《分布式金融架构课》阅读笔记1: 单机&多机并发/多副本读写正确性和一致性
目录
- 目录
- 说明
- 金融业务介绍
- 示例:跨境电商扫码支付
- 示例:资产证券化系统
- 金融系统采用软件工程方案
- 增加吞吐量的方法
- 降低延迟时间的方法
- 金融系统的数据传输
- 金融系统的数据库选择
- 金融系统的数据处理架构
- 金融系统的运算结果准确性
- 单机操作的正确性保证
- 单机操作的并发行为约定
- 多机操作的正确性
- 多机操作的乱序和并发问题
- 多机数据备份的一致性
- 分布式共识算法
- 混沌工程
- 后续
- 书单抄录
- 参考
说明
这个专栏的内容质量特别高!特别是对单机并发、多机并发、多副本读写场景下的各种问题的阐述,让人脑塞顿开。这篇笔记的章节分类是在对专栏内容反复阅读后整理出来的,和专栏中的讲解顺序不完全相同。
试读链接:任意四章试读入口
新人优惠:极客时间新注册38元代金券
金融业务介绍
1. C端金融:
1-1. 支付
2. B端金融——信贷类:
2-1. 传统信贷业务
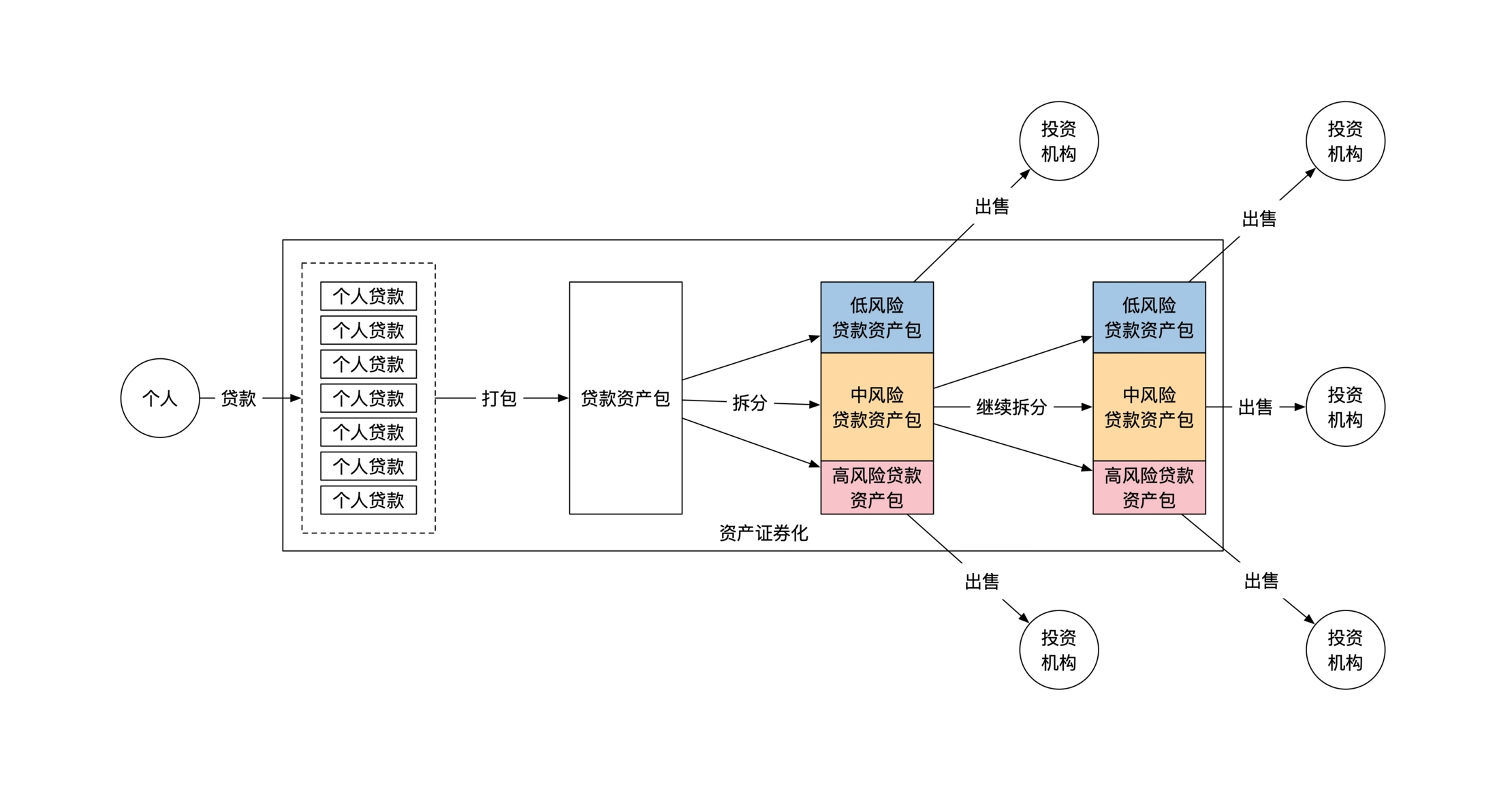
2-2. 资产证券化
3. B端金融——交易类——场内交易:
3-1. 交易所技术
3-2. 算法交易平台
4. B端金融——交易类——场外交易:
4-1. 合同定价与市场风险
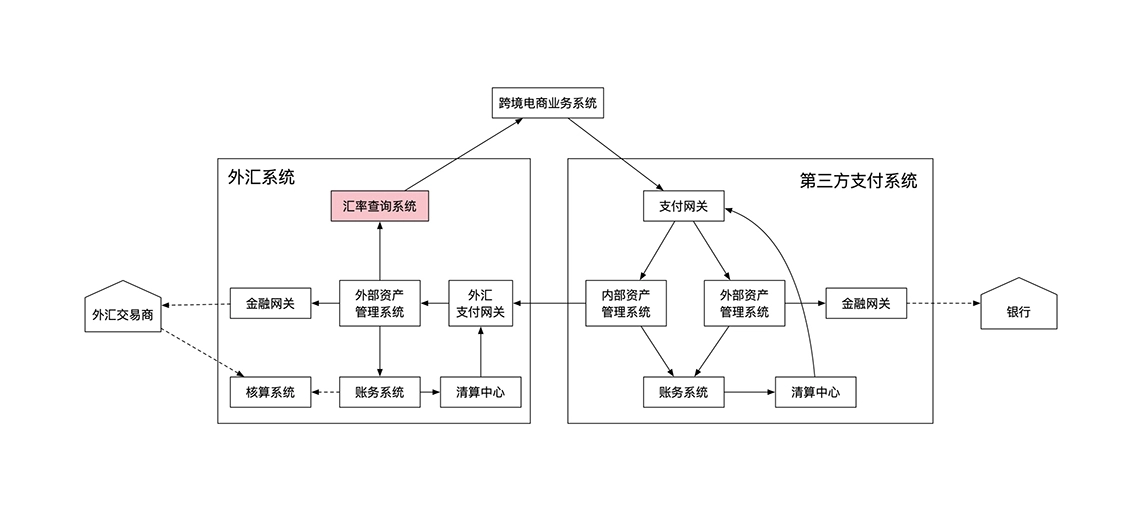
