Kubernetes 容器启动失败: unable to create nf_conn slab cache
目录
现象
kubernetes集群的一台node上容器启动失败,日志显示:
Nov 12 15:15:41 slave-138 dockerd: time="2017-11-12T15:15:41.523932697+08:00" level=error msg="containerd: start container"
error="oci runtime error: container_linux.go:247: starting container process caused \"process_linux.go:245: running exec
setns process for init caused \\\"exit status 6\\\"\"\n" id=64bec16ba46d3973a0475cdc55a196381195d69bc73d2248e81a56bce1e12f0d
Nov 12 15:15:41 slave-138 dockerd: time="2017-11-12T15:15:41.656807742+08:00" level=error msg="Create container failed with error:
invalid header field value \"oci runtime error: container_linux.go:247: starting container process caused \\\"process_linux.go:245:
running exec setns process for init caused \\\\\\\"exit status 6\\\\\\\"\\\"\\n\""
直接docker run也报错:
docker: Error response from daemon: invalid header field value "oci runtime error: container_linux.go:247:
starting container process caused \"process_linux.go:245: running exec setns process for init caused \\\"exit status 6\\\"\"\n".
查看系统日志,发现在容器启动失败的日志之前,kernel报错:
Nov 12 15:15:41 kernel: exe: page allocation failure: order:6, mode:0x10c0d0
Nov 12 15:15:41 kernel: CPU: 1 PID: 18377 Comm: exe Not tainted 3.10.0-514.el7.x86_64 #1
Nov 12 15:15:41 kernel: Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.8.2-0-g33fbe13 by qemu-project.org 04/01/2014
Nov 12 15:15:41 kernel: 000000000010c0d0 000000006565c63b ffff8803f7f8b928 ffffffff81685fac
Nov 12 15:15:41 kernel: ffff8803f7f8b9b8 ffffffff811869a0 0000000000000000 00000000ffffffff
Nov 12 15:15:41 kernel: ffffffffffffffc0 0010c0d000000000 ffff8803f7f8b988 000000006565c63b
Nov 12 15:15:41 kernel: Call Trace:
Nov 12 15:15:41 kernel: [<ffffffff81685fac>] dump_stack+0x19/0x1b
Nov 12 15:15:41 kernel: [<ffffffff811869a0>] warn_alloc_failed+0x110/0x180
Nov 12 15:15:41 kernel: [<ffffffff81681b40>] __alloc_pages_slowpath+0x6b7/0x725
Nov 12 15:15:41 kernel: [<ffffffff8118af55>] __alloc_pages_nodemask+0x405/0x420
Nov 12 15:15:41 kernel: [<ffffffff811cf10a>] alloc_pages_current+0xaa/0x170
Nov 12 15:15:41 kernel: [<ffffffff8118587e>] __get_free_pages+0xe/0x50
Nov 12 15:15:41 kernel: [<ffffffff811da9ae>] kmalloc_order_trace+0x2e/0xa0
Nov 12 15:15:41 kernel: [<ffffffff811dd181>] __kmalloc+0x221/0x240
Nov 12 15:15:41 kernel: [<ffffffff811f3bb9>] memcg_register_cache+0xb9/0xe0
Nov 12 15:15:41 kernel: [<ffffffff811a5bc0>] kmem_cache_create_memcg+0x110/0x230
Nov 12 15:15:41 kernel: [<ffffffff811a5d0b>] kmem_cache_create+0x2b/0x30
Nov 12 15:15:41 kernel: [<ffffffffa03719e1>] nf_conntrack_init_net+0x101/0x250 [nf_conntrack]
Nov 12 15:15:41 kernel: [<ffffffffa03722b4>] nf_conntrack_pernet_init+0x14/0x150 [nf_conntrack]
Nov 12 15:15:41 kernel: [<ffffffff81567061>] ops_init+0x41/0x150
Nov 12 15:15:41 kernel: [<ffffffff81567213>] setup_net+0xa3/0x160
Nov 12 15:15:41 kernel: [<ffffffff81567bcc>] copy_net_ns+0x7c/0x130
