阅读笔记《不一样的 双11 技术,阿里巴巴经济体云原生实践》
本篇目录
- 本篇目录
- 说明
- 01 释放云原生价值才是拥抱 Kubernetes 的正确姿势
- 02 阿里云上万个 Kubernetes 集群大规模管理实践
- 03 蚂蚁金服双 11 的调度系统
- 04 云原生应用万节点分钟级分发协同实践
- 05 阿里巴巴大规模神龙裸金属 K8s 集群运维实践
- 06 PouchContainer 容器技术演进助力阿里云原生升级
- 07 2019 年双11 etcd 技术升级分享
- 08 Service Mesh 带来的变化和发展机遇
- 09 阿里集团 双11 核心应用落地 Service Mesh 所克服的挑战
- 10 蚂蚁金服 双11 Service Mesh 超大规模落地揭秘
- 11 服务网格在“路口”的产品思考与实践
- 12 CSE:Serverless 在阿里巴巴 双11 场景的落地
- 13 解密双11 小程序云背后毫秒级伸缩的Serverless 计算平台:函数计算
- 14 双11 背后的全链路可观测性:阿里巴巴鹰眼在“云原生时代”的全面升级
- 完整 PDF 文件下载
- 参考
说明
阿里巴巴对云原生技术在 双11 的实践细节进行深挖,筛选了其中 22 篇有代表性的文章进行重新编排,整理成书《不一样的 双11 技术:阿里巴巴经济体云原生实践》,全书总共 180 页。用了一天的时间仔细研读,这里是阅读过程中做的笔记。
《阿里巴巴经济体云原生实践》下载方法,关注微信公众号「我的网课」,回复「阿里网格」。
01 释放云原生价值才是拥抱 Kubernetes 的正确姿势
张振,花名守辰,阿里云云原生应用平台高级技术专家:
在 Kubernetes 中可以通过 PodDisruptionBudget 来定量地描述对应用的可迁移量,例如可以设置对应用进行驱逐的并发数量或者比例。这个值可以参考发布时的每批数量占比来设置。假如应用发布一般分 10 批,那么可以设置 PodDisruptionBudget 中的 maxUnavailable 为 10%(对于比例,如果应用只有 10 个以内的实例,Kubernetes 还是认为可以驱逐 1 个实例)。万一应用真的一个实例都不允许驱逐呢,那么对不起,这样的应用是需要改造之后才能享受上云的收益的。一般应用可以通过改造自身架构,或者通过 operator 来自动化应用的运维操作,从而允许实例的迁移。
改造后,一个 pod 内会包括一个运行业务的主容器的,一个运行着各种基础设施 agent 的运维容器,以及服务网格等的 sidecar。轻量化容器之后, 业务的主容器就能以比较低的开销运行业务服务,从而为更方便进行 serverless 的相关改造。
相比 pod 层次的不可变,我们认为坚持容器级别的不可变原则,更能发挥 Kubernetes 多容器 pod 的技术优势。为此,我们建设了支持应用发布时,只原地修改 pod 中部分容器的能力,特别的,建设了支持容器原地升级的工作负载控制器,并替换 Kubernetes 默认的 deployment 和 statefulset 控制器作为内部的主要工作负载。
这部分能力,已经通过 OpenKruise 项目开源出来。OpenKruise 中的 Kruise 是 cruise的谐音,’K’ for Kubernetes, 寓意 Kubernetes 上应用的自动巡航。目前,OpenKruise 正在计划发布更多的 Controller 来覆盖更多的场景和功能比如丰富的发布策略,金丝雀发布、蓝绿发布、分批发布等等。
要点提炼:
1)从文章推断,阿里巴巴之前自研了一套 PaaS 平台,然后用 kubernetes 对自研的 PaaS 平台进行替换式升级。做出这个选择的原因有两个,第一个原因是 kubernetes 有先进设计和先进理念;第二个原因,技术输出已经是阿里巴巴集团的重要战略,必须要吃自己的狗粮,才能说服用户信任并采购阿里巴巴的技术方案。
2)阿里巴巴采用了「Pod = 一个业务容器 + 多个 sidecar 容器」的设计,将为业务程序提供支持的基础设施组件全部拆分到 sidecar。同时改良了 deployment 和 statefulset 控制器,可以只更新 Pod 中的某个容器。这样做好处是基础设施组件可以业务程序无感知的情况更新,业务团队负责业务容器,基础设施团队负责 sidecar 容器,各司其职互不干扰。与之相对的一种设计方案是,将基础设置组件全部下沉到 node,Pod 内有且仅有业务容器,这种方案可以节省 sidecar 减少资源开销,但实施难度相对高,并且需要为基础组件单独开发一套运维管理系统。
02 阿里云上万个 Kubernetes 集群大规模管理实践
汤志敏,阿里云容器服务高级技术专家:
1)选择了阿里云自研的高性能容器网络Terway, 一方面需要通过弹性网卡 ENI 打通用户 VPC 和托管 master 的网络,另一方面提供了高性能和丰富的安全策略;