示例:跨境电商扫码支付
第三方支付的业务流程:
买家需要事先完成绑卡操作,向第三方支付机构提供账号、手机号和银行返回的验证码后,第三方支付机构用这些信息从银行获取 用户唯一 token。
系统在白天只做转账记录,不进行资金划拨,每天结束的时候再汇总两个银行的总转账金额,通过央行一次转账完成,该过程成为轧差,由清算机构负责。
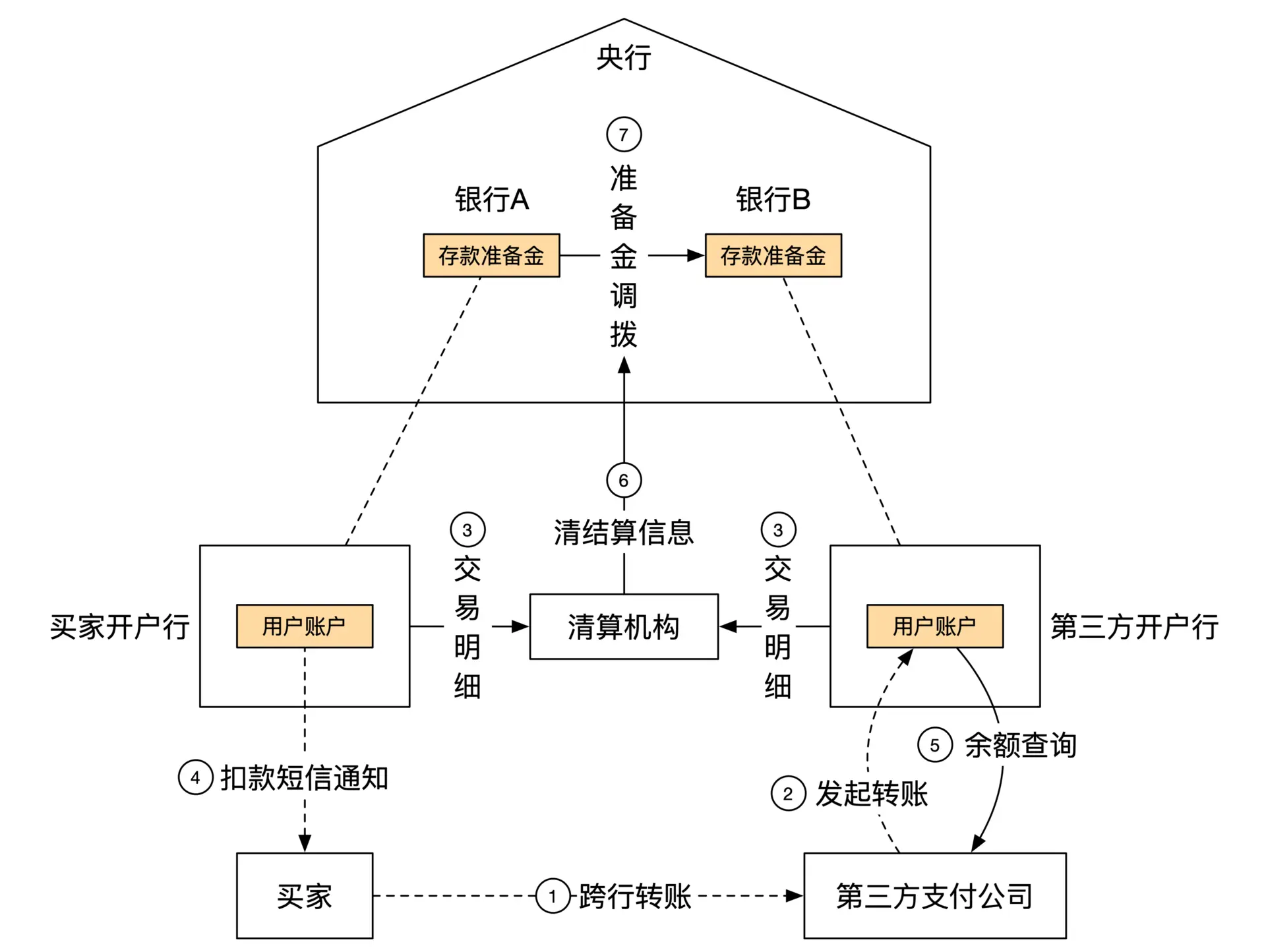
- 买家提请转账: 买家向第三方支付发起转账支付
- 第三方提交转账: 第三方支付用买家在开户行的 token 发起转账,从买家开户行转到第三方开户行
