,在事实表中引用维度表的代理码
- 在维度表中添加字段,用多个字段记录变化,譬如,当前城市、以往城市。
参考:缓慢变化维的处理
数据仓库的构建过程
我认为数据仓库的构建过程可以非常粗暴分成两个步骤:
- 分析业务数据,确定数据模型,把事实表和维度表定下来
- 搭建存储系统,把数据存下来并提供各种各样的查询方式
第一个步骤是方法论主导的分析过程 ,第二个步骤是在技术能力制约下的建设过程。
第一个步骤的产出:
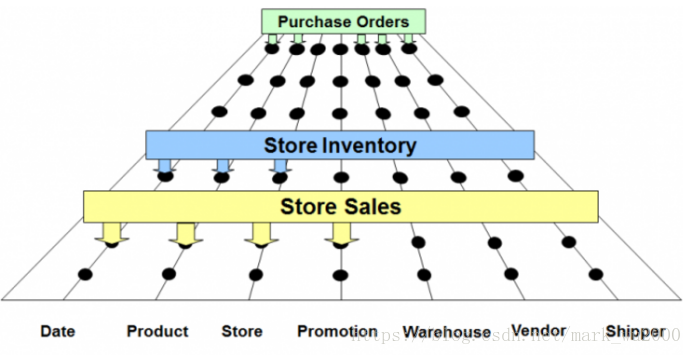
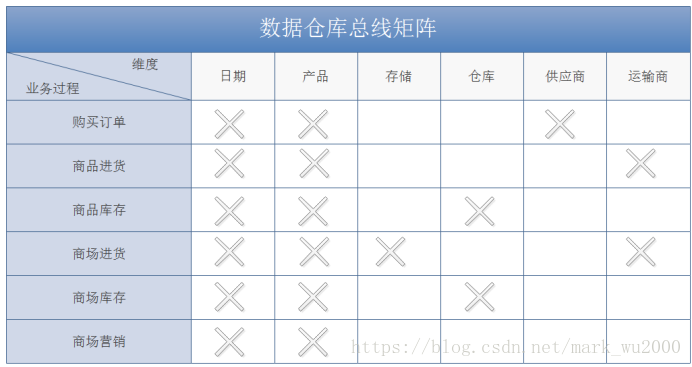
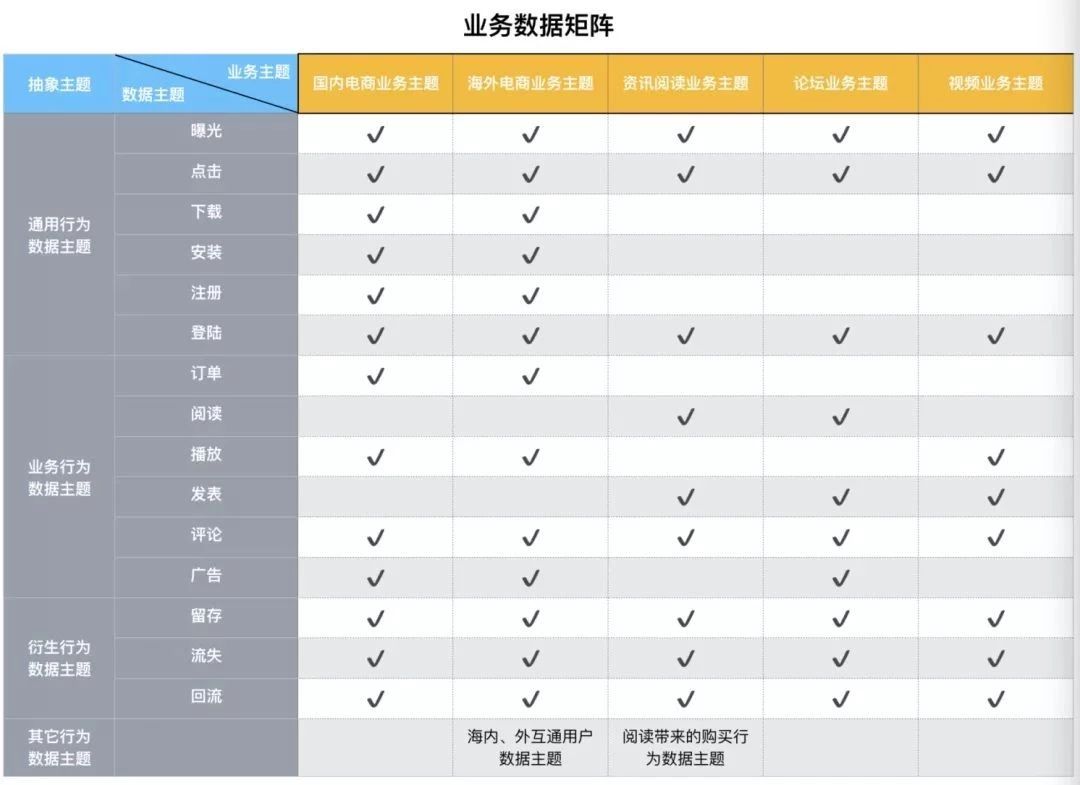
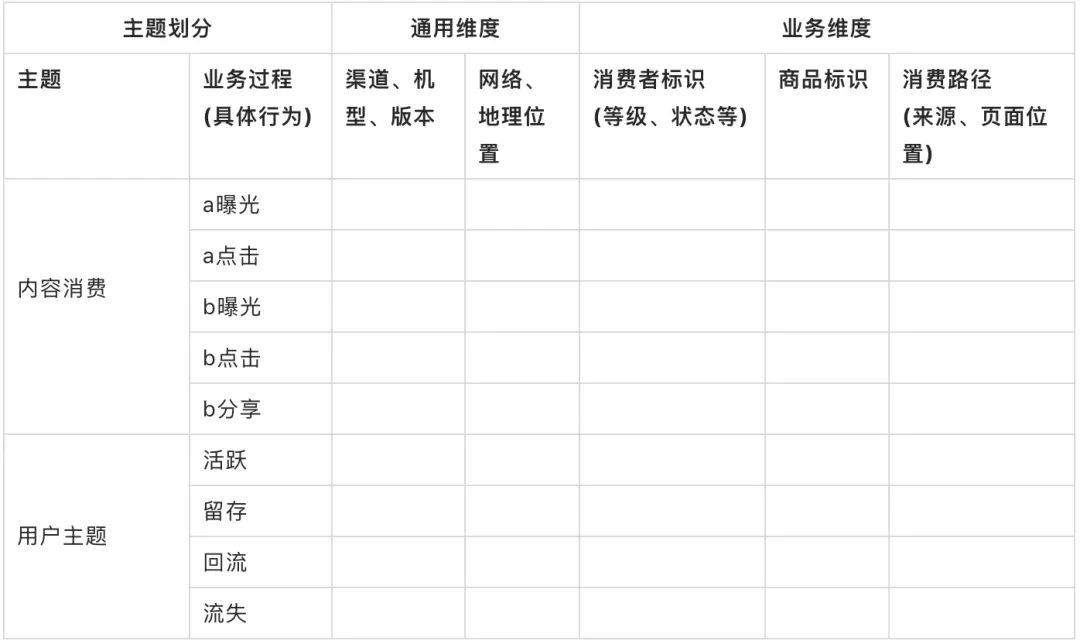
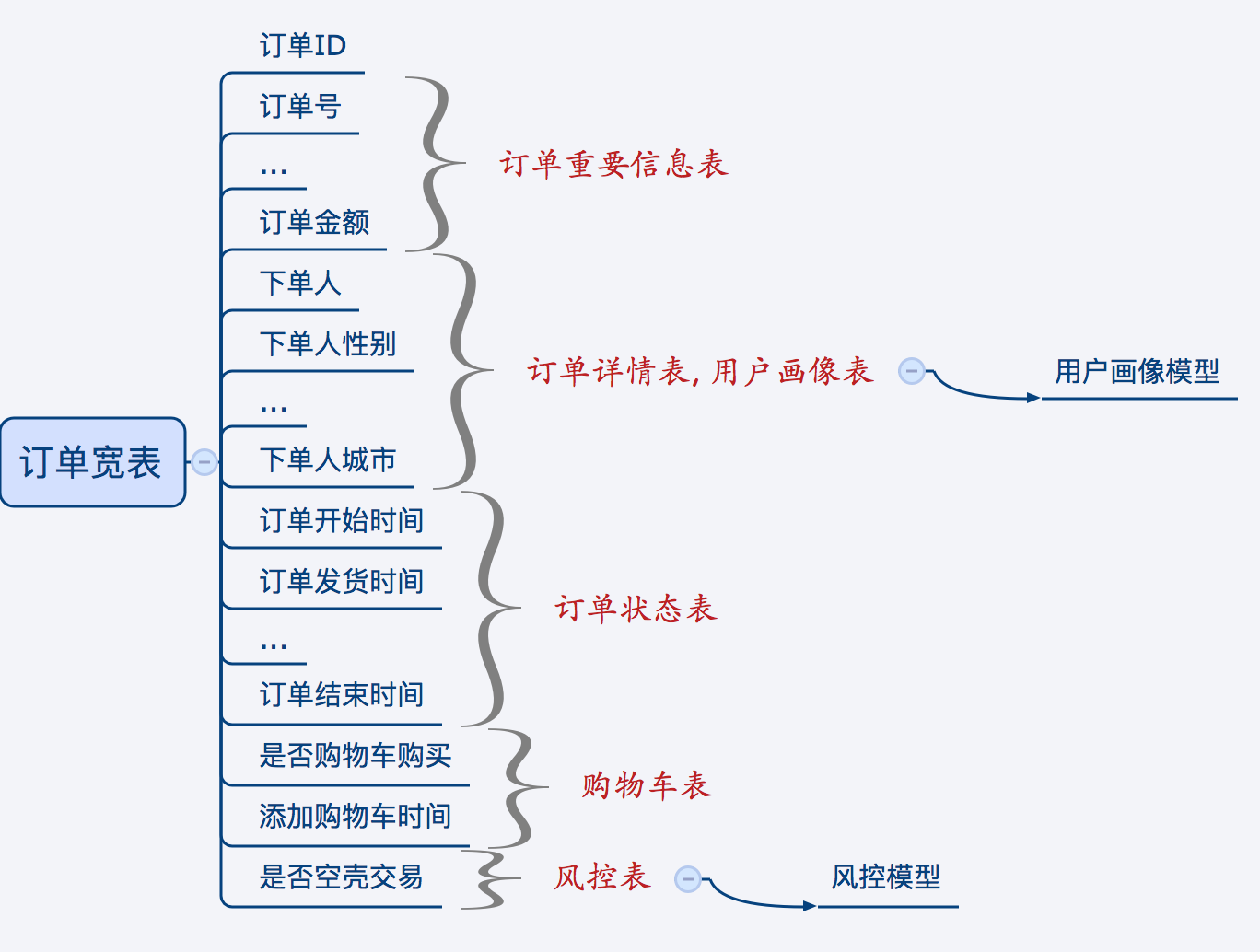
