Borg论文阅读笔记
目录
说明
Borg是Google内部使用的集群管理系统,已经应用了十多年。直到2015年4月,Google才在论文Large-scale cluster management at Google with Borg中介绍了Borg的一些细节。
有意思的是,这篇论文的发表时间是晚于kubernetes项目的,kubernetes项目在github上的第一次提交是2014年6月。
Kubernetes是仿照borg的,这篇论文里有很多非常熟悉的场景,可以从中得知kubernetes的一些设计的初衷。
概览
Borg的系统架构如下图所示,每个node上部署一个Borglet,多个BorgMaster组成一个虚拟的Master,使用基于paxos协议的持久存储,scheduler是独立的线程。
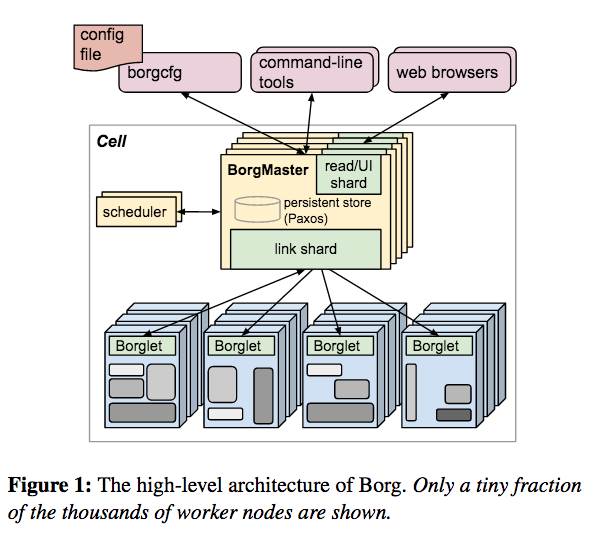
这个架构和kubernetes如出一辙。
用户向Borg中提交的任务单位是Job,Job由一到多个同质的Task组成,Job分为常驻和批处理(运行结束即退出)两种类型。Job用BCL语言描述,有非常多特性,实际应用中有很多的BCL文件超过了1000行!
一个Cluster中的的node(物理服务器),被划分成多个Cell,每个node只能隶属于一个Cell。
Job被提交到Cell中,中等规模的Cell大概包含1万个node。
一个Cluster中通常有一个大规模的Cell和几个规模较小的用于测试或者其它目的的小Cell。
在Google内部,MapReduce、FlumeJava、MillWhell、Pregel,实现了自己的controller,用于向borg提交任务,类似于yarn。GFS、CFS、BigTable、Megastore都运行在borg上。
Job与Task
Job和Task存在下图中所示的几个状态:
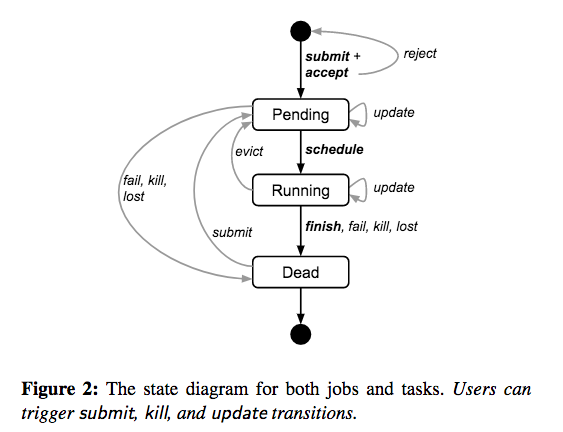
当要修改一个job中的task的属性时,向borg中提交一个新的job描述文件,然后指示borg进行更新。
task的更新是以滚动的方式(rolling)进行的,可以指定更新过程中被终止(重启/重分配)的task的数量,忽略会导致过多task被终止的更新。
task被SIGKILL信号终止的之前,会收到一个SIGTERM信号,task中的任务可以在收到SIGTERM信号后,进行退出前的整理。
资源分配
资源的分配方式是Borg中设计的最精妙的部分。
node上的资源被分割成多个alloc,每个alloc中声明了一定数量的资源,可以在alloc中运行多个task,这些task共享所在的alloc中的资源。
一个job可能会有多个task,对应的会有多个分布在不同node上的alloc,这样一组alloc,称为alloc set。
在borg中job是有优先级的,当要在一个剩余资源不足的node上创建task的时候,node上已有的低优先级的task会被抢占(对应task被重新调度)。
在实践中,Google将borg中的优先级划分为四个区间:
高 低
--------------------------------------------------------------
| monitoring | production | batch | best effort |
--------------------------------------------------------------
高优先级的task可以抢占低优先级的task,这个特性会导致抢占风暴,即被抢占的task继而抢占了优先级更低的task的资源。
在实践中,Google只允许优先级在production以下的task被抢占,也就是说用于生产的task是不会被抢占的。