Nov 12 15:15:41 kernel: [<ffffffff810b56a9>] create_new_namespaces+0xf9/0x180
Nov 12 15:15:41 kernel: [<ffffffff810b584e>] copy_namespaces+0x8e/0xd0
Nov 12 15:15:41 kernel: [<ffffffff81083a39>] copy_process+0xb69/0x1960
Nov 12 15:15:41 kernel: [<ffffffff810849e1>] do_fork+0x91/0x2c0
Nov 12 15:15:41 kernel: [<ffffffff81691e76>] ? trace_do_page_fault+0x56/0x150
Nov 12 15:15:41 kernel: [<ffffffff81084c96>] SyS_clone+0x16/0x20
Nov 12 15:15:41 kernel: [<ffffffff81696919>] stub_clone+0x69/0x90
Nov 12 15:15:41 kernel: [<ffffffff816965c9>] ? system_call_fastpath+0x16/0x1b
Nov 12 15:15:41 kernel: Mem-Info:
Nov 12 15:15:41 kernel: active_anon:44762 inactive_anon:52333 isolated_anon:26#012 active_file:13358 inactive_file:10581 isolated_file:0#012 unevictable:103032
dirty:2 writeback:130 unstable:0#012 slab_reclaimable:1935137 slab_unreclaimable:1709086#012 mapped:17698 shmem:1682 pagetables:5134
bounce:0#012 free:113585 free_pcp:39 free_cma:0
Nov 12 15:15:41 kernel: Node 0 DMA free:15908kB min:64kB low:80kB high:96kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB
isolated(anon):0kB isolated(file):0kB present:15992kB managed:15908kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB
slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0
all_unreclaimable? yes
Nov 12 15:15:41 kernel: lowmem_reserve[]: 0 2815 15868 15868
Nov 12 15:15:41 kernel: Node 0 DMA32 free:127248kB min:11976kB low:14968kB high:17964kB active_anon:39688kB inactive_anon:44380kB active_file:15904kB inactive_file:11940kB
unevictable:95756kB isolated(anon):0kB isolated(file):0kB present:3129212kB managed:2884472kB mlocked:95756kB dirty:0kB writeback:0kB mapped:20416kB
shmem:1648kB slab_reclaimable:1324384kB slab_unreclaimable:1154192kB kernel_stack:17904kB pagetables:2156kB unstable:0kB bounce:0kB free_pcp:0kB
local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
Nov 12 15:15:41 kernel: lowmem_reserve[]: 0 0 13053 13053
Nov 12 15:15:41 kernel: Node 0 Normal free:311184kB min:55536kB low:69420kB high:83304kB active_anon:139360kB inactive_anon:164952kB active_file:37528kB inactive_file:30384kB
unevictable:316372kB isolated(anon):104kB isolated(file):0kB present:13631488kB managed:13367020kB mlocked:316372kB dirty:8kB writeback:520kB mapped:50376kB
shmem:5080kB slab_reclaimable:6416164kB slab_unreclaimable:5682152kB kernel_stack:10752kB pagetables:18380kB unstable:0kB bounce:0kB free_pcp:128kB
local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
Nov 12 15:15:41 kernel: lowmem_reserve[]: 0 0 0 0
Nov 12 15:15:41 kernel: Node 0 DMA: 1*4kB (U) 0*8kB 0*16kB 1*32kB (U) 2*64kB (U) 1*128kB (U) 1*256kB (U) 0*512kB 1*1024kB (U) 1*2048kB (M) 3*4096kB (M) = 15908kB
Nov 12 15:15:41 kernel: Node 0 DMA32: 19160*4kB (UEM) 6346*8kB (UEM) 35*16kB (EM) 7*32kB (E) 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 128192kB
Nov 12 15:15:41 kernel: Node 0 Normal: 34178*4kB (UEM) 20118*8kB (UEM) 412*16kB (UEM) 115*32kB (EM) 46*64kB (M) 6*128kB (M) 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 311640kB
