蚂蚁金服大规模 ServiceMesh 落地思路和实践经验的 5 篇分享学习总结
本篇目录
- 本篇目录
- 说明
- 创新一:同时支持服务发现、消息队列和 istio 的 Pilot
- 创新二:可以无损更新的轻薄 Mesh 层
- 创新三:服务器资源的分时调度
- 实践经验:轻量 SDK + SideCar
- 实践经验:怎样将已有应用插入网格?
- 实践经验:SideCar 的资源占比
- 实践经验:细节优化
- 参考
说明
迷失方向了( istio 的目标是去掉中心化网关吗?),尝试从大厂的做法中找到灵感,特别幸运,蚂蚁金服正在持续分享他们的 ServiceMesh 经验:
- Service Mesh 落地负责人亲述:蚂蚁金服双十一四大考题
- 蚂蚁金服 Service Mesh 大规模落地系列 - 核心篇
- 蚂蚁金服 Service Mesh 大规模落地系列 - 消息篇
- 蚂蚁金服 Service Mesh 大规模落地系列 - 运维篇
- 蚂蚁金服 Service Mesh 大规模落地系列 - RPC 篇
读完上面的 5 篇分享后,基本搞明白了蚂蚁金服的 ServiceMesh 落地思路。
蚂蚁金服的 ServiceMesh 采用了 istio 的基本框架,但是用自行实现的 SOFAMosn 替换了 istio 的 SideCar,在 SOFAMosn 上作了大量既创新又艰苦的工作。
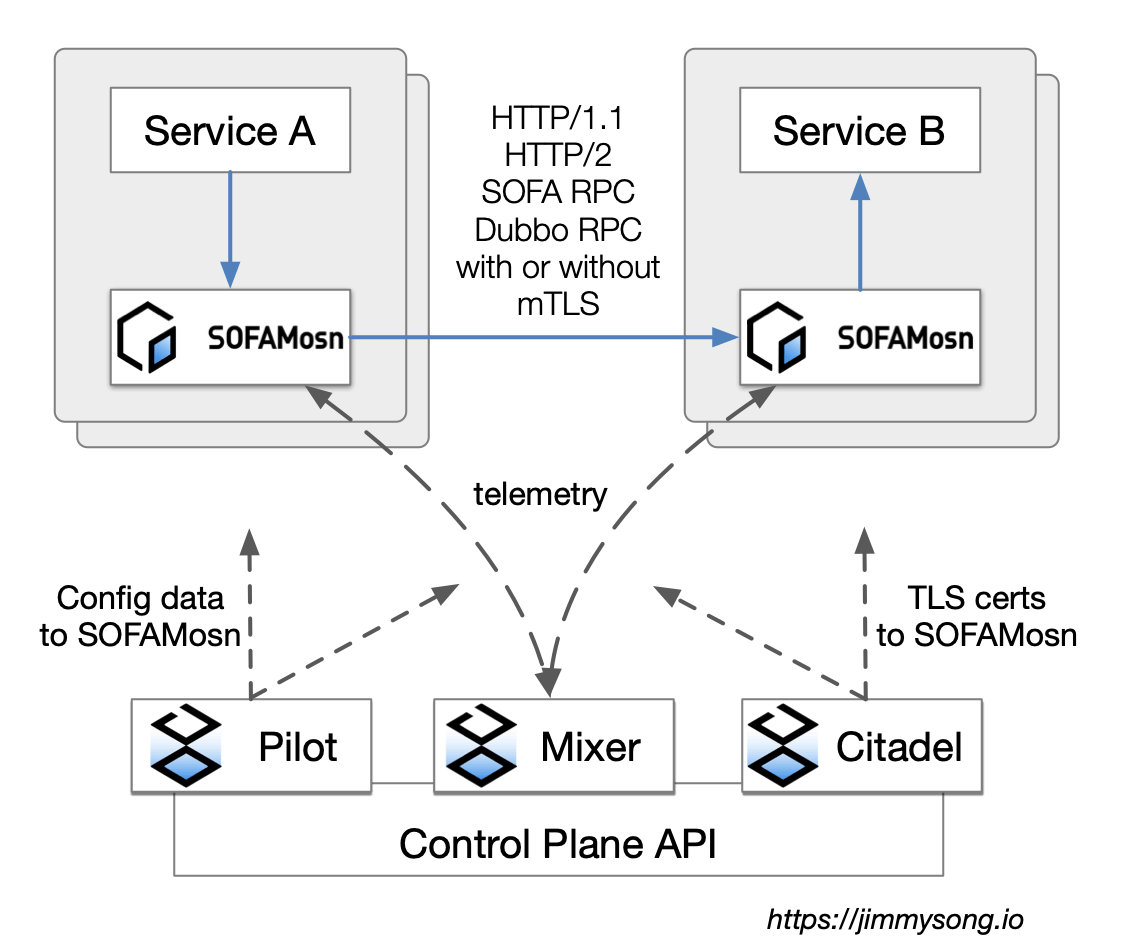
创新一:同时支持服务发现、消息队列和 istio 的 Pilot
SOFAMosn 不仅支持 istio 的 Pilot,还可以对接蚂蚁金服的服务框架和消息队列,我认为这是一个特别重要的创新。 《istio 的目标是去掉中心化网关吗?》中,我还在纠结网关特色更浓郁的 istio 与服务框架是一回事还是两回事。看了蚂蚁金服的做法,发现自己太没有想象力了。
为啥只代理 http 请求,一同代理服务框架的通信请求有什么不可以?