Job可以使用的资源上限用quota限制,quota就是一组资源列表,当job对应的quota不足时,会被borg拒绝。
优先级为production以及以上的job,它们的quota是cell中所有的可用资源,quota的设置管理是由另外的系统负责的。
资源回收
在资源分配中设计最精妙的部分是资源的回收(resource reclamation)。
Job可以设置一个limit,即task需要的资源上限,在做quota检查以及评判node的资源是否能满足时,使用的是limit。
Task通常只有在业务高峰时才会将limit中的资源全部使用,大部分时间只使用了其中的一部分。
BorgMaster会定时(几秒)评估task真实需要的资源,评估出来的资源称为task预定的资源(reservation)。
初始的时候,task的reservation等于limit。
300s后,reservation逐渐被降低到实际使用的资源(Borglet监控的数据),加上一个安全边界(safety margin)。
如果task实际使用的资源超过了reservation,reservation会被迅速增加。。
limit减去reservation后的资源,称为回收的资源(reclaimed resource)。
在实践中,Google在调度非生产环境中的task时候,reclaimed resouce被认为是可用的资源,从而使非生产环境中的task可以利用这些闲置的资源。
当task的reservation发生变化,node上的资源开始不足的时候,非生产的task被杀死或者被限制资源使用量。
调度生产环境中的task的时候,不考虑回收的资源,只计算已经在运行的task的limit,因此生产环境中的task不会因为资源不足被杀死。
Google统计发现,在一个中等规模的cell中,大约有20%的任务使用的是回收的资源。
试验发现,在回收资源的时候,可以使用比较激进的策略,即选用较小的satefy margin,不会导致OOM的task明显增多。
下图中,前两行中,每个图标中由内向外分别是: task实际使用的资源(深灰色),borg评估出来的task预定的资源(黄色),limit中要求的资源(浅灰色)。
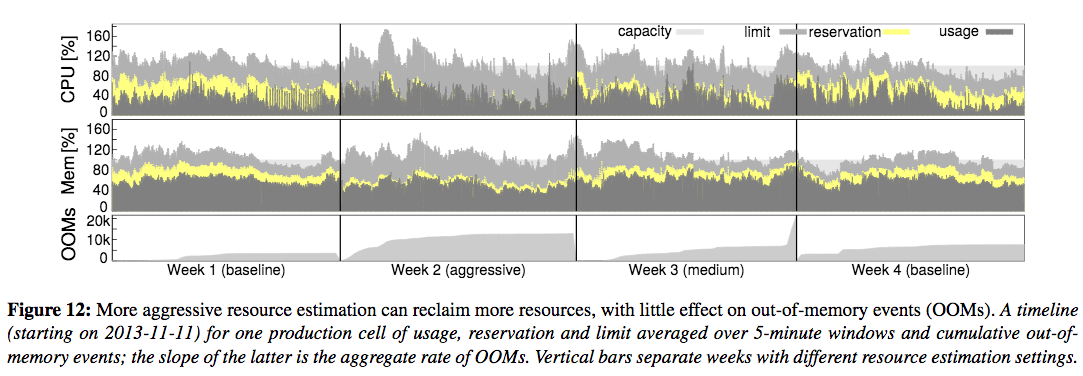
最后一栏是四种策略下OOM发生的次数,可以看到在Week3中使用了较激进的策略,OOM的数量增加不明显。
调度过程
job被提交到borg后,被存放到Paxos stroe中,同时将对应的task添加到pending队列中。
scheduler异步的扫描pending队列,为task挑选出合适的机器。
scheulder优先处理高优先级的task,对优先级相同的task,按照它们所属的job,使用Round Robin策略。
调度,即挑选node的过程,分为两步:选出符合条件的node(feasibility checking),对node进行评分(scoring)。
评分时主要考虑以下几个方面:
被抢占的task的优先级和数量最小化。
node上是否已经有对应task的package文件。
tasks分配到不同的故障域(failure domains)。
将高优先级的task和低优先级的task分配到同一个node上,使高优先级的task可以在必要时候抢占低优先级task的资源。
调度过程中的评分过程,是borg中最考究的部分。有两种极端策略,一种是将task尽可能的分配到所有的node上,一种是将一个node尽可能装满。 第一种方式,会导致剩余资源碎片化,第二种方式中task聚合的太紧密,负载突增时影响较大,并且优先级较低非生产任务不能充分利用闲置的资源。 Borg的评分细节没有公开,只知道是以上两种极端策略的折衷。