Nov 12 15:15:41 kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB
Nov 12 15:15:41 kernel: 60360 total pagecache pages
Nov 12 15:15:41 kernel: 29539 pages in swap cache
Nov 12 15:15:41 kernel: Swap cache stats: add 8922382205, delete 8922352666, find 1750511960/2933948954
Nov 12 15:15:41 kernel: Free swap = 13589108kB
Nov 12 15:15:41 kernel: Total swap = 16777212kB
Nov 12 15:15:41 kernel: 4194173 pages RAM
Nov 12 15:15:41 kernel: 0 pages HighMem/MovableOnly
Nov 12 15:15:41 kernel: 127323 pages reserved
Nov 12 15:15:41 kernel: kmem_cache_create(nf_conntrack_ffff8803eef66180) failed with error -12
Nov 12 15:15:41 kernel: CPU: 1 PID: 18377 Comm: exe Not tainted 3.10.0-514.el7.x86_64 #1
Nov 12 15:15:41 kernel: Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.8.2-0-g33fbe13 by qemu-project.org 04/01/2014
Nov 12 15:15:41 kernel: ffff8803072e51c0 000000006565c63b ffff8803f7f8bc60 ffffffff81685fac
Nov 12 15:15:41 kernel: ffff8803f7f8bcb0 ffffffff811a5c12 0000000000080000 0000000000000000
Nov 12 15:15:41 kernel: 00000000fffffff4 ffff8803eef66180 ffffffff81ae2340 ffff8803eef66180
Nov 12 15:15:41 kernel: Call Trace:
Nov 12 15:15:41 kernel: [<ffffffff81685fac>] dump_stack+0x19/0x1b
Nov 12 15:15:41 kernel: [<ffffffff811a5c12>] kmem_cache_create_memcg+0x162/0x230
Nov 12 15:15:41 kernel: [<ffffffff811a5d0b>] kmem_cache_create+0x2b/0x30
Nov 12 15:15:41 kernel: [<ffffffffa03719e1>] nf_conntrack_init_net+0x101/0x250 [nf_conntrack]
Nov 12 15:15:41 kernel: [<ffffffffa03722b4>] nf_conntrack_pernet_init+0x14/0x150 [nf_conntrack]
Nov 12 15:15:41 kernel: [<ffffffff81567061>] ops_init+0x41/0x150
Nov 12 15:15:41 kernel: [<ffffffff81567213>] setup_net+0xa3/0x160
Nov 12 15:15:41 kernel: [<ffffffff81567bcc>] copy_net_ns+0x7c/0x130
Nov 12 15:15:41 kernel: [<ffffffff810b56a9>] create_new_namespaces+0xf9/0x180
Nov 12 15:15:41 kernel: [<ffffffff810b584e>] copy_namespaces+0x8e/0xd0
Nov 12 15:15:41 kernel: [<ffffffff81083a39>] copy_process+0xb69/0x1960
Nov 12 15:15:41 kernel: [<ffffffff810849e1>] do_fork+0x91/0x2c0
Nov 12 15:15:41 kernel: [<ffffffff81691e76>] ? trace_do_page_fault+0x56/0x150
Nov 12 15:15:41 kernel: [<ffffffff81084c96>] SyS_clone+0x16/0x20
Nov 12 15:15:41 kernel: [<ffffffff81696919>] stub_clone+0x69/0x90
Nov 12 15:15:41 kernel: [<ffffffff816965c9>] ? system_call_fastpath+0x16/0x1b
Nov 12 15:15:41 kernel: Unable to create nf_conn slab cache
可以看到,两次Call Trace都与nf_conntrack有关。第一次Call Trace的后面打印出了Mem-info,但是里面的很多参数,搞不清楚它们的含义。 只能揣测可能是与nf_conntrack相关的某个内核参数设置的数值过小,可能是与kernel memory相关的。
内核版本:
$ uname -a
Linux 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
调查
因为对kernel不熟悉,所以调查的过程有些曲折,可以跳过前两个阶段,直接阅读第三阶段。
第一阶段
用slabtop命令查看kernel memory的使用情况:
$ slabtop
Active / Total Objects (% used) : 20249375 / 55224275 (36.7%)
Active / Total Slabs (% used) : 1658442 / 1658442 (100.0%)
Active / Total Caches (% used) : 90 / 117 (76.9%)
