Kubernetes 集群中个别 Pod 的 CPU 使用率异常高的问题调查
本篇目录
说明
隶属于同一个 Deployment 的多个 Pod,CPU 使用率明显不同,个别 Pod 的 CPU 使用率逼近或超过 100%,响应延迟,其它的 Pod 都是 10%~20%。
CPU 使用率的计算公式
容器 CPU 使用率的计算采用的是《通过Prometheus查询计算Kubernetes集群中的容器CPU、内存使用率等指标》 中的方法:
(sum by(cluster, namespace, container_name, pod_name) (irate(container_cpu_usage_seconds_total{container_name!=""}[1m])))
/
(sum by(cluster, namespace, container_name, pod_name) (container_spec_cpu_quota{container_name!=""}) / 100000)
验证无误。
容器状态观察
查询 Nginx 的访问日志,正常容器的处理请求数量占比基本相同,CPU 异常高的容器处理的请求数占比只有正常的容器的一半。

请求响应时间迪比
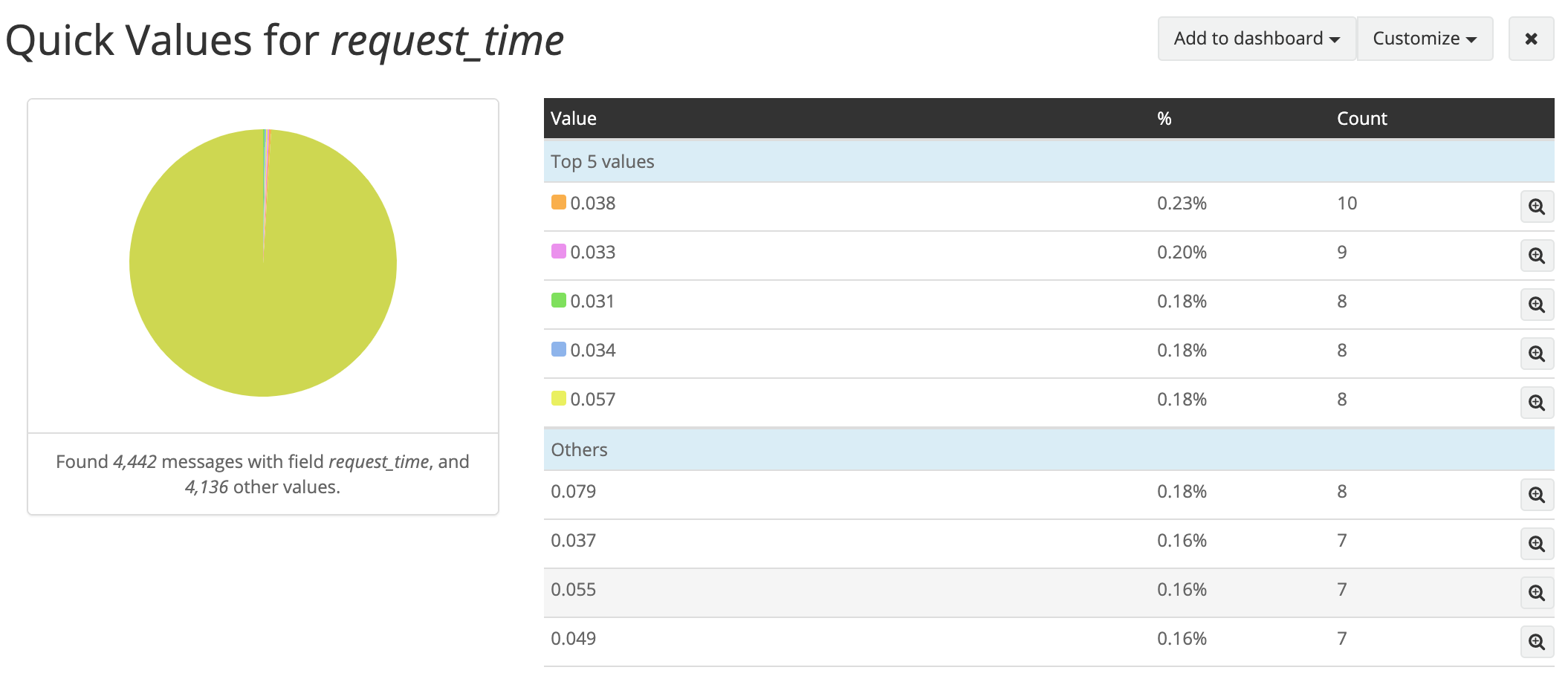
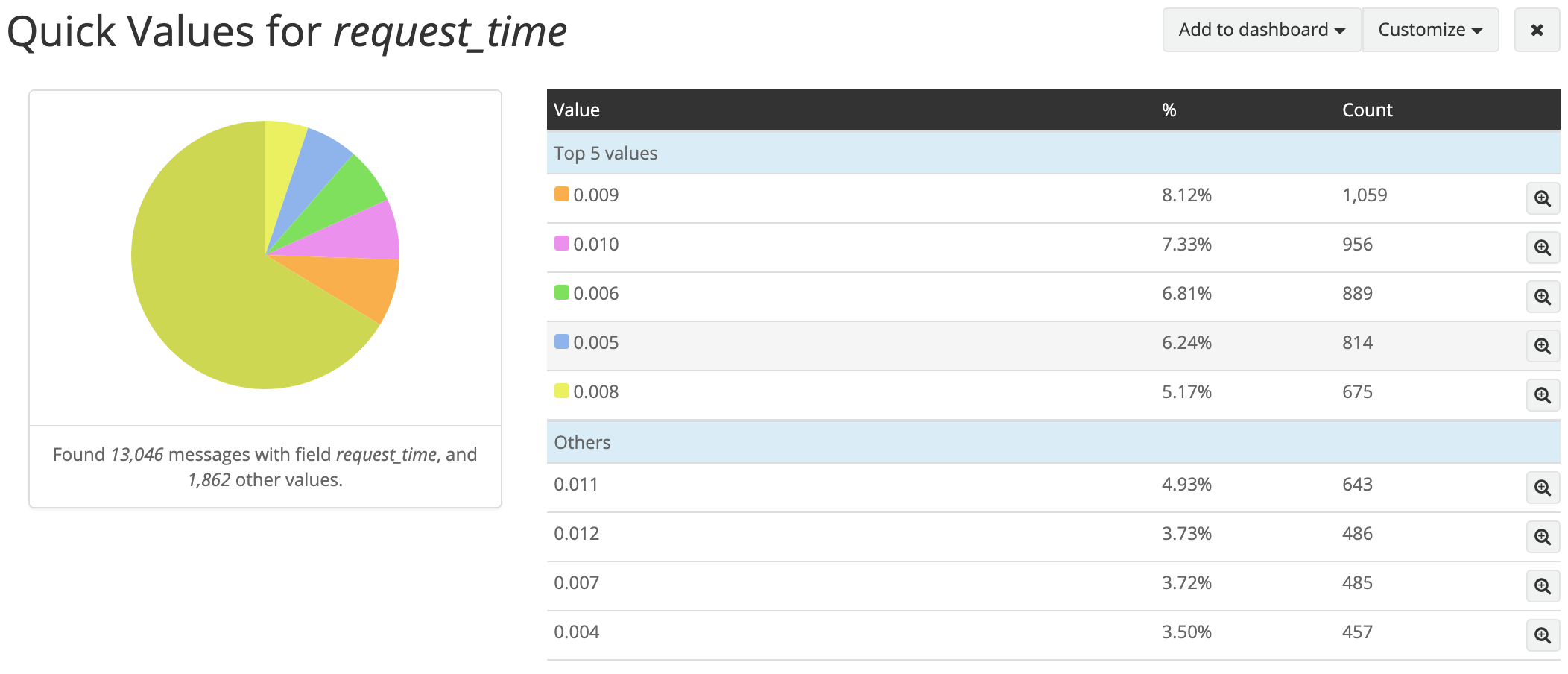
异常容器的响应时间明显高于正常容器:
异常容器:
正常容器:
进程状态对比
异常容器的 %usr 显著高于正常容器,也是 CPU 使用率不同的主要原因,%system 差距不大。
异常容器:
# pidstat -p 650 1
Linux 3.10.0-693.11.6.el7.x86_64 (node-60-232) 09/09/2019 _x86_64_ (32 CPU)
03:16:07 PM UID PID %usr %system %guest %CPU CPU Command
03:16:09 PM 0 650 556.00 6.00 0.00 562.00 16 java
03:16:10 PM 0 650 488.00 5.00 0.00 493.00 16 java
03:16:11 PM 0 650 492.00 7.00 0.00 499.00 16 java
03:16:12 PM 0 650 591.00 4.00 0.00 595.00 16 java
03:16:13 PM 0 650 514.00 11.00 0.00 525.00 16 java
03:16:14 PM 0 650 423.00 8.00 0.00 431.00 16 java
正常容器:
# pidstat -p 9470 1
Linux 3.10.0-693.11.6.el7.x86_64 (node-40-237) 09/09/2019 _x86_64_ (32 CPU)
03:17:20 PM UID PID %usr %system %guest %CPU CPU Command