更进一步,消息队列、redis、数据库是不是也可以代理?
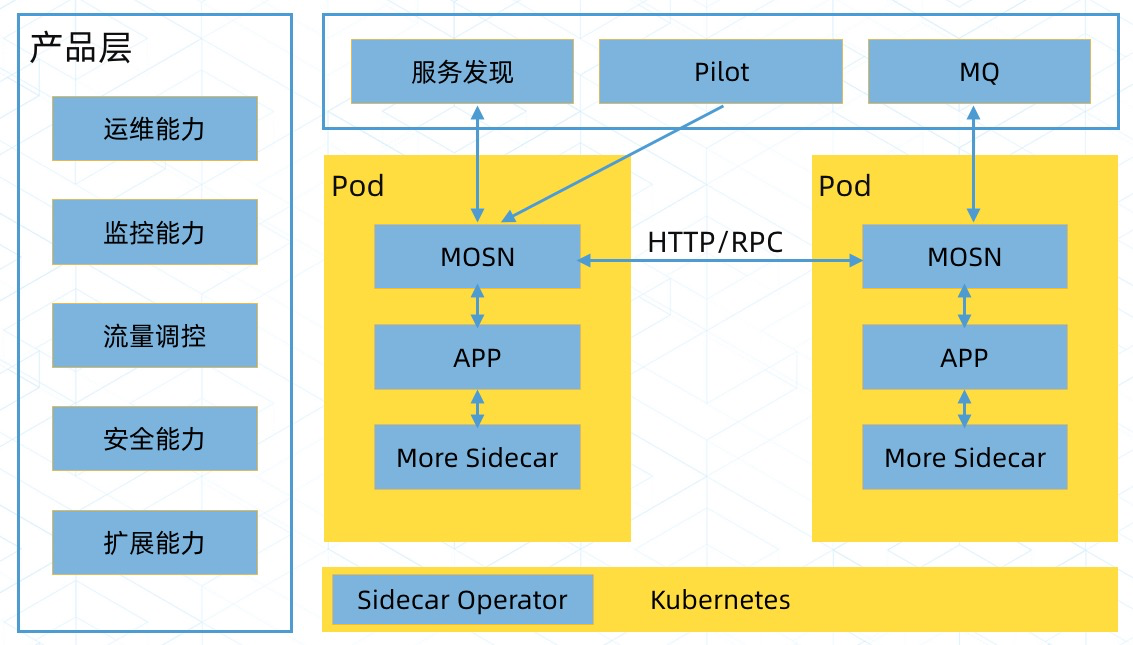
这样一来 istio 的概念范畴成倍扩大,成为了一个覆盖各种中间件的统一接口层。蚂蚁金服认为,这种做法将服务框架、消息队列等基础中间件与业务系统解耦,维护升级成本降低。这个观点是对的,这是在业务程序与基础中间件之间增加了一个轻薄的「Mesh 层」。
反思自己为什么没有往这方面想?学习 envoy 的时候就应该想到,envoy 有不少应用协议的 filter,当时就应该意识到它可以做更多的事情。原因是技术实力和积累不足,做过、研究过的事情太少,技术上不敢想,思维没打开。
创新二:可以无损更新的轻薄 Mesh 层
SOFAMosn 的无损更新在我这个外行看来,很厉害,通过下面这张图可以感受到:
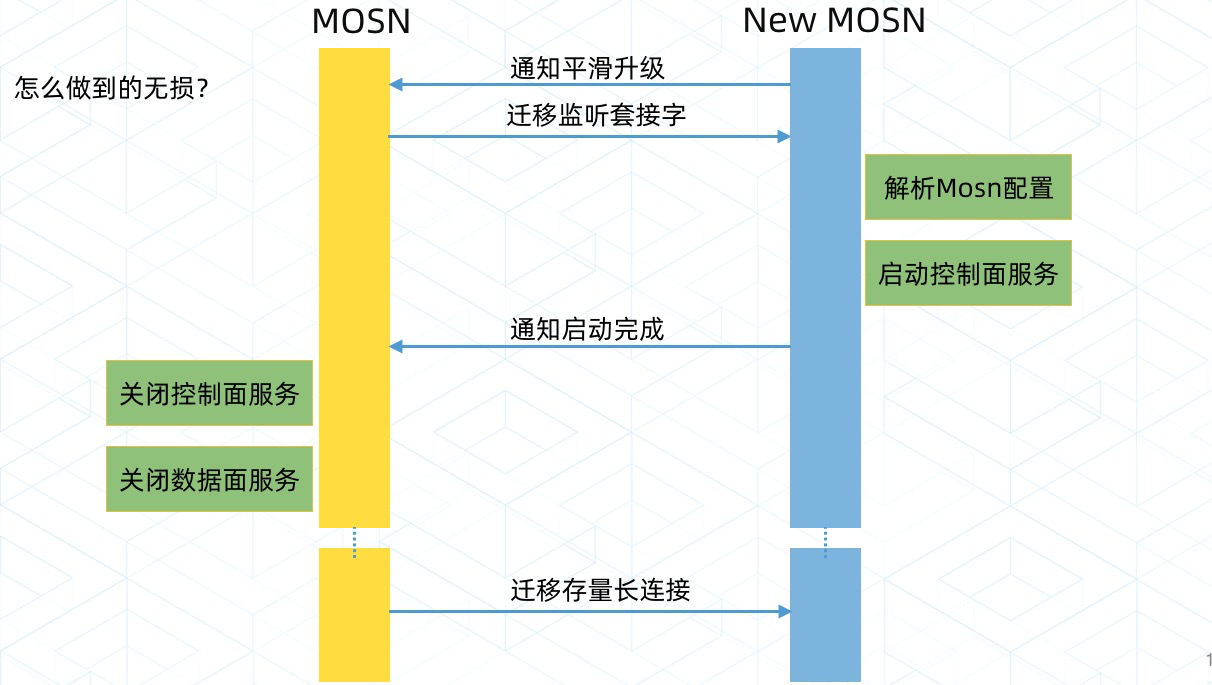
通过分享的资料可以知道,为了实现无损更新做了大量工作,因为 SOFAMosh 不仅代理了 http 请求,还代理了服务框架和消息队列,「无损」面临多种挑战。细节就不说了,原文中有大篇幅的介绍。