Active / Total Size (% used) : 4484258.20K / 14550298.17K (30.8%)
Minimum / Average / Maximum Object : 0.01K / 0.26K / 8.00K
从 Slab Allocator 中得知:
相同类型的 object 存放在内存页中,连续的内存页组成 slab,slab 组成 cache。
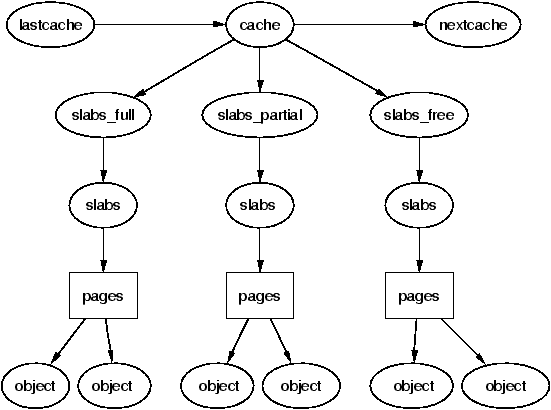
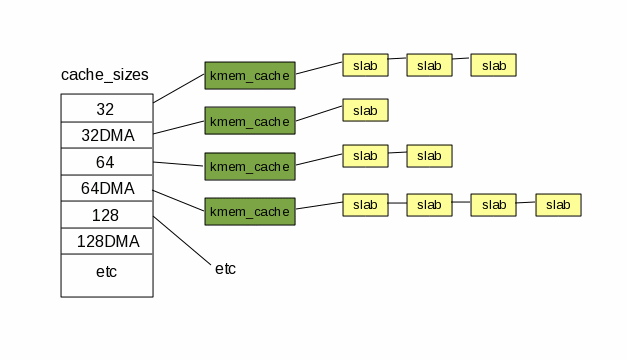
Overview of Linux Memory Management Concepts: Slabs 提供了一张很易懂的图片:
Very high SLAB usage, hard to understand 中遇到了 slab 占用过多问题,提供了一些参考,但是他的问题是文件系统的 bug 导致的,与我遇到情况不相同。
查看 cache 中的 slab 数量,slabtop -s l显示的第五列:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
10676412 10490318 98% 0.11K 296567 36 1186268K sysfs_dir_cache
4815902 2098260 43% 0.57K 172034 28 2752544K radix_tree_node
2928870 899041 30% 0.19K 139470 21 557880K dentry
3538678 1170532 33% 0.15K 136103 26 544412K xfs_ili
3735918 869053 23% 1.06K 125589 30 4018848K xfs_inode
2595221 601111 23% 0.38K 123583 21 988664K blkdev_requests
2314305 505786 21% 0.19K 110205 21 440820K kmalloc-192
3513384 1402714 39% 0.09K 83652 42 334608K kmalloc-96
2614312 6459 0% 0.50K 81707 32 1307312K kmalloc-512
2447456 19151 0% 0.25K 76491 32 611928K kmalloc-256
4804416 98044 2% 0.06K 75069 64 300276K kmalloc-64
1941310 5005 0% 0.23K 55466 35 443728K cfq_queue
查看其它能正常创建容器的 node 的状态,发现 slab 的使用情况也是 100%,因此将 slab 使用率 100% 的影响排除。
不过为什么slab都保持在100%呢?这个问题以后再研究。
第二阶段
第一阶段的调查受挫,继续调查,查看 node 的 /proc/slabinfo 发现了不同。
出现问题的 node 上的以 nf_conntrack 开头的 cache 总共有 8 个:
$ slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
nf_conntrack_ffff8803f0b7ba80 25 25 320 25 2 : tunables 0 0 0 : slabdata 1 1 0
nf_conntrack_ffff8802e47f3a80 1575 1625 320 25 2 : tunables 0 0 0 : slabdata 65 65 0
nf_conntrack_ffff8803eef64e00 400 400 320 25 2 : tunables 0 0 0 : slabdata 16 16 0
nf_conntrack_ffff8803eef61380 0 0 320 25 2 : tunables 0 0 0 : slabdata 0 0 0
nf_conntrack_ffff880360a04e00 0 0 320 25 2 : tunables 0 0 0 : slabdata 0 0 0
nf_conntrack_ffff8803eef63a80 1350 1350 320 25 2 : tunables 0 0 0 : slabdata 54 54 0
nf_conntrack_ffff8803ff2bce00 375 375 320 25 2 : tunables 0 0 0 : slabdata 15 15 0
nf_conntrack_ffff8802e47f6180 925 1000 320 25 2 : tunables 0 0 0 : slabdata 40 40 0
而没有问题的node上slab同样使用了100%,但是它的nf_conntrack_XXX只有3个:
$ slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
nf_conntrack_ffff8801fda48000 125 125 320 25 2 : tunables 0 0 0 : slabdata 5 5 0
nf_conntrack_ffff8801fda4ce00 825 825 320 25 2 : tunables 0 0 0 : slabdata 33 33 0
nf_conntrack_ffff8800a4afa700 0 0 320 25 2 : tunables 0 0 0 : slabdata 0 0 0
追查 netfilter 的内核参数 Documentation/networking/nf_conntrack-sysctl.txt,没有收获。
/proc/sys/net/netfilter
下载 3.10 的内核代码,在linux-3.10.108/mm/slab_common.c的168行找到kmem_cache_create_memcg的实现,除了得知返回-ENOMEM的错误之外,没有更多收获。
...
err = ENOMEM
...
if (err) {
if (flags & SLAB_PANIC)
panic("kmem_cache_create: Failed to create slab '%s'. Error %d\n",
name, err);
else {
printk(KERN_WARNING "kmem_cache_create(%s) failed with error %d",
name, err);
dump_stack();
}
return NULL;
}
会不会是内核认为已经没有内存可以分配了呢?