- 双方银行提交清算:买家开户行和第三方支付的开户行向清算机构提交转账信息
- 双方转账完成: 双方开户行向清算机构完成提交后,即通知双方转账成功,双方账户金额变化
- 清算机构轧差: 当天晚上清算机构汇总银行间转账信息,向央行发送银行间转账信息
- 准备金调拨: 央行划拨两家银行的准备金
第三方支付的跨境资金流动:
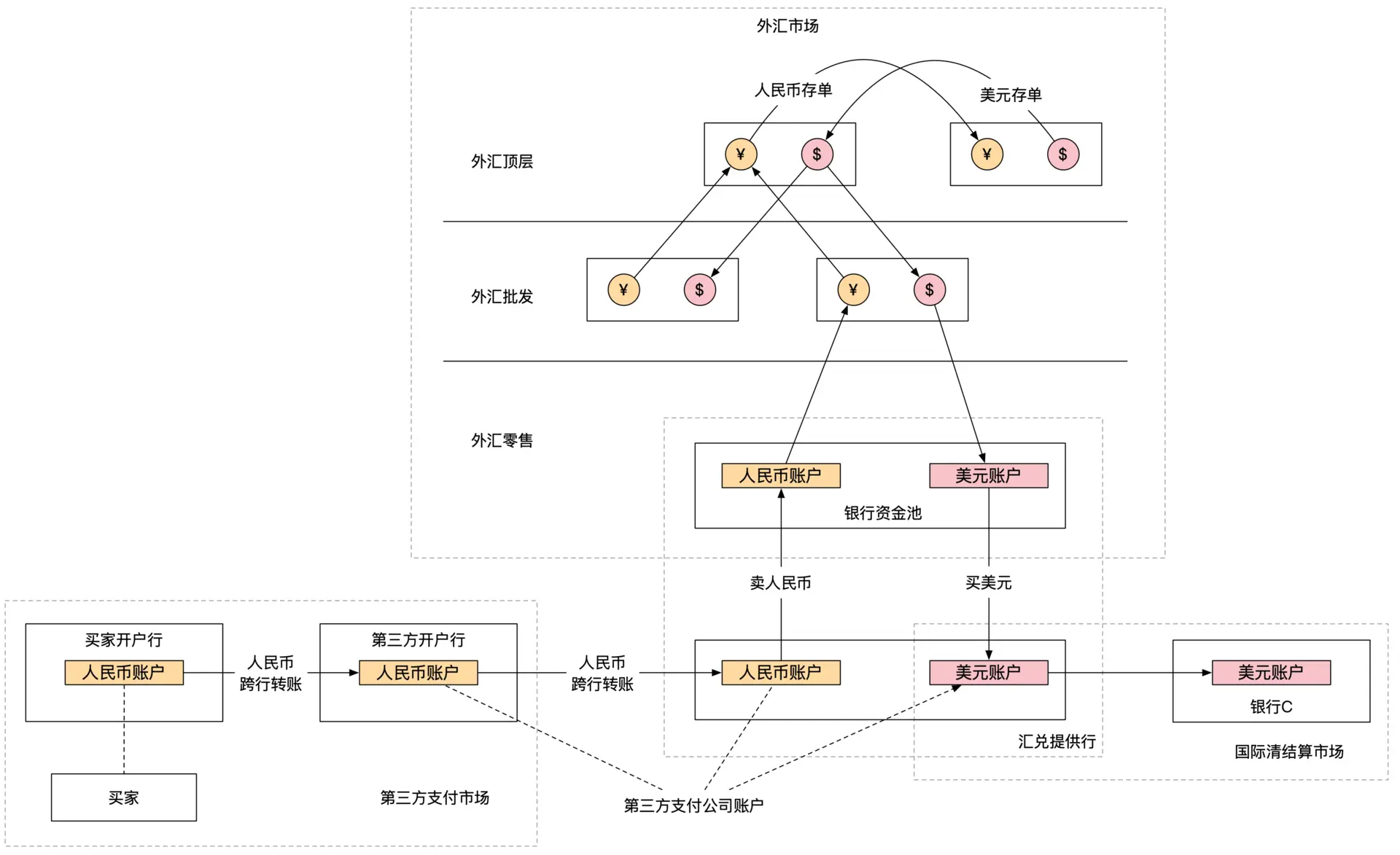
第三方支付系统的架构设计:
支付系统核心原理: 信息流和资金流分离,内部信息流系统和外部资金流系统异步交互。
- 支付环节的非银行参与者只产生信息流,不产生资金流
- 信息流和资金流以不同的速度在不同时间不同的主体间分开流转,最终保持一致