另外,SOFAMosn 的升级一定要采用金丝雀的方式,这是最基本的运维操作准则。
创新三:服务器资源的分时调度
这也是一个特别重要的创新:在 kubernetes 中,应用的扩容和缩容变得非常简单,是资源调度上的一个重要进展,蚂蚁金服更进一步,做到了分时调度。
传统方式通过改变 Pod 数量实现扩容缩容,扩缩时大量新建或销毁 Pod。 Pod 的新建和销毁是开销很大的操作,牵一发而动全身,依赖的亲和性/非亲和性资源、转发规则、发现地址、已有连接等等都要随着变化。
想象一下,一个规模比较大的应用,从几千个 Pod 咔嚓缩小到几百,然后轰的一下扩张到几千,十几个这样规模的应用同时扩缩,场面会是多么壮观!
蚂蚁金服的分时思路是:要调度的是资源,为啥要去革 Pod 的命?在资源上做手脚不就可以了吗?把这个设计思路反复读了几遍,隔着屏幕感觉到「机智」。
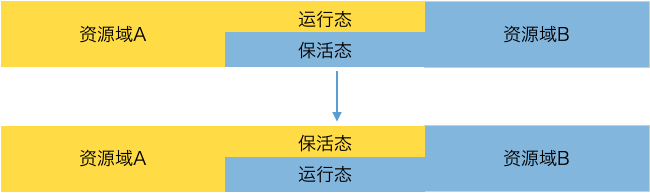
Pod 数量不动,改变 Pod 的运行状态:需要多干活的应用把 Pod 设置为运行态,多占资源;需要出让资源的应用把 Pod 设置为保活态,少占资源。 这种做法可能会给 Pod 的调度带来一些挑战,但它是一个好的做法,这不就是操作系统中的进程优先级嘛!
