阿里巴巴的应用限流和服务降级是怎样实现的?|如何打造平台稳定能力
目录
说明
这是阿里云分布式应用服务的博客上发布的系列文章之一,介绍了应用限流和服务降级在阿里的实现。摘录在这里,仅仅作为个人备份使用。
限流和降级是两个概念。
当请求压力过大的时候,通过排队或丢弃的方式,限制进入系统的请求数,防止系统崩溃,这是限流。
为了保障核心服务的运行,将一些非核心服务,从调用链中摘除,这是降级。
在限流方面,阿里巴巴是用Nginx实现的,开发一个名为taobao missile defense的模块,根据IP或者Cookie限制请求频率。
在服务接口的限流和降级方面,阿里巴巴使用自己开发的Sentinel平台实现,在应用中嵌入Sentinel客户端,通过Sentinel控制台设置限流规则和服务降级。
下面是原文。
如何打造平台稳定性能力(一)
在整个稳定性体系中,所包含的范围非常广泛,从机房的布线、网络通信、硬件部署、应用架构、数据容灾等方面都与之相关。从共享服务中台的角度看,则更多的是从应用架构设计和中间件平台的维度对平台的稳定性实现更精确化的管理和保障。本期开始,我们将从这个角度介绍阿里巴巴中间件团队多年来为了提升平台稳定性所做出的一系列技术创新和成果,包括限流和降级、流量调度、业务开关、容量压测和评估、全链路压测平台业务一直性平台等。
第一期:限流和降级(上)
由于第一期的内容篇幅较多,我们将切分为上下两个篇章。
一、限流和降级的产生背景
先设想一个场景,你开发了一个企业中非常核心的一个服务,日常情况下会有上百个应用调用,如果对服务的调用不加限制的使用,可能会因为某个应用开发的bug 或不合理的设计给服务造成非常大的压力,直接导致所有服务节点全部被请求占满,使得原本非常核心的应用因为访问服务超时而产生了很大的生成事故。从现象来说,所有服务节点看起来运行很繁忙,但从应用方的角度来看,因为服务响应时间过长,实际上该服务并没有提供有效服务。从设置上来说,服务就是给其他应用提供服务的,用户怎么调用服务很难控制,所以必须从服务自身做好保护,否则可能因为一个小的问题造成平台级的故障。
另一个是活动大促的场景,准备好的50台机器资源可以应对预估的100万参与人数,但实际情况是瞬间来了1000万用户,远远超过服务处理能力的访问请求,会使后端的服务器直接满负荷运算,并伴随着大量的资源抢占和上下文切换,使平台处理能力下降到一个极低的程度,影响业务请求的响应时间。类似的还有因为一个社会热点,应用端出现用户请求陡增的情况。
二、限流的作用和前期准备
限流的作用相当于电路上的保险丝,当过载的时候掐掉一点流量,让系统有能力集中资源以较快的深度处理 平台处理能力范围内 的业务请求。也就是让上面提到的大促场景中,仅让1000万用户中的100万用户进入后端的处理流程中,将其余900万用户的请求通过队列或直接阻挡在平台处理单元之外的方式,保障平台在处理能力范围内对100万的用户请求进行处理。
平台要具备限流能力,需要配备好压测和监控能力。
通过压测,我们可以知道服务实例的部署最大能满足多少的业务请求。但传统的压力测试方法都是采用模拟的数据,从实践的角度来看,这些压测数据与在实际生产环境中所表现的指标还是有比较大的偏差,也就是说,采用模拟数据进行压力测试的方式并不能准确测量出平台的能力峰值。阿里巴巴中间件团队经过内部5年+的全生态沉淀,开发出的针对分布式场景,可模拟海量用户的真实业务场景的性能测试产品PTS,能更方便和准确的对服务的容量进行评估,这在“如何打造系统稳定平台”之后的章节中会详细介绍。
在掌握服务的容量后,接下来就是针对服务资源的使用情况进行监控,通过资源监控的指标与之前所获取的服务能力进行比较,如果超过服务处理上限则启动限流。通过CPU、内存和磁盘IO等资源的使用情况来判断系统目前的负载往往是不准确的。因为很多情况下系统本身的处理能力出于什么样的水位跟这些操作系统资源的使用情况没有一个清晰的对应关系,所以在实际生产中,都会通过服务的QPS作为限流的关键判断指标。
三、阿里巴巴是如何做限流管控的
对于平台限流的实现,先从一个典型服务化应用架构的角度来看。用户的请求首先会通过前端接入层(一般采用Nginx),分发到后端的应用集群上,应用集群中主要负责用户的前端交互以及业务需求对后端服务集群中的服务进行服务调用。为了避免出现远超过系统处理负载上限的访问请求,同时又能很好的兼顾安全问题,通过一些安全策略防止对平台的恶意攻击,所以最优的限流拦截点在前端接入层面,因为一旦让“洪流”进入到系统的下层,对于系统的冲击以及限流的难度都会加大。