第二个步骤的产出:
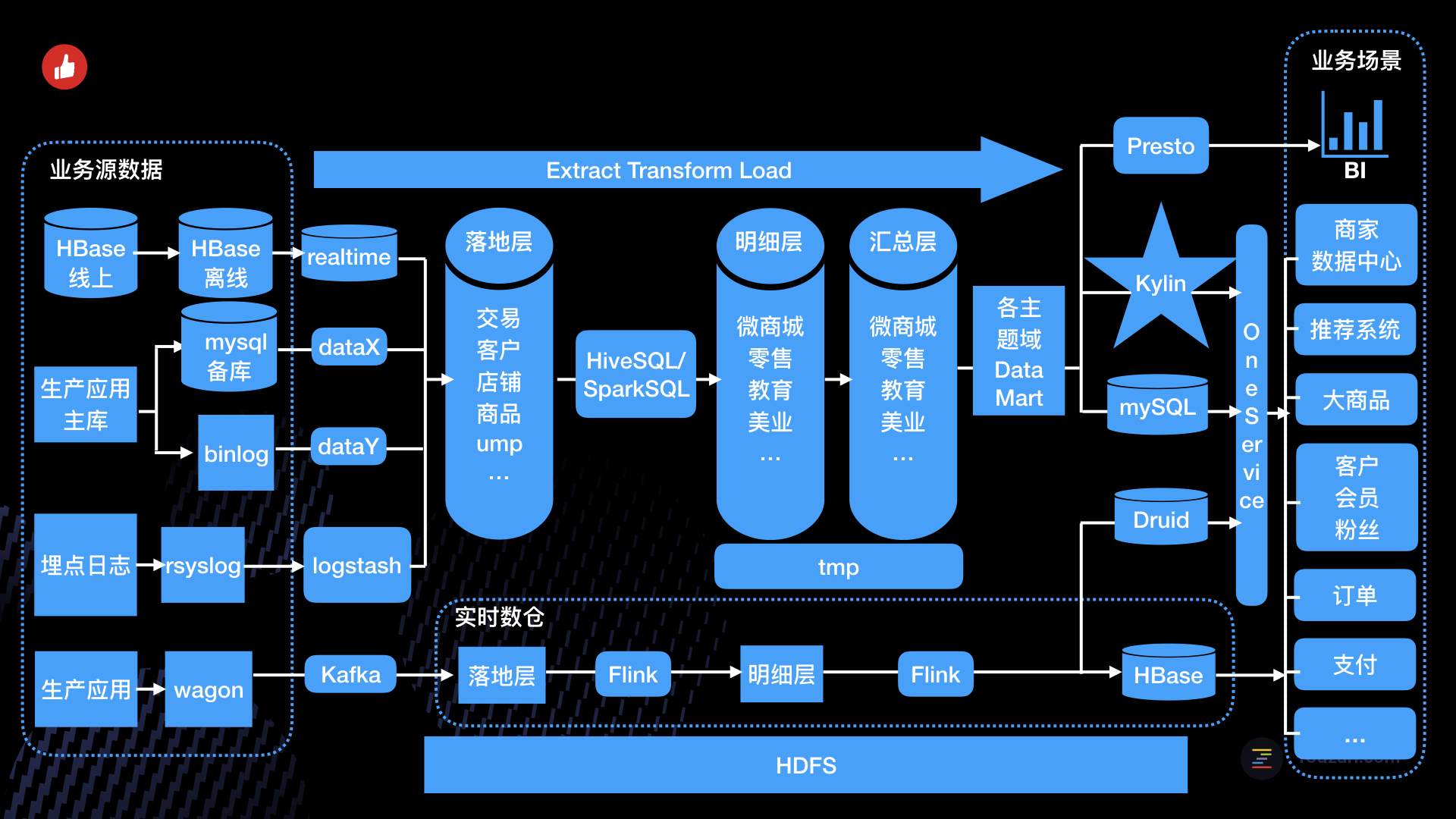
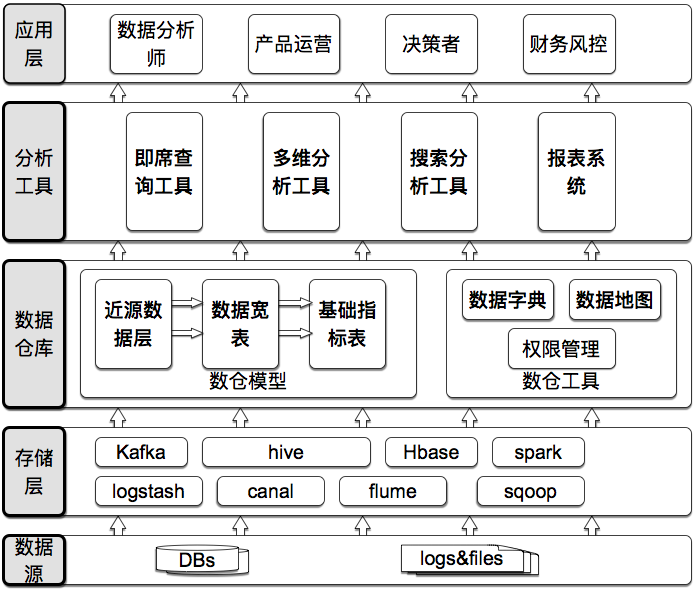
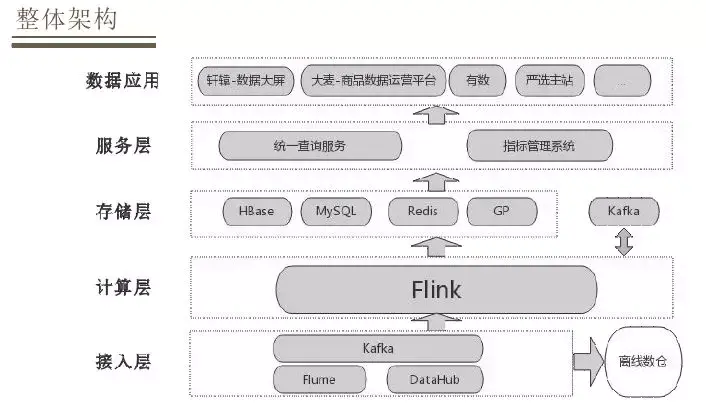
数据仓库构建思想流派
数据仓库构建思想有两大流派:
- Bll Inmon 推崇的方法:自上而下,从整个企业环境入手,基于 3 范式建立统一的数据中心(EDW),前端工具访问数据集市
- Ralph Kimbal 推崇的方法:自下而上,基于维度模型(星型模型/雪花模型),根据实际需求开发
我倾向于采用自上而下的方式,特别是业务并不复杂的时,如果有能力做整体规划,一定要通过良好的顶层设计简化后续工作。自上而下的模式中,用统一的维度贯穿所有环节,从每个环节提取事实,数仓建设过程有序可控。
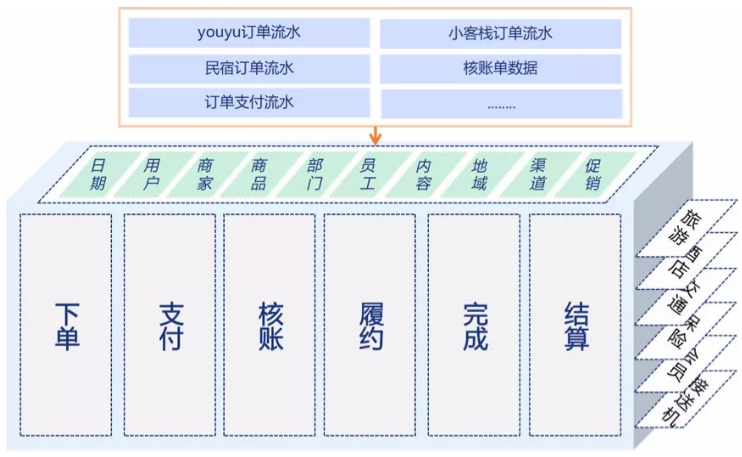