实践经验:轻量 SDK + SideCar
蚂蚁金服没有使用 istio 的正向代理方案,采用 “轻量 SDK + SideCar” 的方式,就是自己实现的 SOFAMosn。
RPC 篇 说这是历史包袱,私有协议的存在导致无法直接用 envoy。我觉得主要还是因为他们想把服务框架和消息队列都融进来,就像下面这样(还有就是为了实现无损更新):
蚂蚁金服比较排斥 iptables,认为 iptables 影响性能,而且不可观测:
主要原因是一方面 iptables 在规则配置较多时,性能下滑严重。另一个更为重要的方面是它的管控性和可观测性不好,出了问题比较难排查。蚂蚁金服在引入 Service Mesh 的时候,就是以全站落地为目标的,而不是简单的“玩具”,所以我们对性能和运维方面的要求非常高,特别是造成业务有损或者资源利用率下降的情况,都是不能接受的。
实践经验:怎样将已有应用插入网格?
怎样把正在运行的大量 Pod 塞入 Mesh ?虽然一般规模的公司不会像蚂蚁金服那样面对几十万个 Pod,但也应该认真考虑这个问题。
第一种方案是蚂蚁金服的特有做法,升级自研的底层开发框架的 SOFABoot,这种做法会影响业务程序运行:
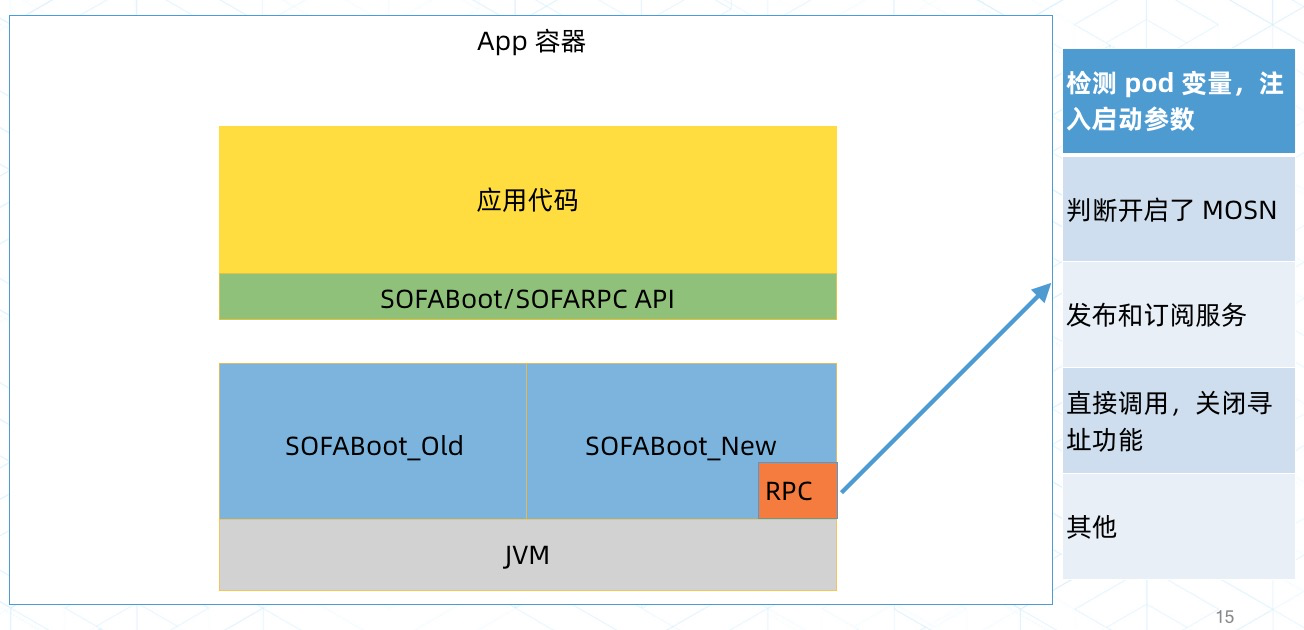
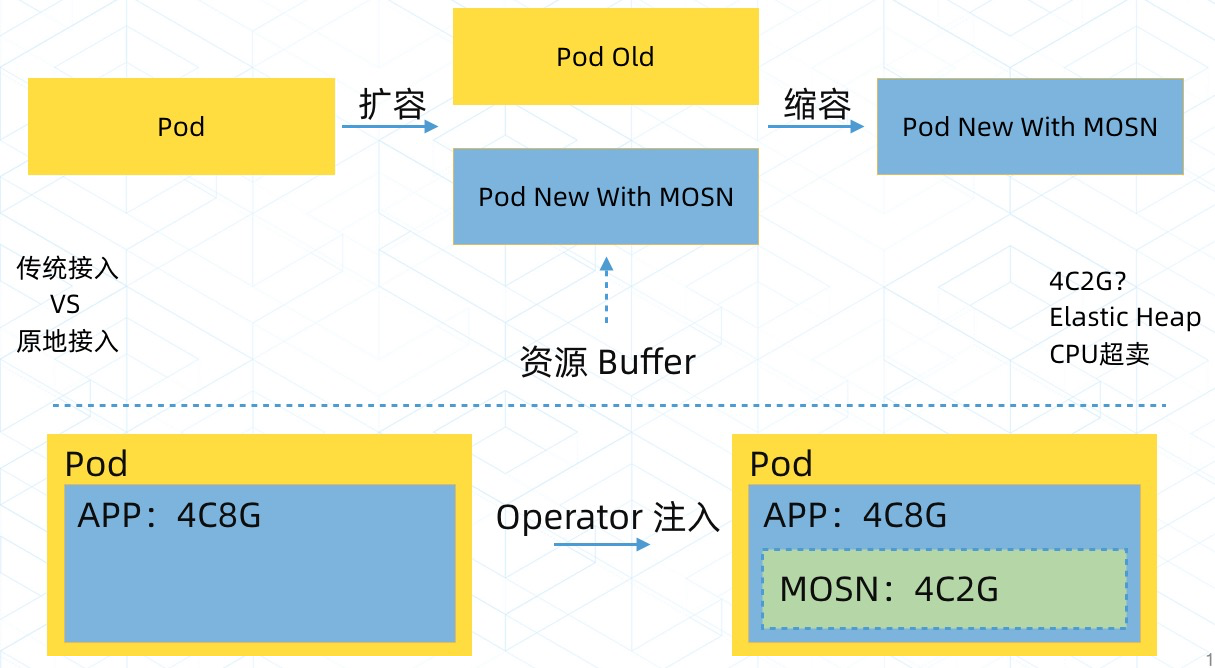
第二种方案是更好的通用做法,原地接入,用 Operator 在现有 Pod 中注入 SOFAMosn。这个要特别说明一下,蚂蚁金服设计了 Pod 内超卖方案,注入 SOFAMosn 不会增加 Pod 占用的资源,是在 Pod 资源不变的情况下,注入 SOFAMosn 容器,见下一节「SideCar 的资源占比」:
实践经验:SideCar 的资源占比
SOFAMosn 容器与业务程序的资源配比是一个非常重要的参考,我认为这个配比直接决定 Mesh 是在节约资源还是在浪费资源。 蚂蚁金服在资源配比上探索了三个做法,踩了两次坑:
方法1:
将 SOFAMosn 容器的 CPU 设置为业务容器的 1/4,内存是业务容器的 1/16,部分高流量应用的 SOFAMosn 出现严重的内存不足和 OOM。 另外 SOFAMosn 容器的资源没有纳入 Quota 管控,这个是蚂蚁金服自己的历史包袱。
方法2:
非云环境中部署的原地 ServiceMesh 没有额外配额的概念,不能超卖内存,为了兼容这种情况,让 SOFAMosn 占用 Pod 的资源,占用比例为 1/16 的内存,但这样一来业务程序见到的内存发生了变化。
方法3:
最终设计了 Pod 内超卖机制,业务程序看到的内存和 CPU 是全部的资源,业务程序和 SOFAMosn 一同抢占 Pod 的资源,SOFAMosn 优先级低,相碰时先让步。
Pod 内超卖机制如下图所示,为 SOFAMosn 分配的内存是 2C2G,业务程序看到的内存是 4C8G,SOFAMosn 和业务容器所在的 Pod 真实拥有的资源是业务程序看到 4C8G 而不是累加的 6C10G,SOFAMosn 的 2C2G 是超卖的资源:

实践经验:细节优化
还优化了大量的细节,譬如 golang 的 writev、内存复用、序列化、IO 模型、TLS 等,不复述了。
蚂蚁金服以及 ServiceMesh 的最终目标应当是;统一接入,全局治理。
继续学习…
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文