再次回去查看日志:
Nov 12 15:15:41 kernel: Node 0 Normal free:311184kB min:55536kB low:69420kB high:83304kB active_anon:139360kB inactive_anon:164952kB active_file:37528kB inactive_file:30384kB
unevictable:316372kB isolated(anon):104kB isolated(file):0kB present:13631488kB managed:13367020kB mlocked:316372kB dirty:8kB writeback:520kB mapped:50376kB
shmem:5080kB slab_reclaimable:6416164kB slab_unreclaimable:5682152kB kernel_stack:10752kB pagetables:18380kB unstable:0kB bounce:0kB free_pcp:128kB
local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
发现其中有一个 slab_reclaimable:6416164kB,有没有办法回收呢?尝试到 vm 的内核参数中找回收方法。
在Documentation/sysctl/vm.txt中搜索 reclaim,找到下面几个与内存回收相关的参数:
drop_caches
zone_reclaim_mode:
进行如下操作:
echo 2 > /proc/sys/vm/drop_caches
echo 4 > /proc/sys/vm/zone_reclaim_mode
然后运行容器,但是发现只是偶尔能够启动,怀疑容器启动成功是因为恰好有内存被回收了。
但为什么 free -h 显示还有很多内存空余?slab 和 free 看到的内存有什么区别?
$free -h
total used free shared buff/cache available
Mem: 15G 1.0G 469M 14M 14G 7.6G
Swap: 15G 2.1G 13G
第三阶段
在 LDD3,chapter8 Allocating Memory 中了解了一下 kmalloc 的原理,可以得知:
kmalloc 获得的是连续的物理内存。
kernel 至少会感知到 3 个 memory zone: DMA-capable memory、normal memory、high memory。
System unable to allocate memory even though memory is available 中遇到了同样的问题,从/proc/buddyinfo 中查看内存信息:
$cat /proc/buddyinfo
Node 0, zone DMA 1 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 8409 8079 1340 74 6 0 0 0 0 0 0
Node 0, zone Normal 40153 12774 302 17 0 0 0 0 0 0 0
在 Documentation/filesystems/proc.txt 中搜索 buddyinfo,得知了上面各列的含义:
$ cat /proc/buddyinfo
Node 0, zone DMA 0 4 5 4 4 3 ...
Node 0, zone Normal 1 0 0 1 101 8 ...
Node 0, zone HighMem 2 0 0 1 1 0 ...
...
Each column represents the number of pages of a certain order which are
available. In this case, there are 0 chunks of 2^0*PAGE_SIZE available in
ZONE_DMA, 4 chunks of 2^1*PAGE_SIZE in ZONE_DMA, 101 chunks of 2^4*PAGE_SIZE
available in ZONE_NORMAL, etc...
也就是说,在我环境中,在Normal zone中,可以分配的连续内存内存页最多 8个(2的三次方),到另一台可以正常启动容器的机器上,发现了明显的不同:
$ cat /proc/buddyinfo
Node 0, zone DMA 1 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 575 1361 326 105 159 533 203 124 47 0 0
Node 0, zone Normal 108 1708 952 1064 957 690 285 145 12 1 0
对比一下,可以发现无法启动容器的机器上,空余的内存几乎都是碎片:4万个单页(page),1.2万个双页(2page)。而正常的机器上单页很少,108个。
结合评论中内容,得 知道 kernel 日志中的下面内容是,CPU(Node0) 的三个 memory zone 的状态:
...
Nov 12 15:15:41 kernel: Node 0 DMA free:15908kB min:64kB low:80kB high:96kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB
isolated(anon):0kB isolated(file):0kB present:15992kB managed:15908kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB
slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0
all_unreclaimable? yes
...
Nov 12 15:15:41 kernel: Node 0 DMA32 free:127248kB min:11976kB low:14968kB high:17964kB active_anon:39688kB inactive_anon:44380kB active_file:15904kB inactive_file:11940kB
unevictable:95756kB isolated(anon):0kB isolated(file):0kB present:3129212kB managed:2884472kB mlocked:95756kB dirty:0kB writeback:0kB mapped:20416kB
shmem:1648kB slab_reclaimable:1324384kB slab_unreclaimable:1154192kB kernel_stack:17904kB pagetables:2156kB unstable:0kB bounce:0kB free_pcp:0kB
local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
...