2)2019 年 6 月,阿里巴巴将内部的云原生应用自动化引擎 OpenKruise 开源,其中的 BroadcastJob 功能,他非常适用于每台 worker 机器上的组件进行升级,或者对每台机器上的 节点进行检测。(Broadcast Job 会在集群中每个 node 上面跑一个 pod 直至结束。类似于社区的DaemonSet, 区别在于 DaemonSet 始终保持一个 pod 长服务在每个 node 上跑,而 BroadcastJob 中最终这个 pod 会结束。
要点提炼:
这一篇分享的是阿里巴巴的 ACK 服务,即 kubernetes as a service,重点是怎样实现 kubernetes 的快速交付。
03 蚂蚁金服双 11 的调度系统
曹寅,蚂蚁金服 Kubernetes 落地负责人:
1)社区的调度器在 5k 规模测试中,调度性能只有 1~2 pod/s;–> 自研批量调度功能 + 局部 filters 性能优化。
2)不同业务的流量洪峰来源时间不同,采用扩缩的方式耗时不可控、考验大规模调用稳定性;–> 将不重叠的业务实例放在相同资源池内,通过分时调度腾挪资源。
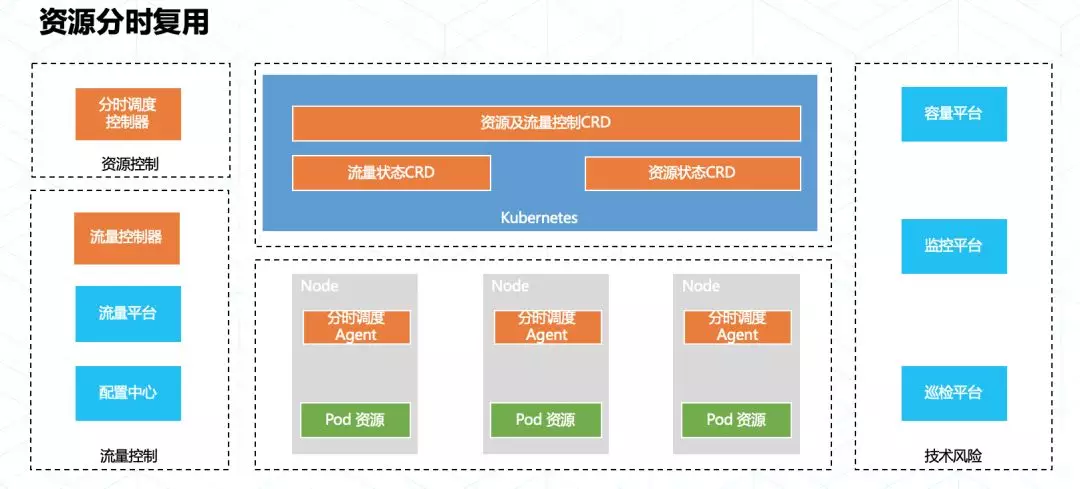
3)将批处理、流式计算业务纳入管理;–> 通过 Operator 实现,根据计算任务动态申请、释放 Pod;
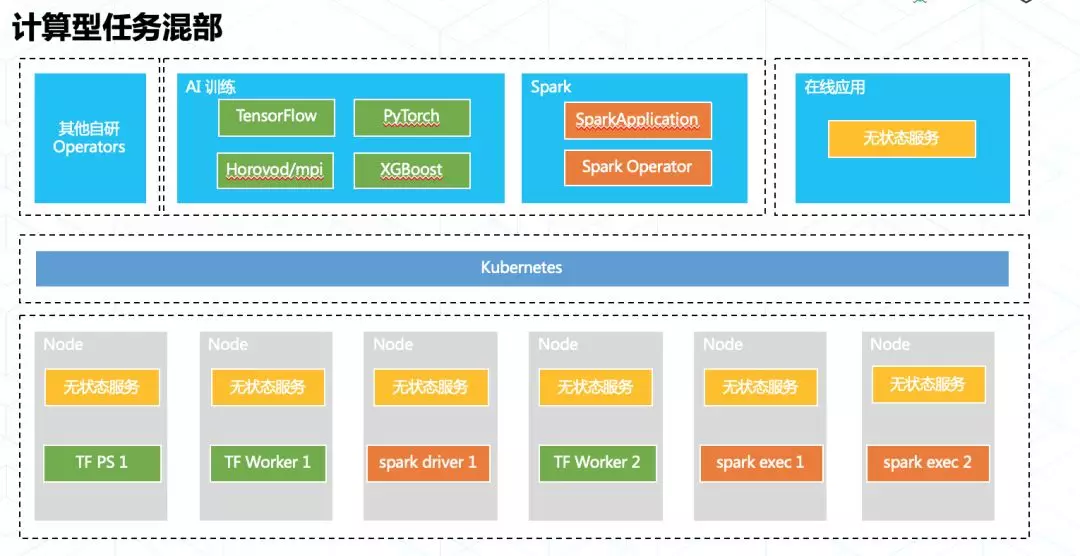
4)向业务方开放 CRD + Operator,较弱的 apiserver 和灵活的 Operator 对集群的稳定性形成巨大挑战;–> 总结出一套实践原则。
- CRD 在定义是要明确未来最大数量,大量 CRD 业务采用 aggregate-apiserver 扩展;
- CRD 必须限定于 namespace 范围内,影响范围最低;
- 避免使用 MutatingWebhook + 资源 Update 操作;
- 所有 controllers 都使用 informers,并对写操作限流;
- DaemonSet 尽量不用。
5) 几十个独立的 kubernetes 集群的管理维护;–> 设计了 kubernetes on kubernetes,3 小时交付数千 node 集群;
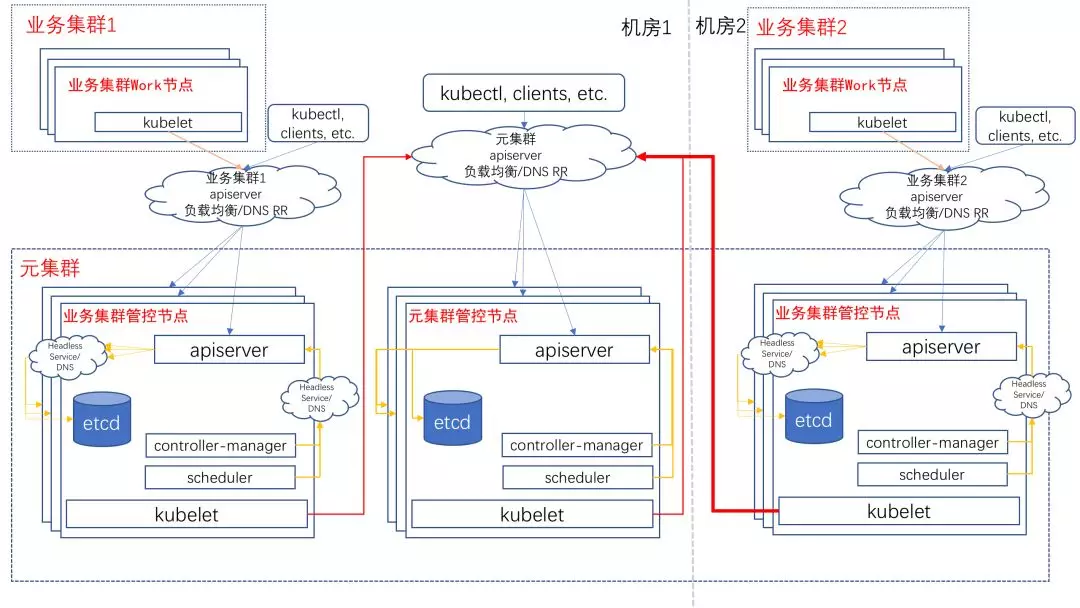
6)接下来要着重解决的问题:kubernetes 的租户隔离能力弱。
要点提炼:蚂蚁金服的集群规模和调度的频繁性给调度系统带来了挑战,大型互联网公司在 kuberntes 技术上研究的重点就是改良改进调度系统。透过这篇分享,我们也了解到推动 kubernetes 落地的关键就是怎样把情况各异的系统迁移 kubernetes 集群中,蚂蚁金服采用了 CRD + Operator。
04 云原生应用万节点分钟级分发协同实践
谢于宁,花名予栖,阿里云容器服务高级开发工程师
罗晶,花名瑶靖,阿里云容器服务高级产品经理
邓隽,阿里云容器服务技术专家
1)通过控制容器镜像大小、采用 P2P 分发镜像层、优化 Registry 服务端等方式,我们极大优化了大规模分发的性能,最终达成了万节点分钟级分发的目标;
要点提炼:主要是介绍应用市场。
05 阿里巴巴大规模神龙裸金属 K8s 集群运维实践
姚捷,花名喽哥,阿里云容器平台集群管理高级技术专家
1)神龙将网络/存储的虚拟化开销 offload 到一张叫 MOC 卡的 FPGA 硬件加速卡上,降低了原 ECS 约 8% 的计算虚拟化的开销,同时通过大规模 MOC 卡的制造成本优势,摊平了神龙整体的成本开销;
2)集团电商的容器运行在云上神龙反而比非云物理机的性能要好 10%~15%,主要原因是因为虚拟化开销已经 offload 到 MOC 卡上,神龙的 CPU/Mem 是无虚拟化开销的,而上云后运行在神龙上的每个容器都独享 ENI 弹性网卡,性能优势明显。同时每个容器独享一块 ESSD 块存储云盘,单盘 IOPS 高达 100 万,比 SSD 云盘快 50 倍,性能超过了非云的 SATA 和 SSD 本地盘。
3)Pod 运行在神龙裸金属节点上,将网络虚拟化和存储虚拟化 offload 到独立硬件节点 MOC 卡上,并采用 FPGA 芯片加速技术,存储与网络性能均超过普通物理机和 ECS;
4)MOC 有独立的操作系统与内核,可为 AVS(网络处理)与 TDC(存储处理)分批独立的 CPU 核;
5)Pod 由 Main 容器(业务主容器),运维容器(star-agent side-car 容器)和其它辅助容器(例如某应用的 Local 缓存容器)构成。Pod 内通过 Pause 容器共享网络命名空间,UTS 命名空间和 PID 命名空间(ASI 关闭了 PID 命名空间的共享);
6)Pod 的 Main 容器和运维容器共享数据卷,并通过 PVC 声明云盘,将数据卷挂载到对应的云盘挂载点上。在 ASI 的存储架构下,每一个 Pod 都有一块独立的云盘空间,可支持读写隔离和限制磁盘大小;
7)Pod 通过 Pause 容器直通 MOC 卡上的 ENI 弹性网卡;
8)Pod 无论内部有多少容器,对外只占用独立的资源,例如 16C(CPU)/60G(内存)/60G(磁盘);