阿里巴巴是通过在 Nginx 上实现的扩展组件 TMD(taobao missile defense淘宝导弹防御系统)实现了接入层限流的主要工作,TMD系统可通过域名类限流、cookie限流、黑名单以及一些安全策略等很好的实现了在接入层的限流措施。
TMD系统包含了淘宝技术团队开发的开源模块 nginx-http-sysguard,主要用于当访问负载和内存达到一定的阈值时,会执行相应的动作,比如直接返回503、504或者其他url请求返回代码,一直等到内存或者负载回到阈值的范围内,站点才恢复可用。
在模块 nginx-http-sysguard基础上,淘宝TMD系统给用户提供了可视化的配置管理界面,方便用户针对不同的业务场景实现不同的限流规则。如果来自单台机器持续访问淘宝平台上的一个URL页面,可在TMD中设置规则:访问频率大雨180次/秒,则进行IP访问频率限速或cookie访问频率限速。正是有了TMD 这样配置灵活、操作方便的规则配置界面,运维人员可以针对所发现的异常请求以及实时的处理状态,设置出各种保护措施,保障平台在面对大流量时具备一定的自我保护能力,在平台接入层外部惊涛骇浪的访问洪流下,平台接入蹭内部保持稳定、健康的运行状态。
在接入层实现了限流后,一定会有部分用户的请求得不到系统正常的处理,所以平台一般会给用户返回限流页面,在一定程度上减少用户因为请求没有成功处理的失落体验,限流页面的风格会与网站、app的设计风格统一,页面也会包含跳转引导界面,以形成用户体验和业务处理流程的闭环。
四、TMD平台在服务层面临的挑战
TMD平台能很好的实现在平台接入层的限流功能,但对于服务层就无能为力了。对于实现服务的限流控制,传统的实现方式通常用spring的aop机制,对需要限流的接口定义一个advice拦截器,示例代码如下:
<bean id="spuServiceAdvisor"
class="org.springframework.aop.suppport.RegexpMethodPointcutAdvisor">
<property name="partners">
<list>
<value>com.taobao.item.service.SpuService.*</value>
</list>
</property>
<propetry name="advise">
<ref bean="spuServiceApiAdvice" />
</property>
</bean>
<bean id="spuServiceApiAdvice" />
class="com.taobao.trade.buy.web.buy.util.monitor.advice.SpuServiceApiAdvice" />
其中的 SuperServiceApiAdvice 类实现MethodBeforeAdvice接口,重写before方法,那么在调用指定的接口或者方法前会计算当前thread count或qps,如果当前的线程数大于所设置的最大线程数阈值,则返回访问限流的异常信息。示例代码如下:
@Override
protected void invokeBeforeMethodForFlowControl(MonitorStore monitorStore) throws FlowControlException{
long newThreadCnt = monitorStore
.getStoreDataInfo(getMonitorNmae(),getKey()).getThreadCnt()
.get();
if(newThreadCnt > MonitorParam.MAX_THREAD_COUT_FIVE){
throw new FlowControlException(
"SpuServiceApiAdvice access control, threadcnt="
+ newThreadCnt);
}
}
这套流控技术方案是可行的,实现起来也非常简单,但在实际应用场景中还是会发现不少问题,比如:
如果一个应用需要对100个接口进行限流,那么对应地也就需要配置100个advice和编写100个拦截器,如果是成百上千的应用呢?