03:17:21 PM 0 9470 70.00 7.00 0.00 77.00 9 java
03:17:22 PM 0 9470 72.00 10.00 0.00 82.00 9 java
03:17:23 PM 0 9470 60.00 8.00 0.00 68.00 9 java
03:17:24 PM 0 9470 58.00 7.00 0.00 65.00 9 java
03:17:25 PM 0 9470 66.00 9.00 0.00 75.00 9 java
03:17:26 PM 0 9470 66.00 9.00 0.00 75.00 9 java
03:17:27 PM 0 9470 56.00 9.00 0.00 65.00 9 java
进程状态对比
用 perf 观察进程的状态:
perf record -p 进程号 -ag -- sleep 15;perf report
异常容器:
Samples: 269K of event 'cpu-clock', Event count (approx.): 67333750000
Children Self Command Shared Object Symbol
+ 19.11% 0.00% java libpthread.so.0 [.] __nptl_setxid
+ 19.11% 0.00% java libjvm.so [.] 0xffff80d79551bad8
+ 15.28% 0.00% java libjvm.so [.] 0xffff80d7956dac1f
+ 9.75% 0.00% java libjvm.so [.] 0xffff80d7951a4a36
+ 9.74% 0.00% java libjvm.so [.] 0xffff80d7951a33f5
+ 9.32% 0.00% java libjvm.so [.] 0xffff80d79521feeb
+ 4.34% 4.33% java perf-615.map [.] 0x00007f285a61410e
+ 3.52% 0.00% java libjvm.so [.] 0xffff80d7956c1670
+ 3.40% 0.00% java libjvm.so [.] 0xffff80d7956c11fe
+ 3.40% 0.00% java libjvm.so [.] 0xffff80d7956c0e7a
+ 3.40% 0.00% java libjvm.so [.] 0xffff80d7956c2aa5
+ 3.24% 0.00% java libjvm.so [.] 0xffff80d7956c38d5
+ 3.24% 0.00% java libjvm.so [.] 0xffff80d79519f4f5
+ 3.10% 0.00% java libjvm.so [.] 0xffff80d79519eb25