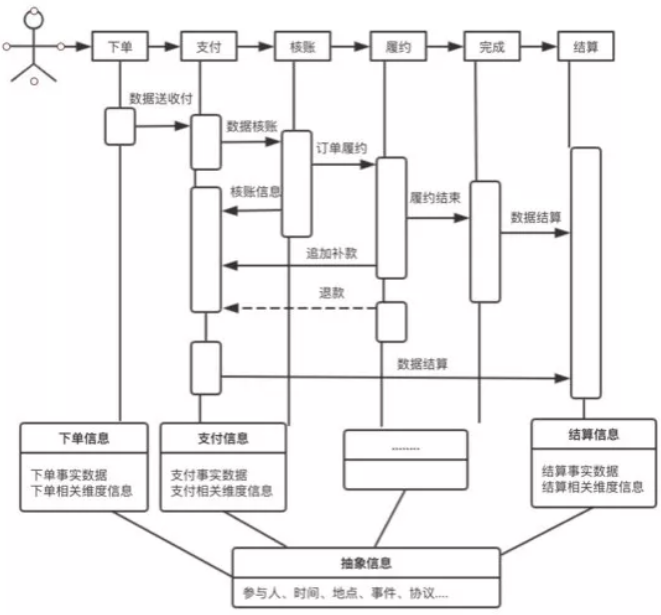
上一节中给出的「第一个步骤」的产出采用的就是自上而下的思路,是特别好的模版。
数据仓库中的术语
持续补充。
ETL
ETL( Extrace/Transformation/Load):清洗、转换、加载到数据仓库。就是按照第一个步骤产出的规划,将各个数据源的数据整理到数仓中。
数仓概念中的 ETL 没有听起来那么简单,这个过程可能是由非常多的触发条件不同的 job 组成,多 job 合力完成 全量数据加载、增量数据加载,数据聚合 等工作。「众多 job 的调度」也是一个有点复杂的问题。
数据仓库层次
原始细节数据 -> 当前细节数据(清洗后的数据)-> 轻度汇总数据 -> 高度汇总数据
数据仓库层次:
- STAGE 层: 与原始业务数据完全相同,临时性的
- ODS 层: 编码统一等处理后保留的细节数据,