限流阀值是硬编码形式,无法动态调整,当然你也可以动态调整(比如定义成一个静态变量,然后通过curl去调整),但当限流开关达到一定量级后你会发现这是一件非常痛苦的事,很难维护管理;
限流手段太过单一,无法对特殊场景实现多样化的限流;
没有一个统一的监控平台,无法监控当前的限流情况;
限流算法简单,当在双十一这种特殊场景,会看到毛刺现象,需要一种更平滑的限流算法;
第二期:限流和降级(下)
上一期我们谈到了阿里巴巴早期是通过通过在 Nginx 上实现的扩展组件TMD(taobao missile defense淘宝导弹防御系统)实现了接入层限流的主要工作,TMD系统可通过域名类限流、cookie限流、黑名单以及一些安全策略等很好的实现了在接入层的限流措施。
但对于服务层,TMD就无能为力了。对于实现服务的限流控制,传统的实现方式通常用spring的AOP机制,对需要限流的接口定义一个advice拦截器,但这套方案在实际应用场景中还是会发现不少问题。详细问题可通过以下的传送门,进行了解。
一、Sentinel 简介
第二期我们将分享到阿里巴巴是如何解决服务层限流时遇到的问题的。在今年7月底的Aliware Open Sourec深圳站的活动上,阿里巴巴宣布开源面向分布式服务架构的轻量级限流降级框架 Sentinel。Sentinel正如它英文的意思“哨兵”一样,为整个服务化体系的稳定运行行使着警戒任务,是对资源调用的控制平台,主要涵盖了授权、限流、降级、调用统计监控四大功能。
授权:通过配置白名单和黑名单的方式分布式系统的接口和方法进行调用权限的控制;
限流:对特定资源进行调用的保护,防止资源的过度使用;
降级:判断依赖的资源的响应情况,但依赖的资源响应时间过长时进行自动降级,并且在指定的时间后自动恢复调用;
监控:提供了全面的运行状态监控,实时监控资源的调用情况,如QPS、响应时间、限流降级等信息;
Sentinel 平台有两个基础概念,资源和策略,对特定的资源采取不同的控制策略,起到保障应用稳定性的作用。Sentinel 提供了多个默认切入点,比如服务调用时,数据库、缓存等资源访问时,覆盖了大部分应用场景,保证对应用的低侵入性,同时也支持硬编码或者自定义AOP的方式来支持特定的使用需求。
二、Sentinel 限流的实现原理
Sentinel 平台架构图如下,需要通过Sentinel 实现限流功能的应用中都嵌入Sentinel 客户端,通过Sentinel 客户端中提供对服务调用和各资源访问缺省实现的切入点,使得应用完全不需要对实现限流的服务或资源进行单独的AOP配置和实现,同时不仅可以限制自己的应用调用别的应用,也可以限制别的应用调用我的应用。通过这些资源埋点实时计算当前服务的QPS,也可通过现有的监控系统获取到应用所在服务器的相关系统监控指标,用于限流规则配置中的阀值比对。
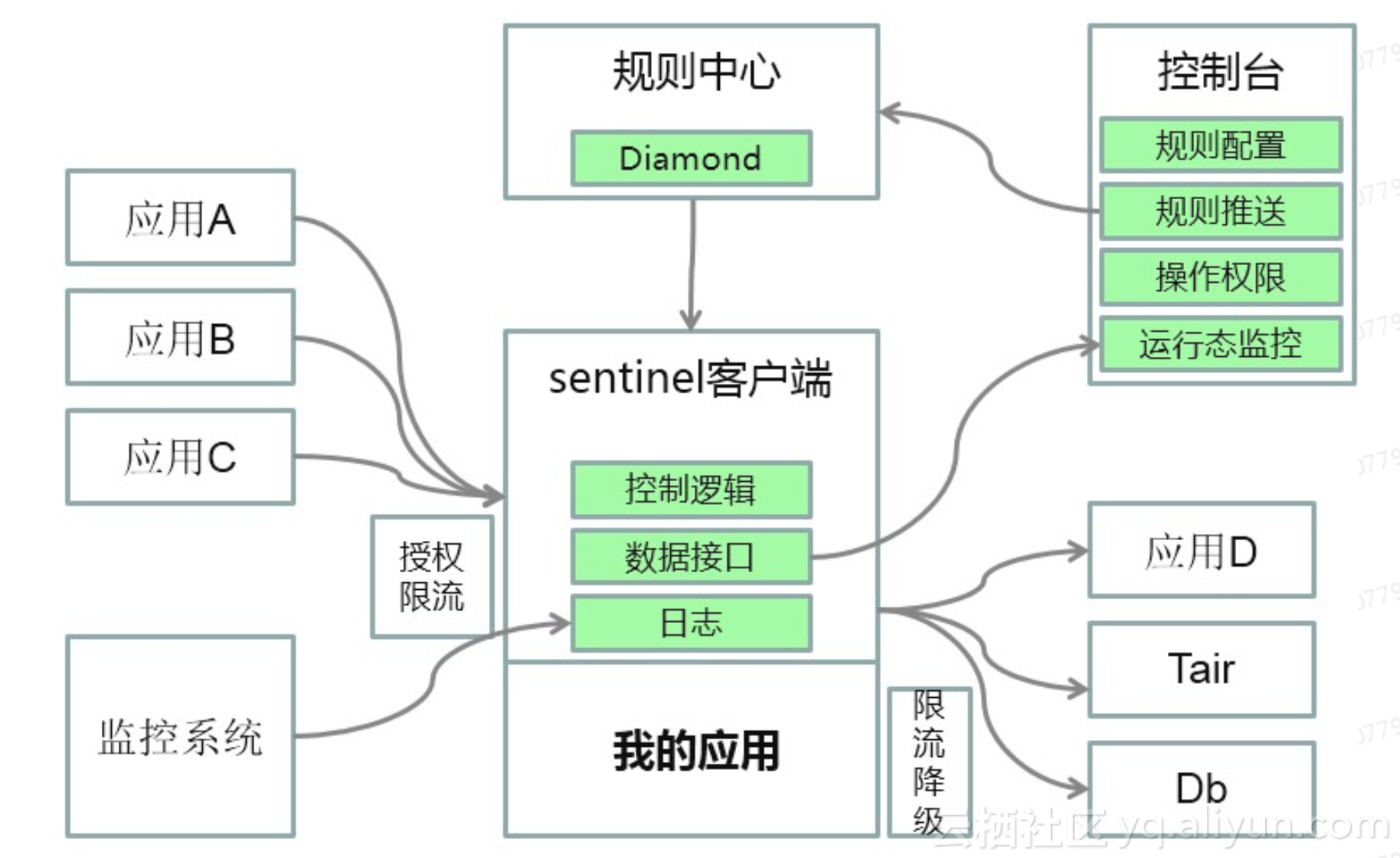