+ 2.79% 0.00% java [unknown] [.] 0xd001bc24f802ce48
+ 2.40% 2.39% java perf-615.map [.] 0x00007f2858e63e46
+ 2.07% 0.00% java [unknown] [.] 0x9090909090c3c9e5
正常容器:
Samples: 45K of event 'cpu-clock', Event count (approx.): 11400250000
Children Self Command Shared Object Symbol
+ 13.05% 0.00% java perf-9470.map [.] 0x00007f7e352d2728
+ 13.02% 0.00% java libjava.so [.] 0xffff8081b7d1ccd1
+ 12.94% 0.00% java libjvm.so [.] 0xffff8081b7b5486b
+ 12.69% 0.00% java libjvm.so [.] 0xffff8081b7ade64d
+ 12.08% 0.00% java perf-9470.map [.] 0x00007f7e357fde08
+ 9.00% 0.00% java libpthread.so.0 [.] __nptl_setxid
+ 9.00% 0.00% java libjvm.so [.] 0xffff8081b7d61ad8
+ 8.80% 0.01% java [kernel.kallsyms] [k] system_call_fastpath
+ 8.00% 0.00% java libjvm.so [.] 0xffff8081b7f20c1f
+ 7.09% 0.00% java libjvm.so [.] 0xffff8081b79ebdf3
+ 4.58% 0.00% java libjvm.so [.] 0xffff8081b7ade1eb
+ 3.98% 0.00% java libjvm.so [.] 0xffff8081b7a059db
+ 3.52% 0.05% java libpthread.so.0 [.] __lll_lock_wait_private
+ 3.36% 0.00% java [unknown] [.] 0xd193a6ddf8004f96
+ 3.35% 0.00% java [kernel.kallsyms] [k] sys_write
Jvm 信息
sh-4.1# java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build 1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
yum install -y cmake gcc git make gcc-c++ sudo
宿主机状态观察
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文