评分是一个比较耗资源的过程,Borg缓存每个node的评分,直到node发生了足够大的变化时才重新评分。隶属于同一个job的task是同质的,对此BorgMaster只需要做选机器和评分操作。 Borg在调度时候,也不会考量所有的node,而是随机的选出一批node,直到得到足够多的满足条件的node。
Google使用cell compaction来评估调度策略,即在指定的工作量下,逐渐减少node,直到导致调度失败时剩余的node数量。 Google开发一个名为Fauxmaster的工具进行评估,Fauxmaster是一个BorgMaster模拟器,它可以加载BorgMaster的snapshot,模拟BorgMaster接收请求,模拟BorgMaster进行运算(直接使用BorgMaster的代码)。
Kubernetes从borg中吸取的教训
在Borg中,Job是用来对task进行分组的唯一方式,这种方式相当不灵活,导致用户自己发展出很多方式来实现更灵活对分组。 Kuberntes吸取了Borg的这个教训,引入了Labels,使Pod可以被灵活地分组。
在Borg中,一个node上的所有task共享node的ip,这直接导致端口也成为一种资源,在调度时候需要被考虑。Kubernetes为每个Pod分配独立的IP。
为了满足一些大用户的需求,Borg开放了很多API,暴露了230个参数,导致一些要求不是很高的用户难以上手,不得不开发了一套自动化工具。
Kubernetes从borg中吸取的经验
Kubernetes借鉴了Alloc(node上的一块可以被多个task共享的资源),设计了Pod(多个容器的封装)。这种设计,可以将一个pod中的任务分拆成不同 的容器,由不同的团队开发,特别是一些辅助性的任务,例如日志采集等。
Borg中task、job的命名机制被kubernetes借鉴,提供了service等特性。
Borg将系统内部的事件、task的日志暴露给用户,提供了不同级别的UI和调试工具,使几千个用户能够自助地使用Borg。 Kubernetes吸收了Borg的这些特性,引入cAdvisor、Elasticsearch/Kibana、Fluentd等组件。
Borg采用中心式设计,管理功能集中于Master,这种设计方便了后续更多特性引入以及规模的扩展。 Kubernetes更进一步,apiserver只负责处理请求和状态维护,集群的管理逻辑被拆分到多个更精悍、内聚的controller中。
其它
Borg是一个庞大、复杂的系统,在公开的论文中还提供了很多特别有价值的实践经验和实现技巧,例如:
使用一个规模足够大的cell,在同等任务时,比使用多个规模较小的cell,需要的node数更少。
50%的node上运行了超过9个任务。
非Leader的BorgMaster自动分管node,负载均摊。
BorgMaster轮询Borglet,防止出现请求风暴。
Borget向BorgMaster反馈的状态是全量的,但对应BorgMaster只将增量部分提交给作为Leader的BorgMaster。
BorgMaster宕机,node上的task保持原状。
Task启动平均耗时25秒,80%的时间是在读取Task的Package文件
node失联后,它所承担的task已经在其它node上重建,node重新上线后,依然在运行的任务在BorgMaster的指示下删除。
用户向Borg发起的请求被设计成幂等的。
...
感兴趣的还是建议读一下论文:Large-scale cluster management at Google with Borg
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文