- 需要核算系统确认资金流和信息流的同步准确
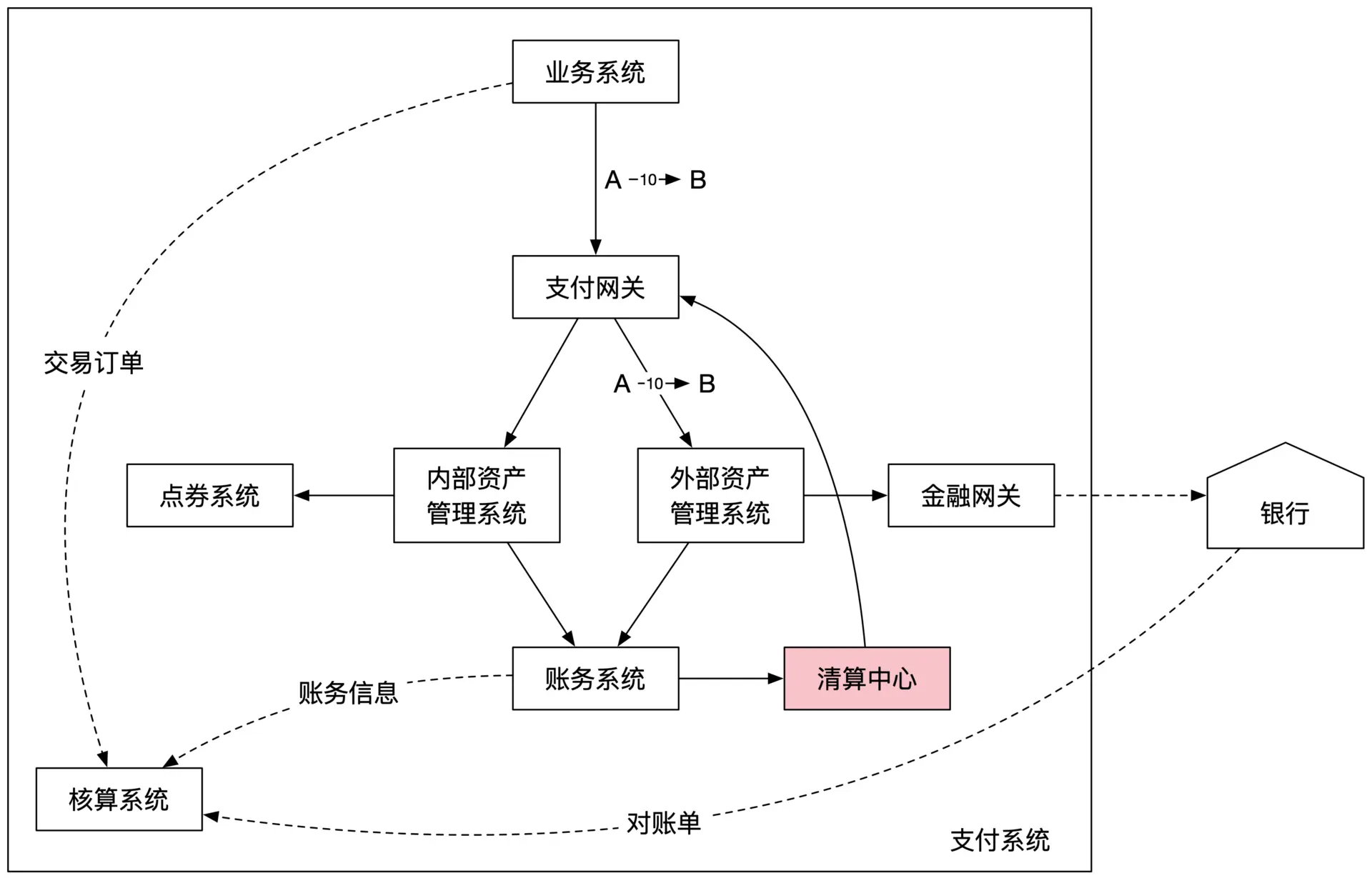
示例:资产证券化系统
金融系统采用软件工程方案
一些大的金融系统已经开始运用领域驱动设计的方法,从战略上重新设计了顶层框架和运作机制。
领域驱动设计适用的场景:
- 系统组件足够多
- 业务逻辑足够复杂
- 软件生命周期长
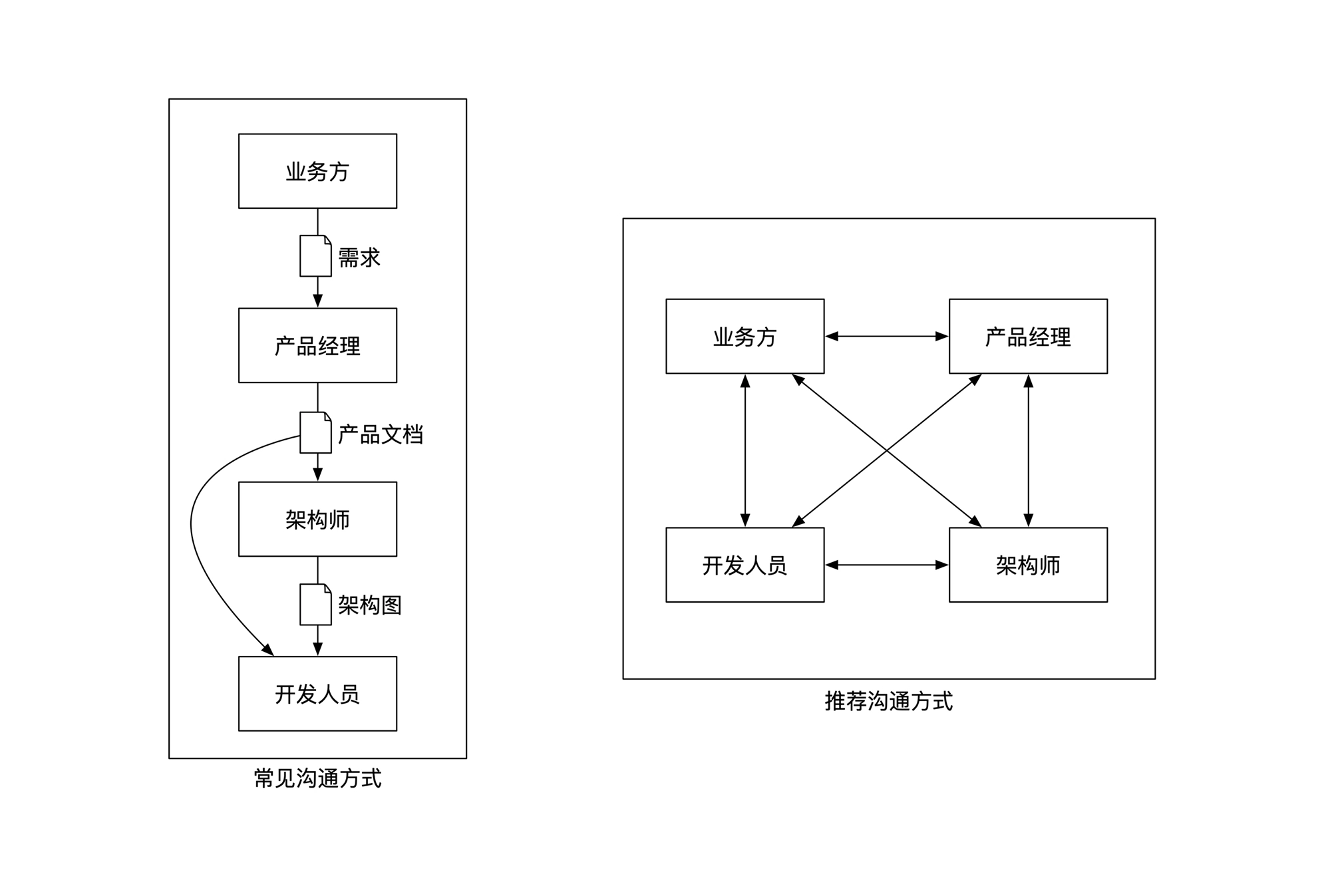
避免单线沟通:
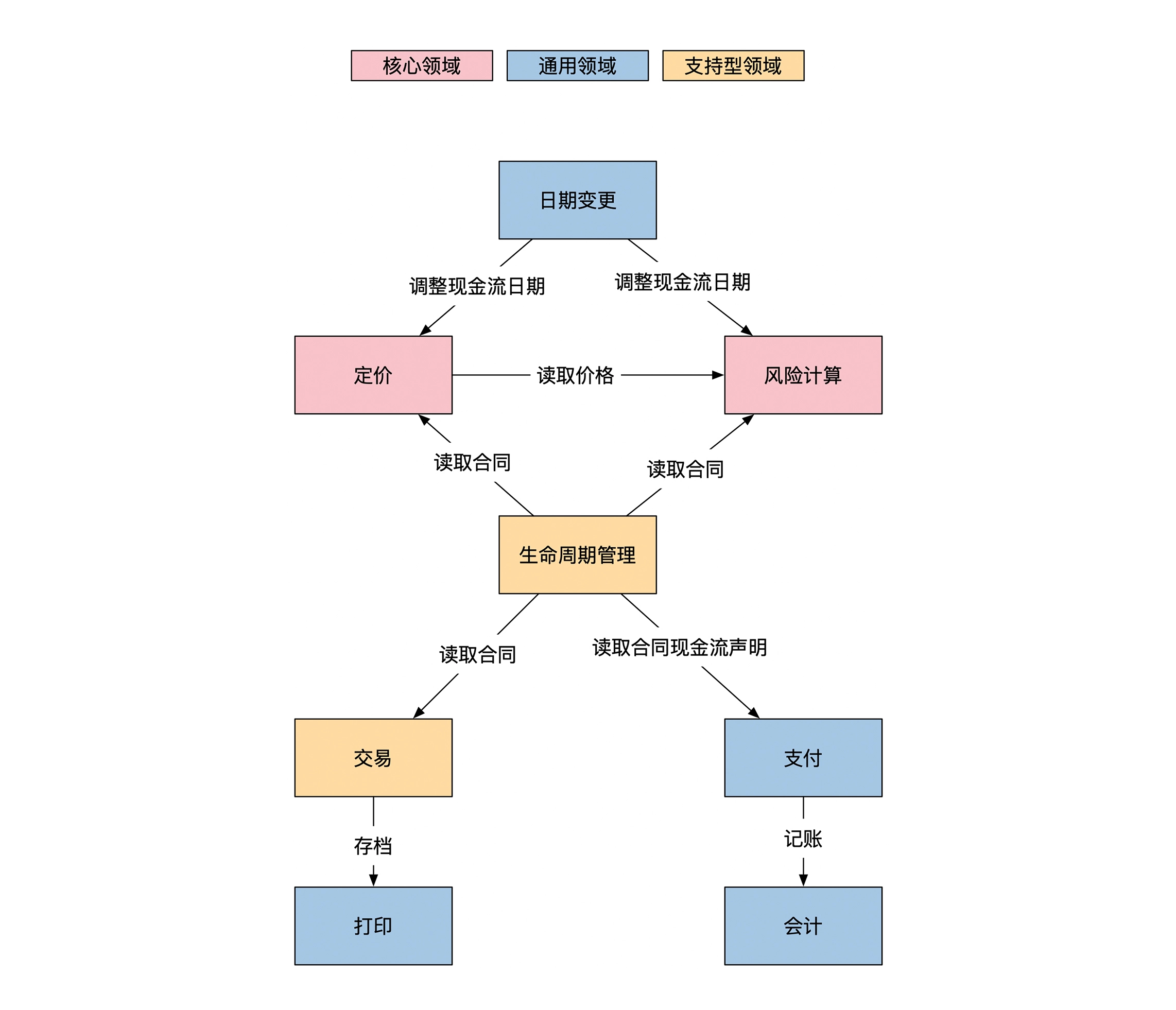
确定核心领域、通用领域和支持领域:
领域驱动术语:
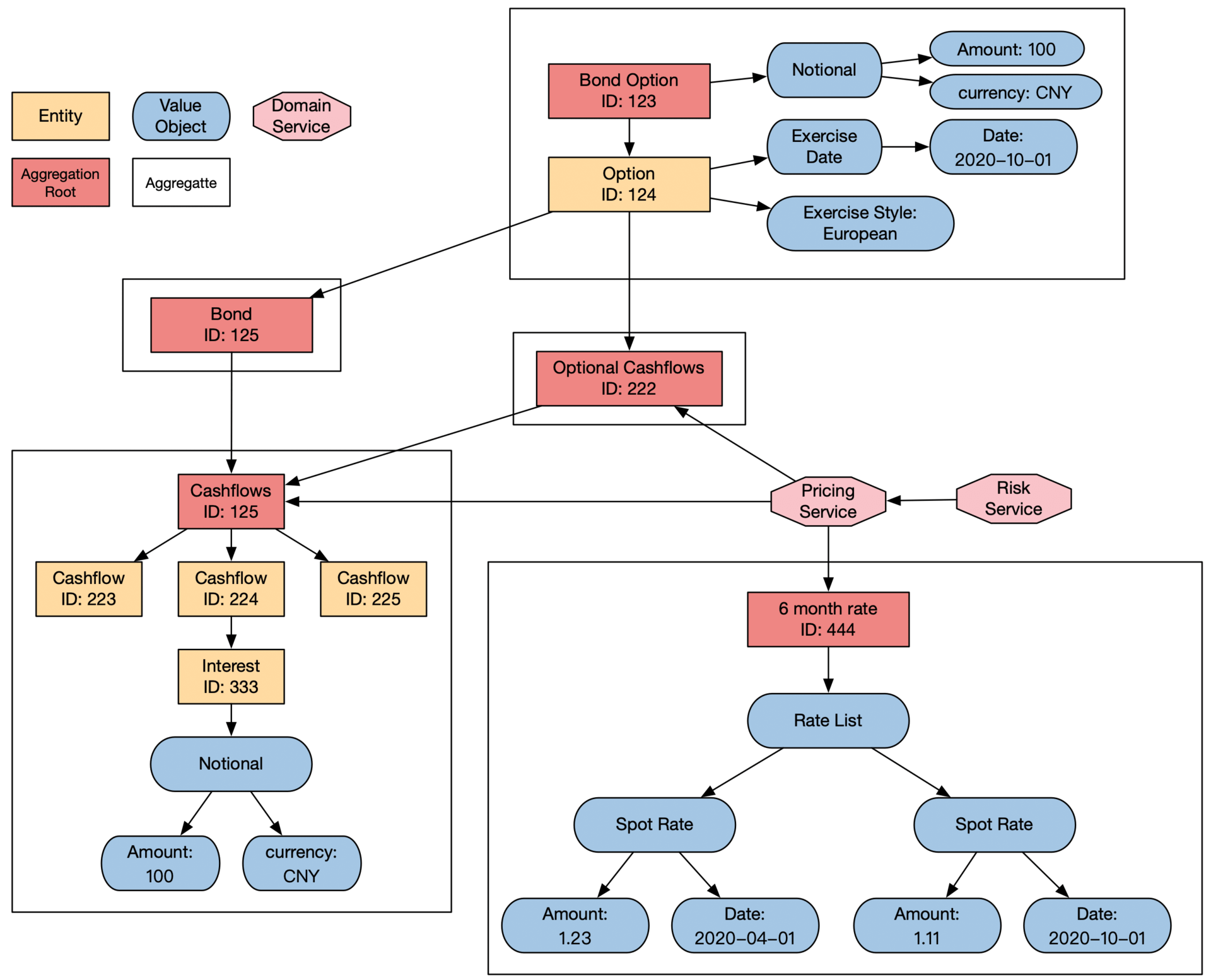
债券期权系统的的领域模型,债券 bond,期权 option:
增加吞吐量的方法
分库分表是最常用的增加吞吐量的方法,使用分库分表时除了选择切割方法,还需要考虑引入的新问题:
- 多机器操作的正确性,需要实现分布式事务
- 操作延迟,分布式事务至少两次网络沟通
- 集群容灾,机器数目越多,出问题概率越高
- 容量限制,分库分表一旦完成很难调整分库的数量
消息队列是另一种常用增加吞吐的方法,适用于出处理峰值流量,消息队列的使用参考:《消息队列高手课》阅读笔记:Rabbit/Rocket/Kafka/消息模型/消息事务/保序等。
降低延迟时间的方法
单机优化:
- 使用单线程处理,去除资源抢占开销
- 绑定/独占cpu,消除线程调度、CPU缓存更新的耗时
- 实现内存池,消除内存申请分配的耗时
- 操作文件系统尽量使用顺序写
- 随机写场景中,用mmap将文件映射到内存页表,减少用户态和内核态的数据拷贝次数
网络优化:
- 使用 epoll 应对高并发
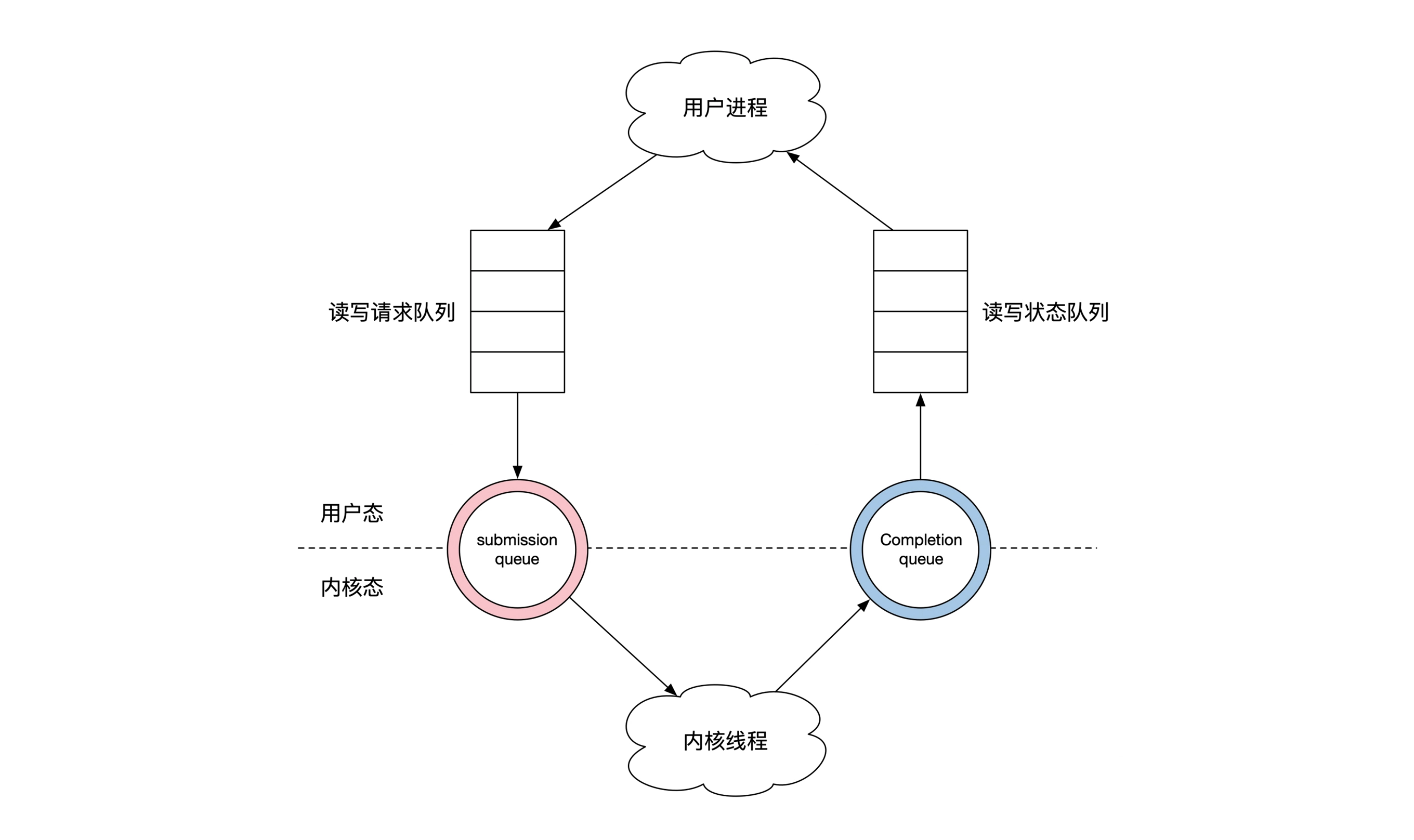
- 减少内核态用户态数据拷贝开销,譬如内核 io_uring 特性
金融系统的数据传输
不同场景下对数据传输质量的要求不同,以券商和交易所的交互为例。
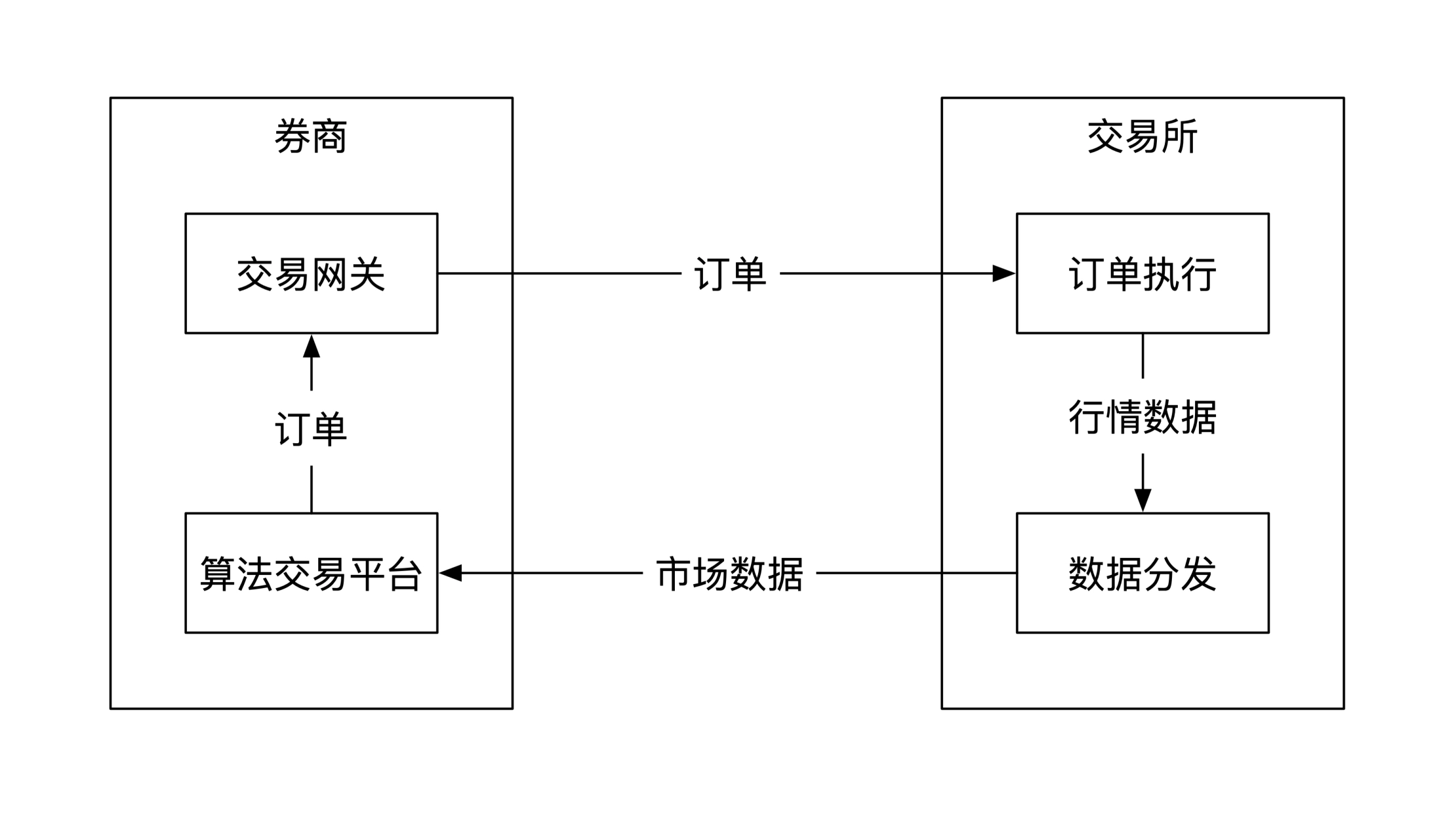