9)电商核心系统应用的主力机型为 96C/527G,此次电商上云神龙将弹性网卡和 EBS 云盘的限制数提高到 64 与 40,有效避免了 CPU 与内存的资源浪费;
10)入口层 aserver 神龙实例由于需要承担大量的入口流量,对 MOC 的网络收发包能力的要求极高,为避免 AVS 网络软交换 CPU 打满,对于神龙 MOC 卡里的网络和存储的 CPU 分配参数的需求不同,常规计算型神龙实例的 MOC 卡网络/存储的 CPU 分配是 4+8,而 aserver 神龙实例需要配置为 6:6;
11)在 双11 前几周,通过大规模节点弹性扩容能力,从阿里云弹性申请大批量神龙,部署在独立的大促集群分组里,并大规模扩容 Kubernetes Pod 交付业务计算资源。在 双11 过后,立即将大促集群中的 Pod 容器批量缩容下线,大促集群神龙实例整体销毁下线,日常只持有常态化神龙实例;
12)从神龙交付周期而言、今年上云后从申请到创建机器,从小时/天级别缩短到了分钟级,上千台神龙可在 5 分钟内完成申请,包括计算、网络、存储资源,并在 10 分钟完成创建并导入 Kubernetes 集群;
13)神龙集群的可调度率始终维持在 98% 以上,双11 神龙的宕机率维持在0.2‰ 以下;
14)神龙节点上使用标准 Kubernetes 的接口打 Label;
15)通过 ssh 与端口 ping 巡检对资源池的宕机情况进行了监控;
16)节点自愈可提供 1 分钟异常问题发现,5 分钟定位,10 分钟修复的能力;
17)神龙机器异常包括宕机、夯机、主机 load 高、磁盘空间满、too many openfiles、核心服务(Kubelet、Pouch、Star-Agent)不可用等。主要的修复动作包括宕机重启、业务容器驱逐、异常软件重启、磁盘自动清理,其中 80% 以上问题可通过重启宕机机器与将业务容器驱逐到其他节点完成节点自愈;
18)监听神龙 Reboot 重启与 Redepoly 实例迁移二个系统事件来实现 NC 侧系统或硬件故障的自动化修复;
要点提炼:kubernetes 使用的服务器是阿里云的神龙服务器,复用了 IaaS 的网络和虚拟化存储,kubernetes 的弹性能力很大一部分来自于可随时供应服务器的 IaaS 层。
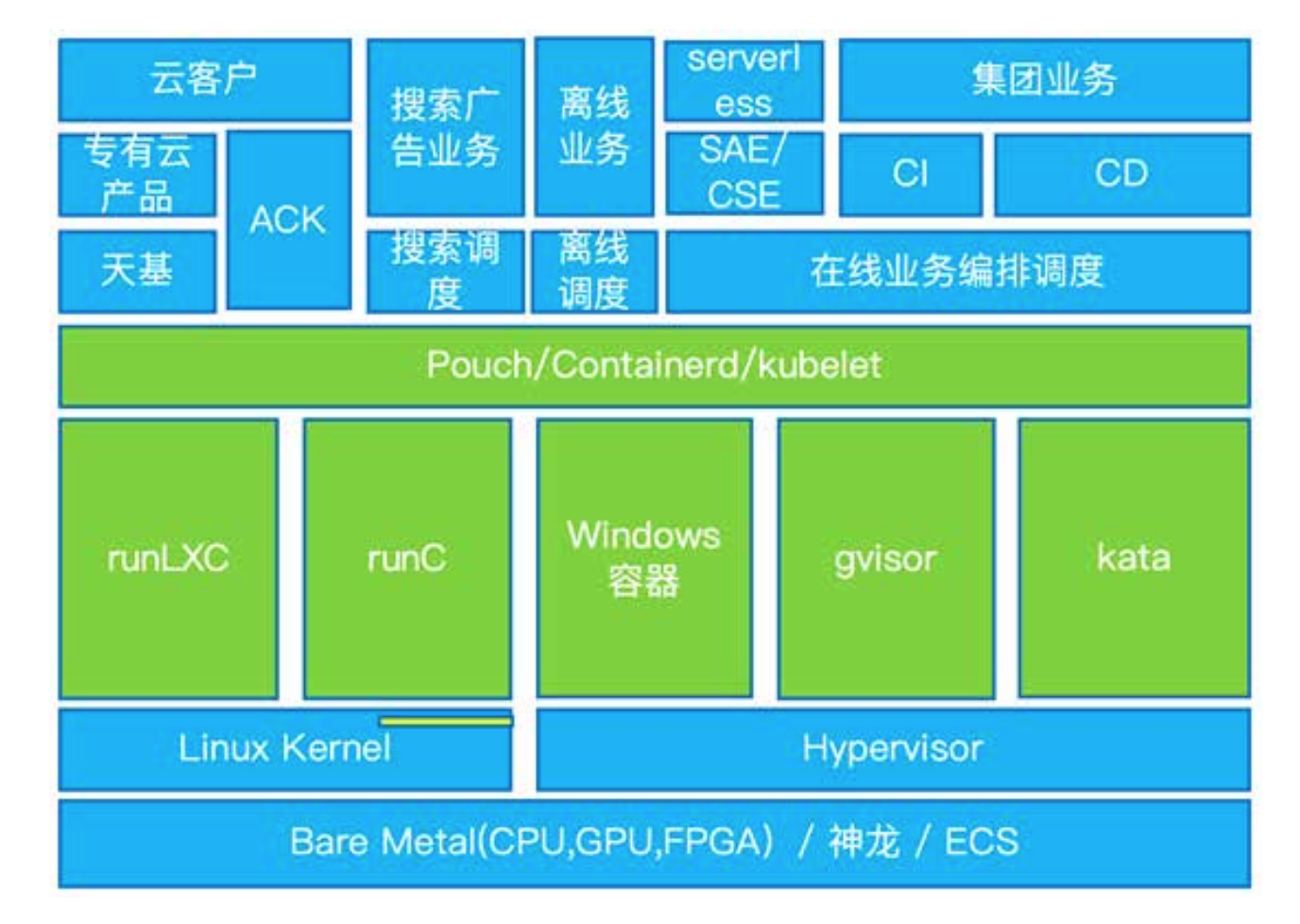
06 PouchContainer 容器技术演进助力阿里云原生升级
杨育兵,花名沈陵,阿里云基础技术中台高级技术专家:
1)和集团 os 创新团队以及蚂蚁 os 虚拟化团队合作共建了 kata 安全容器和 gvisor 安全容器技术,兼容性要求高的场景我们优先推广 kata 安全容器;
2)首次支持了 Windows 容器运行时;
3)PouchContainer 把 diskquota、lxcfs、dragonfly、DADI 这写特性都做成了可插拔的插件,对一些场景做了 containerd 发行版,支持纯粹的标准 CRI 接口和丰富的运行时;
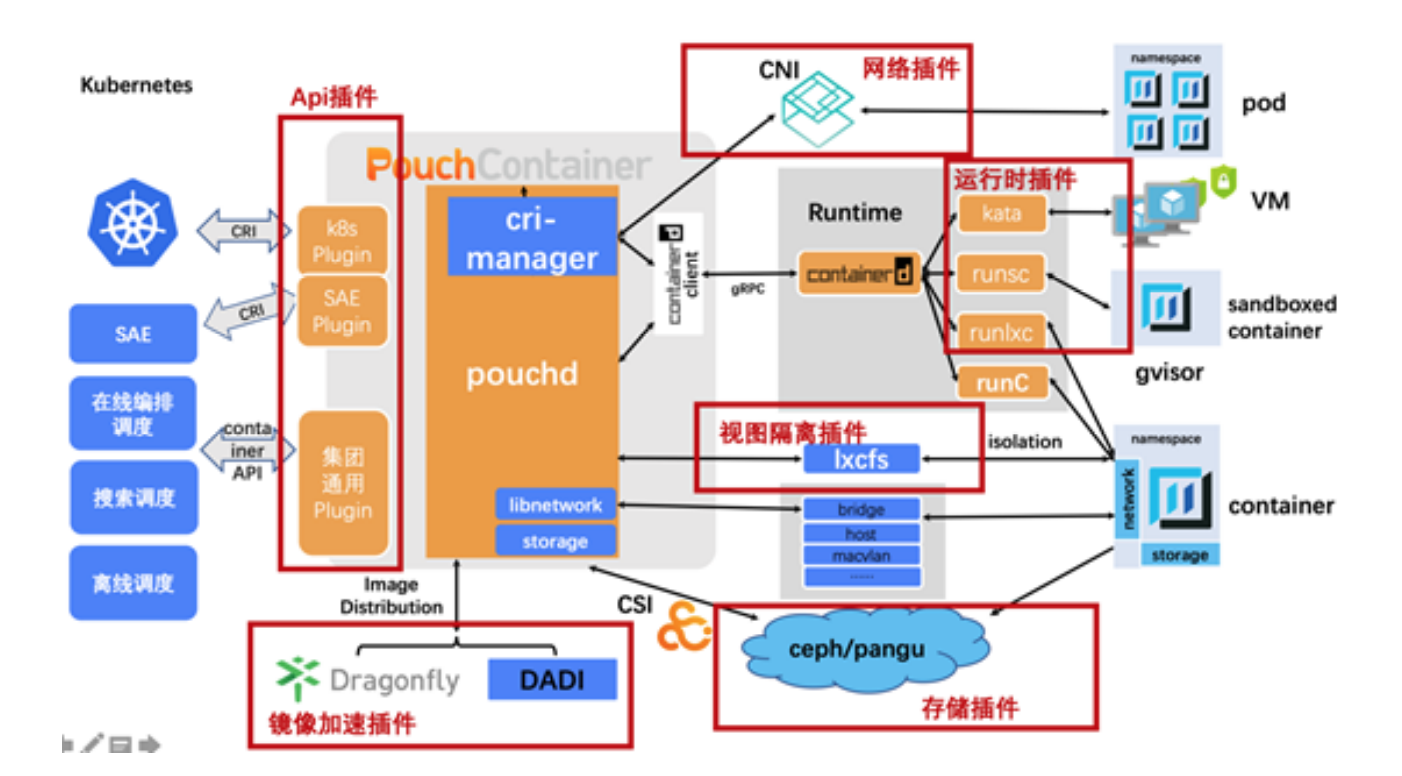
4)PouchContainer 支持使用 Dragonfly 来做 P2P 的镜像分发;
5)第一代镜像分发的缺点是无论用户启动过程中用了多少镜像数据,在启动容器之前就需要把所有的镜像文件都拉到本地,在很多场景都是又浪费的,特别影响的是扩容场景;
6)第二代的镜像加速方案,我们调研了阿里云的盘古,盘古的打快照、mount、再打快照完美匹配打镜像和分发的流程。能做到秒级镜像 pull,因为 pull 镜像时只需要鉴权,下载镜像 manifest,然后 mount 盘古;
7)ContainerFS 团队合作共建了第三代镜像分发方案:DADI,基于块设备的按需p2p加载技术;
8)镜像 pull 阶段只需要下载镜像的 manifest 文件(通常只有几 K大小),速度非常快,启动阶段大地会给每个容器生成一个快设备,这个块设备的chunk 读取是按需从超级节点或临近节点 P2P 的读取内容;
9)为了防止容器运行过程中出现 iohang,我们在容器启动后会在后台把整个镜像的内容全部拉到 node 节点,享受超快速启动的同时最大程度的避免后续可能出现的 iohang;
10)在每个机房都设置了超级节点做缓存,每一块内容在特定的时间段内都只从镜像仓库下载一次;
11)在 Sigma-2.0 时代使用 libnetwork 把集团现存的各种网络机架构都统一做了 CNM 标准的网络插件,沉淀了集团和专有云都在用的阿里自己的网络插件;在在线调度系统推广期间 CNM 的网络插件已经不再适用,对原来的网络插件做了包装,沉淀了 CNI 的网络插件,把 CNM 的接口转换为 CNI 的接口标准;