Sentinel控制台会从客户端拉取资源实时的运行监控数据如QPS、响应时间等,并展示在控制台的监控面板上。控制台给运维人员提供了针对服务、缓存、数据库等资源访问设置各种限流规则,并将设置好的规则发送到规则配置中心后,再有服务器将规则推送到相关的Sentinel客户端,让设置的规则最终在应用运行状态是时快速生效。
三、Sentinel 降级的实现原理
Sentinel平台除了限流的核心功能外,还提供了降级的功能。我们知道,在服务调用链上,存在服务间的强弱依赖,即有些业务请求处理过程中,有些服务是否正常被调研或成功处理了服务请求,对于整个业务请求不会产生决定性的影响,比如交易链路中快递优惠这个服务,这类服务调用链中就会标记为弱依赖的服务。
设想一下,如果在双11活动启动后,大量的用户订单请求涌入平台,此时发现平台的整体水位已经像平台最大处理能力的水位逼近时,除了限流可以起到第一层的保护作用外,我们还可以将那些之前标记为弱依赖的服务平滑下线,也就是让订单创建的处理流程中去掉那些弱依赖的服务调用,达到将节省出的系统资源更好地服务于核心服务的运行;又或者在大促时,某核心服务依赖某一个非核心的服务,但发现因为这个非核心服务的处理性能和服务响应时间较长,导致了当前核心服务的处理出现了瓶颈,这时为了保证核心服务的正常处理,就需要在核心服务业务逻辑中对于那个非核心服务的调用暂时停止。这样类似的场景就称为服务降级,即从服务调用者的角度,对所依赖的下游服务采取停止调用的措施,以保证当前服务的处理效率。
要实现服务降级,需要在应用或服务实现中,首先留下可供服务降级进行服务是否调用切换的逻辑。一般在代码中采用static值的方式,作为业务逻辑分支的判断条件,通过对这些static值的修改,实现服务调用逻辑的变化。同样可以通过Sentinel控制台提供的降级规则的配置功能,当对某个服务的方法响应时间一旦超过阀值后,就意味着调用的这个服务已经出现了处理性能的问题,则会自动切换到降级模式,降级持续的时间可自定义设置。 四、Sentinel 限流的实现原理
总结来说,Sentinel平台所提供的限流和降级功能,是今天阿里巴巴集团如此庞大、复杂的服务化平台稳定运行的关键,不管是在双11这样的大促活动中,还是几乎每天都有基于服务化体系构建起来的新兴业务上线,整个服务化平台能够稳定运行直观重要。从技术角度来说,企业如果要构建自身的服务化平台,如何保障平台稳定性运行的重要能力是服务化平台建设中一定要考虑的问题。
限流和降级是从服务自身做好保护的角度来避免平台级的故障。在分布式服务环境下, 我们不可忽略的一个问题是最大程度的增加机器的利用率,通常会采用超配的方式,但这个过程中往往会出现超配服务器上的应用对资源进行争抢,使得个别或局部应用出现服务响应慢甚至挂起,从而给整个业务链路带来更大的风险的情况。此时,流量调度的角色是至关重要的。下一期我们将从流量调度的角度看看如何提升平台的稳定性。
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文