Nov 12 15:15:41 kernel: Node 0 Normal free:311184kB min:55536kB low:69420kB high:83304kB active_anon:139360kB inactive_anon:164952kB active_file:37528kB inactive_file:30384kB
unevictable:316372kB isolated(anon):104kB isolated(file):0kB present:13631488kB managed:13367020kB mlocked:316372kB dirty:8kB writeback:520kB mapped:50376kB
shmem:5080kB slab_reclaimable:6416164kB slab_unreclaimable:5682152kB kernel_stack:10752kB pagetables:18380kB unstable:0kB bounce:0kB free_pcp:128kB
local_pcp:0kB free_cma:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
kernel:min_free_kbytes 中介绍了 min_free_kbytes 的含义,根据其中的讲述,可以排除 min_free_kbytes 的影响。
最后,问题的提问者调查发现,这可能是一个kernel bug:
Further investigation indicates that I'm probably hitting this kernel bug: OOM but no swap used. – Mark Feb 24 at 21:36
For anyone else who's experiencing this issue, the bug appears to have been fixed somewhere between 4.9.12 and 4.9.18.
– Mark Apr 11 at 20:23
有没有办法减少内存碎片呢?
第四阶段
在 Documentation/sysctl/vm.txt 搜索fragment,发现了一个参数:
extfrag_threshold:
This parameter affects whether the kernel will compact memory or direct
reclaim to satisfy a high-order allocation.
/sys/kernel/debug/extfrag/extfrag_index 记录了每个 zone 的不同大小的内存的 index 数值,数值在 0~1000 之间变化:
- 趋于 0 ,内存分配可能由于内存不足而分配失败;
- 接近 1000,内存分配可能由于碎片太多而失败;
- -1,只要没有遇到 watermarks 就一定分配成功。
/proc/sys/vm/extfrag_threshold 约定了进行内存整理的时机,index 数值超过 extfrag_threshold 的时候,进行内存整理。
$ cat /sys/kernel/debug/extfrag/extfrag_index
Node 0, zone DMA -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000
Node 0, zone DMA32 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 0.970 0.985 0.993 0.997 0.999
Node 0, zone Normal -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 0.990 0.995 0.998 0.999
$ cat /proc/sys/vm/extfrag_threshold
500
在 Documentation/sysctl/vm.txt 搜索 compatc,发现了 compat_memory:
compact_memory
Available only when CONFIG_COMPACTION is set. When 1 is written to the file,
all zones are compacted such that free memory is available in contiguous
blocks where possible. This can be important for example in the allocation of
huge pages although processes will also directly compact memory as required.
查看内核配置文件,已经设置了 CONFIG_COMPACTION:
$ cat /boot/config-3.10.0-514.el7.x86_64 |grep CONFIG_COMPACTION
CONFIG_COMPACTION=y
lwn.net: Memory compaction 中探讨了 memory compaction 的问题,System-wide Memory Defragmenter Without Killing any application 中做了更详细的介绍。
尝试修改内核参数 /proc/sys/vm/compact_memory,奇怪的是没有权限读取这个参数,但是可以设置:
echo 1 >/proc/sys/vm/compact_memory
设置之后,内存碎片的问题得到了一定程度的缓解:
$ cat /proc/buddyinfo
Node 0, zone DMA 1 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 6785 7725 1232 104 0 0 0 0 0 0 0
Node 0, zone Normal 31163 14197 1102 88 27 22 1 0 0 0 0
但是依然不能保证容器每次都可以运行成功,要彻底解决,只能调查一下是哪些进程因为什么导致了大量的碎片。
对这个问题还是一知半解,上面的记录只供参考
参考
- Slab Allocator
- Overview of Linux Memory Management Concepts: Slabs
- Very high SLAB usage, hard to understand
- Documentation/networking/nf_conntrack-sysctl.txt
- Documentation/sysctl/vm.txt
- LDD3,chapter8 Allocating Memory
- System unable to allocate memory even though memory is available
- kernel:min_free_kbytes
- Documentation/filesystems/proc.txt
- lwn.net: Memory compaction
- System-wide Memory Defragmenter Without Killing any application

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文