12)使用神龙 eni 网络模式可以避免容器再做网桥转接,但是用神龙的弹性网卡和 CNI 网络插件时也有坑需要避免,特别是 eni 弹性网卡是扩容容器时才热插上来的情况时。创建 eni 网卡时,udevd 服务会分配一个唯一的 id N,比如 ethN,然后容器 N 启动时会把 ethN 移动到容器 N 的 netns,并从里面改名为 eth0。容器 N 停止时,eth0 会改名为 ethN 并从容器 N 的 netns 中移动到宿主机的 netns 中。这个过程中,如果容器 N 没有停止时又分配了一个容器和 eni 到这台宿主机上,udevd 由于看不到 ethN 了,他有可能会分配这个新的 eni 的名字为ethN。容器 N 停止时,把eth0 改名为 ethN 这一步能成功,但是移动到宿主机根 netns 中这一步由于名字冲突会失败,导致eni 网卡泄漏,下一次容器N启动时找不到它的 eni 了;
13)富容器可以瘦下来还要依赖于运维 agent 可以从主容器中拆出来,那些只依赖于 volume 共享就能跑起来的 agent 可以先移动到 sidecar 里面去,这样就可以把运维容器和业务主容器分到不同的容器里面去,一个 Pod 多个容器在资源隔离上面分开,主容器是 Guaranteed 的 QOS,运维容器是 Burstable 的 QOS ;
14)一些 agent 不是只做 volume 共享就可以放到 sidecar 的运维容器中的,比如 monkeyking、arthas 需要能 attach 到主容器的进程上去,还要能 load 主容器中非 volume 路径上面的 jar 文件才能正常工作。对于这种场景 PouchContainer 容器也提供了能让同 Pod 多容器做一些 ns 共享的能力,同时配合 ns 穿越来让这些 agent 可以在部署方式和资源隔离上是和主容器分离的,但是在运行过程中还可以做它原来可以做的事情;
15)可插拔的插件化的架构和更精简的调用链路在容器生态里面还是主流方向,kubelet 可以直接去调用 containerd 的 CRI 接口,确实可以减少一调。 CRI 接口现在还不够完善,很多运维相关的指令都没有,logs 接口也要依赖于 container API 来实现;
16)怎么让 Dockerfile 更有表达能力,减少 Dockerfile 数量。构建的时候并发构建也是一个优化方向,buildkit 在这方面是可选的方案,Dockerfile 表达能力的欠缺也需要新的解决方案,buildkit 中间态的 LLB 是 go 代码,是不是可以用 go 代码来代替 Dockerfile,定义更强表达能力的 Dockerfile 替代品;
17)容器化是云原生的关键路径,容器技术在运行时和镜像技术逐渐趋于稳定的情况下,热点和开发者的目光开始向上层转移,K8s 和基于其上的生态成为容器技术未来能产生更多创新的领域,PouchContainer 技术也在向着更云原生,更好适配 K8s 生态的方向发展,网络/diskquota/试图隔离等 PouchContainer 的插件在 K8s 生态系统中适配和优化也我们后面的方向之一;
要点提炼:这一篇信息量很大,介绍了 PouchContainer 和镜像分发技术的演进。镜像分发技术是一个关键技术。根据文中信息判断,推出 PouchContainer 是为了集成各种运维 agent,以及适配已有的各种技术。结合前面章节对调度系统的介绍,现在运维 agent 已经尽可能拆解到 sidecar 。
07 2019 年双11 etcd 技术升级分享
陈星宇,花名宇慕,阿里云基础技术中台技术专家:
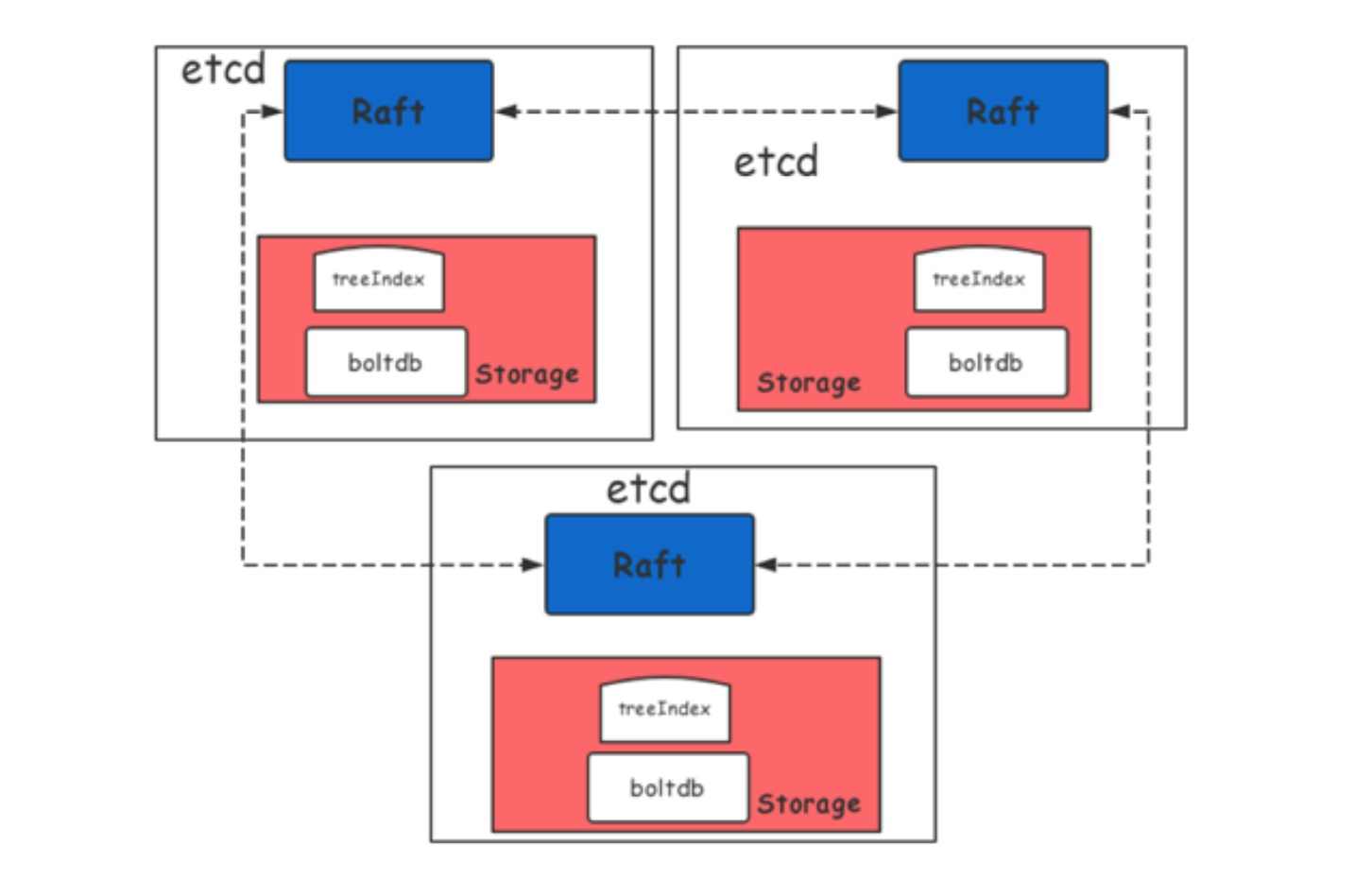
1)raft 层: raft 是 etcd 节点之间同步数据的基本机制,它的性能受限于网络 IO, 节点之间的 rtt 等,WAL 受到磁盘 IO 写入延迟;
2)存储层:负责持久化存储底层 kv, 它的性能受限于磁盘 IO,例如:fdatasync 延迟,内存 treeIndex 索引层锁的 block, boltdb Tx 锁的 block 以及 boltdb 本身的性能;
3)其他还有诸如宿主机内核参数, grpc api 层等性能影响因子;
4)推荐 etcd 至少使用 4 核 cpu, 8GB 内存,SSD 磁盘,高速低延迟网络,独立宿主机部署;
5)segregated hashmap 的 etcd 内部存储 freelist 分配回收新算法,该优化算法将内部存储分配算法时间复杂度从 o(n) 降为 o(1), 回收从 o(nlgn) 也降为 o(1), 使 etcd 性能有了质的飞跃,极大地提高了 etcd 存储数据的能力,使得 etcd 存储容量从推荐的 2GB 提升到 100GB,提升 50 倍,读写性能提升 24 倍,Performance optimization of etcd in web scale data scenario;
6)put 数据时避免大的 value, 大的 value 会严重影响 etcd 性能,例如:需要注意 Kubernetes 下 crd 的使用;
7)避免创建频繁变化的 key/value, 例如:Kubernetes 下 node 数据上传更新;
8)避免创建大量 lease 对象,尽量选择复用过期时间接近的 lease, 例如 Kubernetes 下 event 数 据的管理;