符合 3 范式 - MID 层: MID 层,介于 DM(数据集市) 和 DW(数据湖) 之间,
反范式设计,增加数据冗余(维度表和实时表) - MRT 层: 最终展现的数据,多维模型,中高度的汇总数据
另一种分层方法:
-
业务数据层:STG(数据缓冲区)、ODS(操作数据层)
STG:缓存来自 DB 抽取、消息、日志解析落地的临时数据,结构与业务系统保持一致;负责对垃圾数据、不规范数据进行清洗转换;只为 ODS 层服务。
ODS:业务明细数据保留区,负责保留数据接入时点后历史变更数据,数据原则上全量保留
-
公共数据层:DWD(明细数据层)、DWS(汇总数据层)、DIM(公共维度层)
DWD:整合后的业务过程明细数据 DWS:按主题对共性维度指标数据进行轻度、高度聚合 DIM:对维度进行标准化定义,维度信息共享
-
应用数据层:
DWA:面向各产品线、业务线的数据加工。
MID 层反范式设计举例:
情况1: 表没有主键,可以重复插入
时间维度 客户维度 金额
20131001 0001 100
20131001 0001 100
情况2: 字段之间冗余:
年编号 季度编号 月编号 日编号
2010 20201 2020112 202011202
元数据
技术元数据:数据仓库的描述信息
业务元数据:
OLAP
数据仓库和 OLAP 的关系是互补的,OLAP 从数据仓库中国呢抽取详细数据的子集。
OLAP 分类:
- 关系 OLAP, RelationalOLAP,基于关系型数据库,ROLAP
- 多维 OLAP, MultidimensionalOLAP,MOLAP
- 混合型 OLAP, HOLAP
维度和度量
每个分析角度是一个维,多角度分析称为多维分析,例如:时间、地域、产品、客户。维度可以有层次粒度。
贷款分析模型:
维度: 时间 贷款银行 区域 贷款质量
时间维度的粒度: 年、季度、月
贷款银行的粒度: 总行、地方行
区域维度的粒度: 省、市
贷款质量的粒度: 合格、不合格
引入维度和维度粒度后,数据变成立体的,通过多个维度确定一个数据。
切片/切块/钻取
切片/切块:设置多个维度条件,取出符合这些维度的数据。
上钻/下钻: 不良贷款又继续分为多种情况,细粒度向上是上钻,粗粒度向下是下钻。
旋转: 维度切换。
视频资料
youtube上的视频:
- 数据仓库系统及特点讲解
- 数据仓库设计思想及etl设计思想讲解
- 数据仓库架构和概念
- 数据仓库基本概念讲解
- Bobbile Wang 讲解 ER 模型与维度模型,维度模型中的事实表
- 数据两种流派的讲解
- 项目实践
- Tableau、Microsoft BI Stack、Privot、View等大数据应用
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文