9)如开源的 etcd-operator 等,但是这些工具往往比较零散,功能通用性不强,集成度比较差,学习这些工具的使用也需要一定的时间,关键是这些工具不是很稳定,存在稳定性风险等;
10)根据阿里巴巴内部场景,基于开源 etcd-operator 进行了一系列修改和加强,开发了 etcd 运维管理平台 Alpha;
11)生命周期管理功能依托于 operator 中声明式的 CustomResource 定义,将 etcd 的集群创建、销毁的过程流程化、透明化,用户不再需要为每个 etcd 成员单独制定繁琐的配置,仅需要指定成员数量、成员版本、性能参数配置等几个简单字段;
12)数据管理工具支持定期冷备及实时热备,且保持本地盘和云上 OSS 两类备份,同时也支持从备份上快速恢复出一个新的 etcd 集群;
13)数据管理工具支持对 etcd 进行扫描分析,发现当前集群的热点数据键值数和存储量,弥补了业界无法提供数据管理的空白,同时该拓展也是 etcd 支持多租户的基础。最后,数据管理工具还支持对 etcd 进行垃圾数据清理、跨集群数据腾挪传输等功能;
14)用户 A 原来在某云厂商或自建 Kubernetes 集群,我们可以通过迁移 etcd 内部的账本数据的功能,将用户的核心数据搬移至另外一个集群,方便地实现用户的k8s集群跨云迁移;
要点提炼:
08 Service Mesh 带来的变化和发展机遇
李云,花名至简,阿里云中间件技术部高级技术专家
1)在与外部客户交流时也碰到一些特例,他们即便在应用数很少的情形下,仍希望通过 Service Mesh 去解决非 Java 编程语言(比方说Go)的分布式链路追踪等服务治理问题,虽说这些能力在 Java 领域有相对成熟的解决方案,但在非 Java 领域确实偏少;
2)阿里巴巴在分布式应用的开发和治理方面的整体解决方案的探索有超过十年的历程,采用单一的 Java 语言打造了一整套的技术。即便如此,应对分布式应用的规模问题依然不轻松,体现于因为缺乏顶层设计而面临体系性不足,加之对技术产品自身的用户体验缺乏重视,最终导致运维成本和技术门槛都偏高;
3)服务治理手段从过去的框架思维向平台思维转变,平台思维不仅能实现应用与技术基础设施更好的解耦,也能通过平台的聚集效应让体系化的顶层设计有生发之地;
4)框架思维向平台思维转变在执行上集中体现于“轻量化”和“下沉”两个动作。轻量化是指将那些易变的功能从框架的 SDK 中移出,结果是使用了 SDK 的应用变得更轻,从框架中移出的功能放到了 Service Mesh 的 Sidecar 中而实现了功能下沉;
5)ServiceMesh 作为平台性技术将由云厂商去运维和提供相应的产品,通过开源所构建的全球事实标准一旦被所有云厂商采纳并实现产品化输出,那时应用的可移植性问题就能水到渠成地解决;
6)阿里巴巴的电商核心应用基本上都是用 Java 构建的,在 mesh 化之前,RPC 的服务发现与路由是在 SDK 中完成的,为了保证双11 这样的流量洪峰场景下的消费者用户体验,会通过预案对服务地址的变更推送做降级,避免因为频繁推送而造成应用进程出现 Full GC。Mesh 化之后,SDK 的那些功能被放到了 Sidecar(开发语言是 C++)这一独立进程中,这使得 Java 应用进程完全不会出现类似场景下的 Full GC 问题;
7)Service Mesh 使得应用与技术基础设施之间的关系变得更松且稳定,通过流量无损的热升级方案,使得应用与技术基础设施的演进变得独立,从而加速各自的演进效率。软件不成熟、不完善并不可怕,可怕的是演进起来太慢、包袱太重;
8)技术平台的能力需要尽可能地服务化,避免因为服务化不彻底而需要引入 SDK,进而带来多编程语言问题(即因为没有相应编程语言的 SDK 而无法使用该编程语言);
9)在无法规避 SDK 的情形下,让 SDK 变得足够的轻且功能稳定,降低平台化和多编程语言化的工程成本。支持多编程语言 SDK 最好的手段是采用 IDL;
10)有了 Service Mesh 后,以前好些独立的技术产品(比如,服务注册中心、消息系统、配置中心)将变成 BaaS(Backend as a Service)服务,由 Service Mesh 的 Sidecar 负责与它们对接,应用对这些服务的访问通过 Sidecar 去完成,甚至有些 BaaS 服务被 Sidecar 终结而完全对应用无感;
11)未来好些技术产品的竞争优势将体现于它能否与 Service Mesh 形成无缝整合;基于这一认识,阿里巴巴正在将 RocketMQ/MetaQ 消息系统的客户端中的重逻辑剥离到 Envoy 这一 Sidecar 中(思路依然是“下沉”),同时基于 Service Mesh 所提供的能力做一定的技术改造,以便 RocketMQ/MetaQ 能很好地支撑应用的灰度发布;
12)当业务基础技术以插件的形式存在时,业务基础技术无需以独立的进程存在而取得更好的性能,且这一机制也能被不同的业务复用。阿里巴巴的 Service Mesh 技术方案所采用的 Sidecar 开源软件 Envoy 正在积极地探索通过Wasm 技术去实现流量处理的插件机制,将该机制进一步延延成为业务基础技术插件机制是值得探索的内容;
13)就我们与阿里云客户交流的经验来看,他们乐于尽最大可能采用非云厂商所特有的技术方案,以免被技术锁定而在未来的发展上出现掣肘。另外,他们只有采纳开源的事实标准软件才有可能达成企业的多云和混合云战略。基于客户的这一诉求,我们在Service Mesh的技术发展上特别重视参与开源事实标准的共建;
要点提炼:这基本是 ServiceMesh 的布道书,这个方向是对的,是接下来的主攻方向。
09 阿里集团 双11 核心应用落地 Service Mesh 所克服的挑战
方克明,花名溪翁,阿里云中间件技术部技术专家
1)NAT 表所使用到的 nf_contrack 内核模块因为效率很低而在阿里巴巴的线上生产机器中被去除了,因此无法直接使用社区的方案。OS团队探索了通过基于 userid 和 mark 标识流量的透明拦截方案,基于 iptables 的 mangle 表实现了一个全新的透明拦截组件;
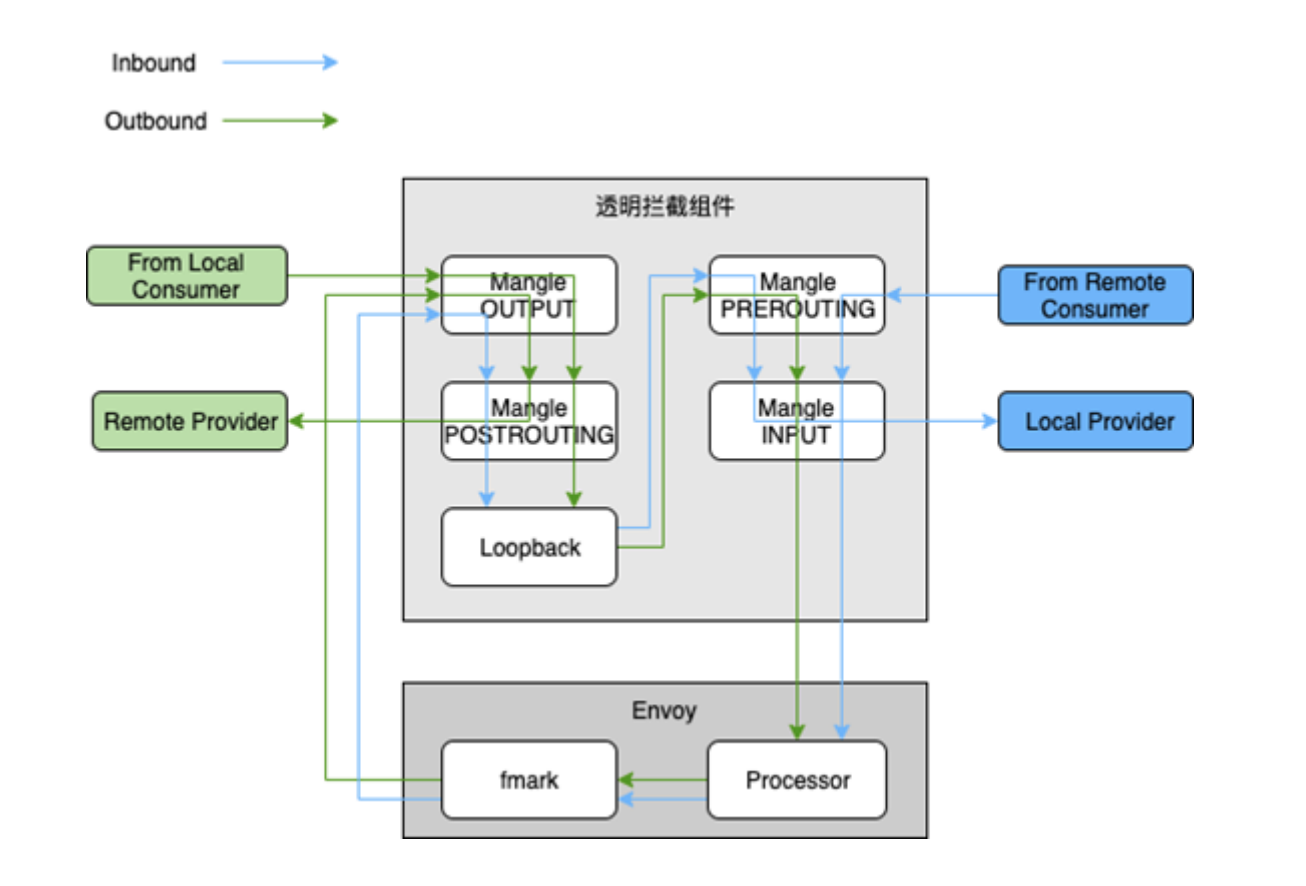
2)由于 RPC 的 SDK 仍存在以前的服务发现和路由逻辑,而该流量被劫持到 Envoy 之后又会再做一次,这将导致 Outbound 的流量会因为存在两次服务发现和路由而增加 RT,以终态落地 Service Mesh 时,需要去除 RPC SDK 中的服务发现与路由逻辑,将相应的 CPU 和内存开销给节约下来;
3)扩展 Istio 原生的 CRD 中的 VirtualService 和 DestinationRule,增加 RPC 协议所需的路由配置段去表达路由策略;
4)未来计划在 Istio/Envoy 的标准路由策略之外,设计一套基于Wasm 的路由插件方案,让那些简单的路由策略以插件的形式存在。如此一来,既减少对标准路由模块的侵入,也在一定程度上满足业务方对服务路由定制的需要;
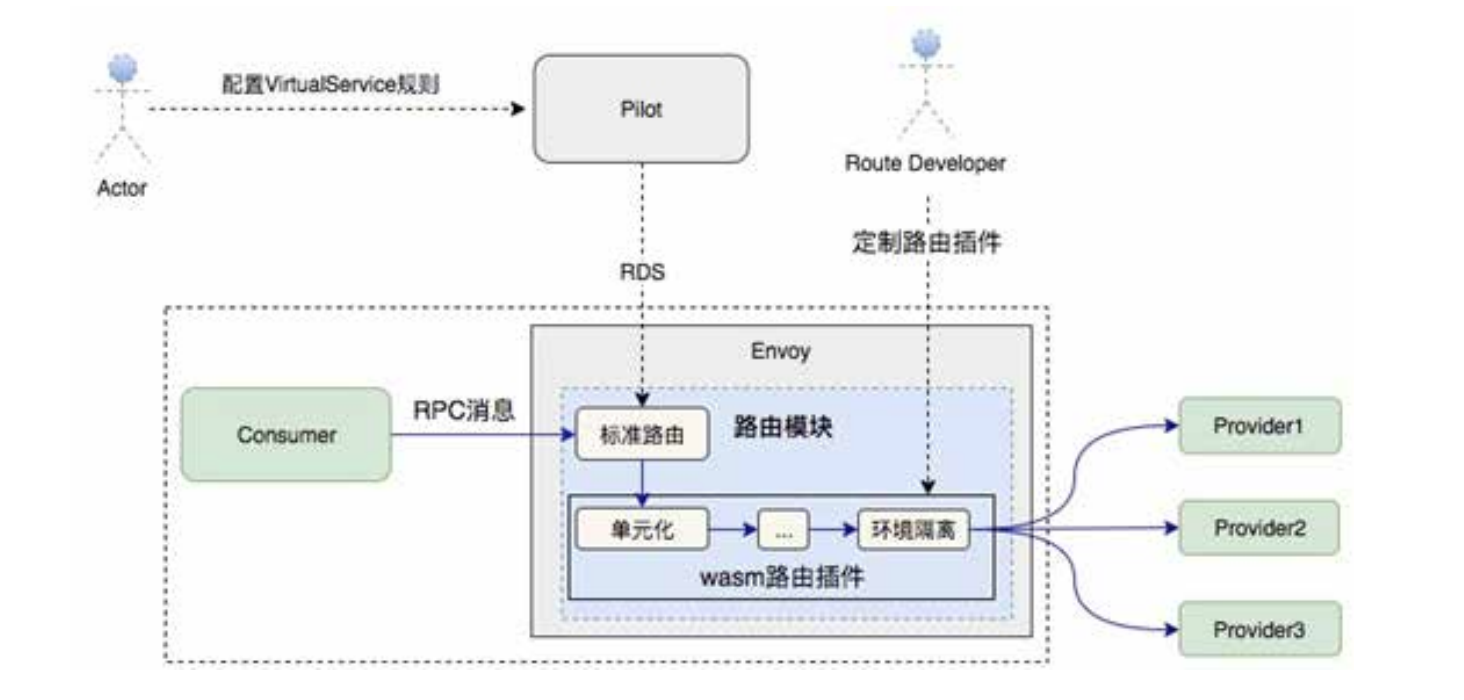
5)出于性能考虑,阿里巴巴内部落地的 Service Mesh 方案并没有采用 Istio 中的 Mixer 组件,限流这块功能借助阿里巴巴内部广泛使用的 Sentinel 组件来实现。整个限流的功能是通过 Envoy 的 Filter 机制来实现的,我们在 Dubbo 协议之上构建了相应的 Filter,限流所需的配置信息则是通过 Pilot 从 Nacos 中获取,并通过 xDS 协议下发到 Envoy 中;
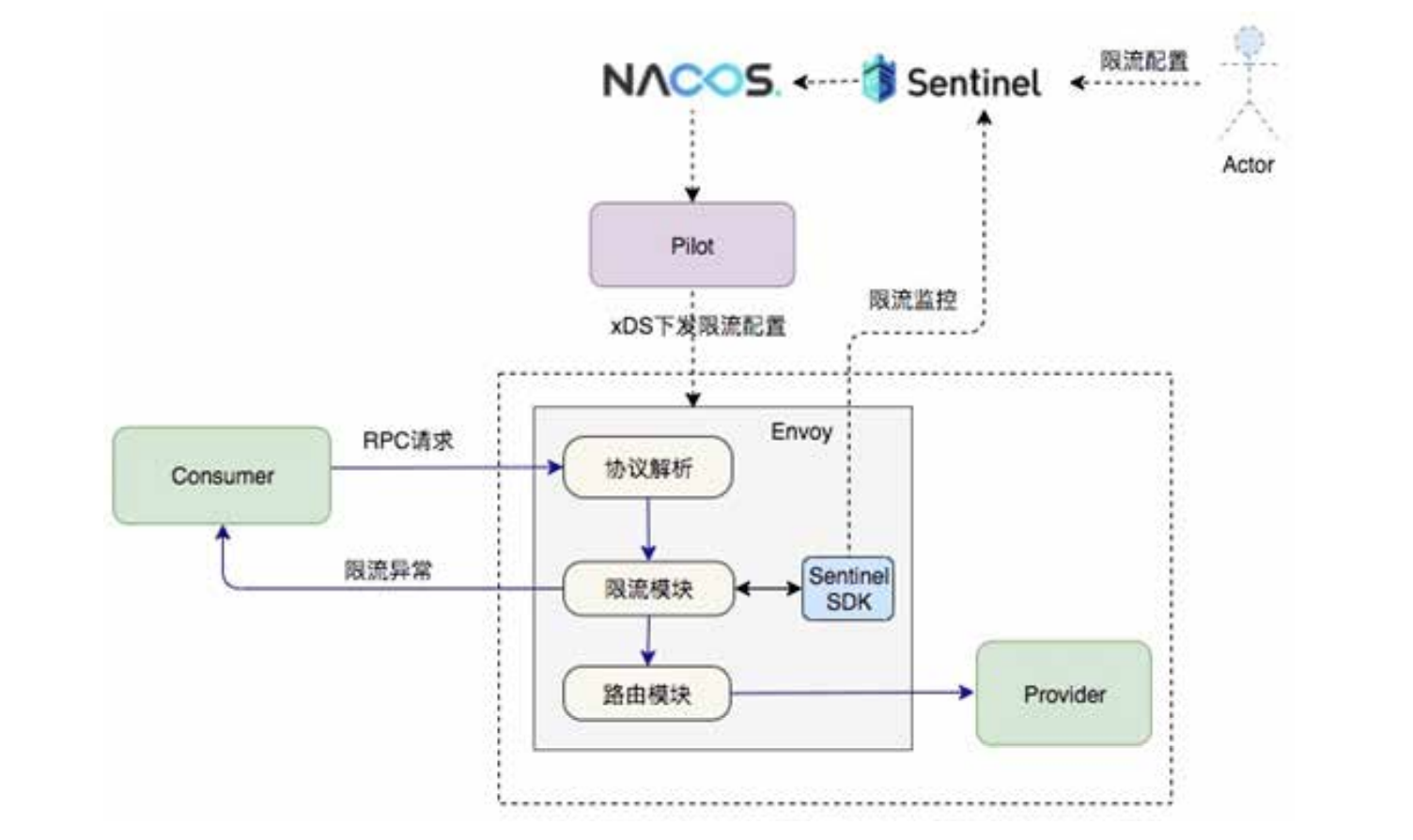
6)给 Envoy 增加了 stats 开关,用于关闭或打开IP 级别的 stats,关闭 IP 级别的 stats 直接带来了内存节约 30% 成果,下一步我们将跟进社区的 stats symbol table 的方案来解决 stats 指标字符串重复的问题,那时的内存开销将进一步减少;
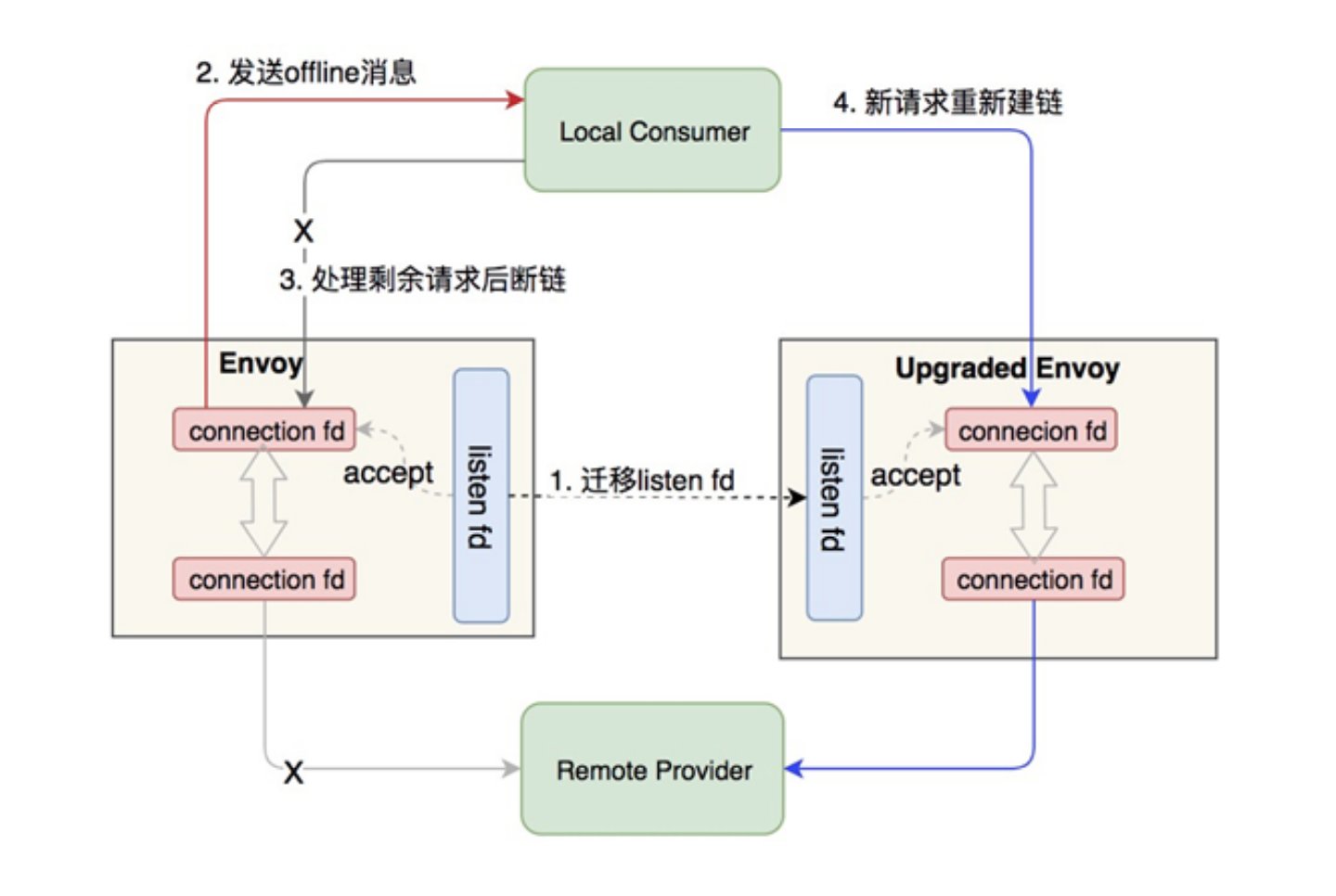
7)热升级采用双进程方案,先拉起新的 Sidecar 容器,由它与旧的 Sidecar 进行运行时数据交接,在新的 Sidecar 准备发接管流量后,让旧的 Sidecar 等待一定时间后退出,最终实现业务流量无损。核心技术主要是运用了 Unix Domain Socket 和 RPC 的节点优雅下线功能:
8)从单机 RT 抽样的角度,部署了 Service Mesh 的某台机器,其 Provider 侧的 RT 均值是 5.6ms,Consumer 侧的是 10.36ms。没有部署 Service Mesh 的某台机器,Provider 侧的均值为 5.34ms,Consumer 侧的则是9.31ms。
9)在 CPU 和内存开销方面,Mesh 化之后,Envoy 所消耗的 CPU 在所有核心应用上都维持在 0.1 核左右,会随着 Pilot 推送数据而产生毛刺。未来需要借助 Pilot 和 Envoy 之间的增量推送去对毛刺做优化。内存的开销随着应用的服务和集群规模不同而存在巨大差异,目前看来 Envoy 在内存的使用上仍存在很大的优化空间。
要点提炼:envoy 于 servicemesh ,相当于 docker 于 kubernetes。
10 蚂蚁金服 双11 Service Mesh 超大规模落地揭秘
黄挺,花名鲁直,蚂蚁金服微服务以及云原生方向负责人
雷志远,花名碧远,蚂蚁金服 RPC 框架负责人
1)在没有 Service Mesh 之前,整个 SOFAStack 技术演进的过程中,框架和业务的结合相当紧密,对于一些 RPC 层面的需求,比如流量调度,流量镜像,灰度引流等,是需要在 RPC 层面进行升级开发支持,同时,需要业务方来升级对应的中间件版本;
要点提炼:这篇文章之前读过,见 蚂蚁金服大规模 ServiceMesh 落地思路和实践经验的 5 篇分享学习总结。
11 服务网格在“路口”的产品思考与实践
宋顺,花名齐天,蚂蚁金服高级技术专家
1)当前很多公司的微服务体系建设都建立在“内网可信”的假设之上,然而这个原则在当前大规模上云的背景下可能显得有点不合时宜,尤其是涉及到一些金融场景的时候;
2)通过 Service Mesh,我们可以更方便地实现应用的身份标识和访问控制,辅之以数据加密,就能实现全链路可信,从而使得服务可以运行于零信任网络中,提升整体安全水位;
3)Mixer 的性能问题,一直都是 Istio 中最被人诟病的地方。尤其在 Istio 1.1/1.2 版本之后引入了 Out-Of-Process Adapter,更是雪上加霜。从落地的角度看,Mixer V1 糟糕至极的性能,已经是“生命无法承受之重”。对于一般规模的生产级落地而言,Mixer 性能已经是难于接受,更不要提大规模落地……
4)Mixer V2 方案则给了社区希望:将 Mixer 合并进 Sidecar,引入 web assembly 进行 Adapter 扩展,这是我们期待的 Mixer 落地的正确姿势,是 Mixer 的未来,是 Mixer 的“诗和远方”。然而社区望穿秋水,但Mixer V2 迟迟未能启动,长期处于 In Review 状态,远水解不了近渴;
5)Pilot 目前主要有两大问题,1、无法支撑海量数据,2、每次变化都会触发全量推送,性能较差;我们的方案是保留独立的 SOFA 服务注册中心来支持千万级的服务实例信息和秒级推送,业务应用通过直连 Sidecar 来实现服务注册和发现;
6)在控制面上,我们引入了Pilot实现配置的下发(如服务路由规则),在服务发现上保留了独立的 SOFA 服务注册中心;
7)在数据面上,我们使用了自研的 SOFAMosn,不仅支持 SOFA 应用,同时也支持 Dubbo 和 Spring Cloud 应用;
8)sidecar 代理服务调用的过程:
1. 假设服务端运行在 1.2.3.4 这台机器上,监听 20880 端口,首先服务端会向自己的 Sidecar 发起
服务注册请求,告知 Sidecar 需要注册的服务以及 IP + 端口(1.2.3.4:20880);
2. 服务端的 Sidecar 会向 SOFA 服务注册中心发起服务注册请求,告知需要注册的服务以及 IP + 端
口,不过这里需要注意的是注册上去的并不是业务应用的端口(20880),而是 Sidecar 自己监听的
一个端口(例如:20881);
3. 调用端向自己的 Sidecar 发起服务订阅请求,告知需要订阅的服务信息;
4. 调用端的 Sidecar 向调用端推送服务地址,这里需要注意的是推送的 IP 是本机,端口是调用端的
Sidecar 监听的端口(例如:20882);
5. 调用端的 Sidecar 会向 SOFA 服务注册中心发起服务订阅请求,告知需要订阅的服务信息;
6. SOFA 服务注册中心向调用端的 Sidecar 推送服务地址(1.2.3.4:20881);
9)对于先迁移调用方还是先迁移服务方没有任何要求,这里假设调用方希望先迁移到Service Mesh 上,那么只要在调用方开启 Sidecar 的注入即可,服务方完全不感知调用方是否迁移了。假设服务方希望先迁移到 Service Mesh 上,那么只要在服务方开启 Sidecar 的注入即可,调用方完全不感知服务方是否迁移了;
10)考虑到目前大部分用户的使用场景,除了 SOFA 应用,我们同时也支持 Dubbo 和 Spring Cloud 应用接入SOFAStack 双模微服务平台,提供统一的服务治理。多协议支持采用通用的 x-protocol,未来也可以方便地支持更多协议。
要点提炼: istio 当前存在的问题需要特别注意。
12 CSE:Serverless 在阿里巴巴 双11 场景的落地
1)大多数在线业务的启动时间都在分钟级,甚至有的达到 30 分钟。在线业务一般基于HSF 和潘多拉框架进行研发,同时会依赖大量的中间件富客户端以及其它部门提供的二方包,启动过程中包含了大量的初始化工作,比如网络连接、缓存加载、配置加载等;
2)Zizz 方案以不到原有 1/10 的资源保有低功耗态的实例,并在有需要的时候在秒级别恢复到在线态,相比冷启动的分钟级时间,提升了两个数量级;Zizz 方案核心是热备(Standby),假设是离线的实例功耗非常低;
3)CSE Zizz 研发了几种核心技术,将这几种核心技术进行包装,通过 Kubernetes 自定义 CRD 的方式以 K8s 工作负载的方式进行能力输出;
一种基于弹性堆的低功耗技术;
基于内核态和用户态的 Swap 能力的内存弹性技术;
基于 Inplace Update 的实例规格动态升降配技术。
4)进入低功耗模式,我们会对实例的资源配置进行降级; 针对 CPU 资源,我们维护一个低功耗 CPU Pool(CPU Set),CPU Pool 初始值是 1C,会随着加入这个 CPU Pool 中低功耗实例的数量,增加其 CPU Core 的数量,这样同一个 Node 上的多个低功耗实例争抢一个 CPUPool 中的资源;
5)目前 Linux swap 设计和实现更多的是面向系统内存 Overcommit,其内存换入的实现更多偏向于 Lazy 方式基于 Page 粒度的内存访问形式,这种内存换入的方式在真实的业务系统中会造成 RT 抖动,在商业系统中是不可接受的;
6)针对传统 Linux Swap,我们利用用户态编程,并发实现快速 Swap In, 在不同存储介质上,能够达到其最大 IO Throughput;
7)CSE Zizz 方案利用 AJDK Elastic Heap 技术,使其作为 Java 应用实例低功耗运行的基础;Elastic Heap 技术能够有效避免 Full GC 对 JVM Heap 区域及关联内存区域的大面积访问,只对局部 Heap 区域的快速内存回收实现了低功耗运行,只使用相对较小的 Working Set Size 内存,避免了传统 Java 运行时堆区内存快速扩张对 Swap 子系统造成的压力,有效减轻了系统 IO 负载;
8)CSE Zizz 方案利用 AJDK 提供 Elastic Heap 的特性和相关命令,在没有请求流量的情况下, 使运行实例进入低功耗状态,使运行实例在低功耗状态下保持极低运行 Memory Footprint;
9)AJDK Elastic Heap 技术能够保障目标评估应用实例在长达 32 小时的测试中,WSS 稳定在500~600M;使用 Elastic Heap 技术,结合 Swap 可以为 Java 应用实例提供非常稳定的低功耗运行时、能够使运行实例在低功耗状态下维持极低运行 Memory Footprint 和 WSS,有效降低了存量应用低功耗运行的内存和 IO 成本;
10)Zizz 方案 Swap 存储全面使用阿里云 ESSD 存储服务;
11)CSE Fn 架构里的所有组件相互间的网络通信使用了 RSocket 协议:它是新一代、跨语言且基于 Reactive 编程模型的开源通讯框架;
12)用户 Fn 流量归零之后,CSE 的弹性模块会基于 ginkgo broker 上报的 metrics 数据,计算出当前用户 Fn 已无存在必要,可以进入缩零流程,在缩零静默期内(缩零静默期主要用于解决短时流量波动造成的不必要反复缩零拉起的过程),Fn 至少保留 1 个实例,期间任何流量进入都会触发退出缩零流程;
13)缩零静默期满后,CSE 的弹性模块会下发缩零指令,触发 K8s 底层 pod 资源全数释放;
14)CSE 的预发环境设置了默认 6 小时的缩零静默期。这样在用户不再使用 Fn 的 6 小时之后,系统会自动全数回收 Fn 占据的物理资源,为其他玩家空出场地继续玩耍;
15)提升零实例拉起的速度,整合 CSE Zizz 极速启动技术,逐步向极速启动方向靠拢;
16)CSE Fn 业务方反馈,新扩容的实例在启动后 30-60s 内 cpu 飙高,超时错误骤增。排查后可以确认是运维组件 staragent 在启动后更新插件的行为抢占了 cpu,导致业务进程无法及时响应请求
17)在剥离运维 sidecar 的过程中,我们解决了如下问题:
1.资源隔离及 QoS:给 sidecar 分配合适的资源并保证与业务容器资源隔离;
2.CMDB 集成:将原本业务容器内汇报 cmdb 数据的逻辑剥离到 sidecar;
3.系统监控:将原本基于系统 metrics 日志的监控转换到 K8s 的 Node 上报采集;
4.日志采集:剥离日志采集 agent 到 sidecar,打通业务容器和 sidecar 的日志文件共享;
5.Web Terminal:将 Web Terminal 功能剥离到 sidecar。
13 解密双11 小程序云背后毫秒级伸缩的Serverless 计算平台:函数计算
吴天龙,花名木吴,阿里云函数计算技术专家
1)当用户创建函数上传代码时,函数计算只是将代码包保存到 OSS,并没有分配计算资源,因此函数计算可以支撑海量的小程序。当函数第一次被调用时,函数计算会分配计算资源、下载函数代码、加载并执行代码,函数计算通过大量的优化,将系统侧的冷启动时间优化到 200ms 以内;
2)函数计算的“资源调度”模块,会精确管理每个实例的状态,当请求到来时,它首先检查是否有空闲的实例可以服务,如果没有请求就会进入等待队列,当有空闲的实例释放出来时,请求就能够被及时处理;
3)调度器还会在后台创建新的实例,当新的实例准备好后,也能够服务请求。在这种策略下,能够做到在负载以 2 倍的速度增长情况下,请求的 P95 延时是稳定的;
4)对于一些“秒杀”的场景,要求瞬间提供大量的计算资源。此时靠实时的弹性伸缩是不够的:一是冷启动的时间即使是 200ms,对于秒杀场景也太慢了;二是底层的计算资源在扩容时也会有流控。针对这种场景,函数计算提供了预留实例的功能;
核心要点:关键是实例的快速启动。
14 双11 背后的全链路可观测性:阿里巴巴鹰眼在“云原生时代”的全面升级
1)“可观测性”的终极目标是为一个复杂分布式系统所发生的一切给出合理解释;
2)一个交易系统会同时承载天猫、盒马、大麦、飞猪等多种类型的业务,而每种业务的预期调用量、下游依赖路径等均不相同,作为交易系统的负责人,很难梳理清楚每种业务的上下游细节逻辑对自身系统的影响;
完整 PDF 文件下载
《阿里巴巴经济体云原生实践》下载方法,关注微信公众号「我的网课」,回复「阿里网格」。
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文