券商向交易所提交订单数据的场景:
- 交易所处理券商发送的交易数据,要保证顺序正确,并且只处理一次(或幂等)
- 交易所对券商发送的交易数据限流,漏桶算法 (直接丢弃)或令牌桶算法
交易所向券商下发行情数据场景,行情数据下发分为两种情况,实时下发和非实时下发:
- 非实时下发使用「发布/订阅」模型,券商订阅交易所数据,可以使用 Kafka 等
- 实时下发使用「同机房实时推送」方式,使用高效的传输协议 Google Prototol Buffer 或专用的
FIX协议
FIX协议只传输数据变动的部分
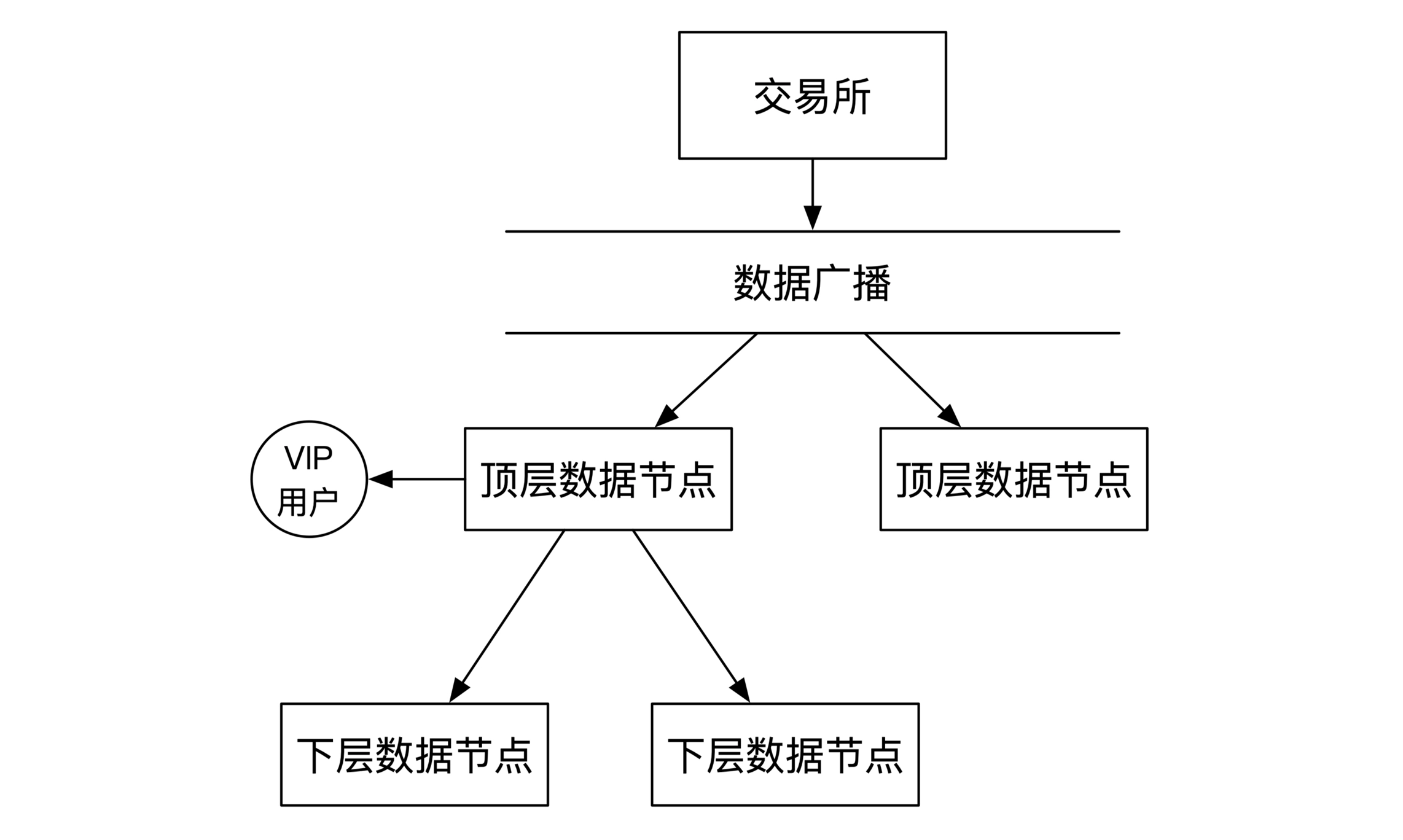
实时推送与非实时订阅的结合:
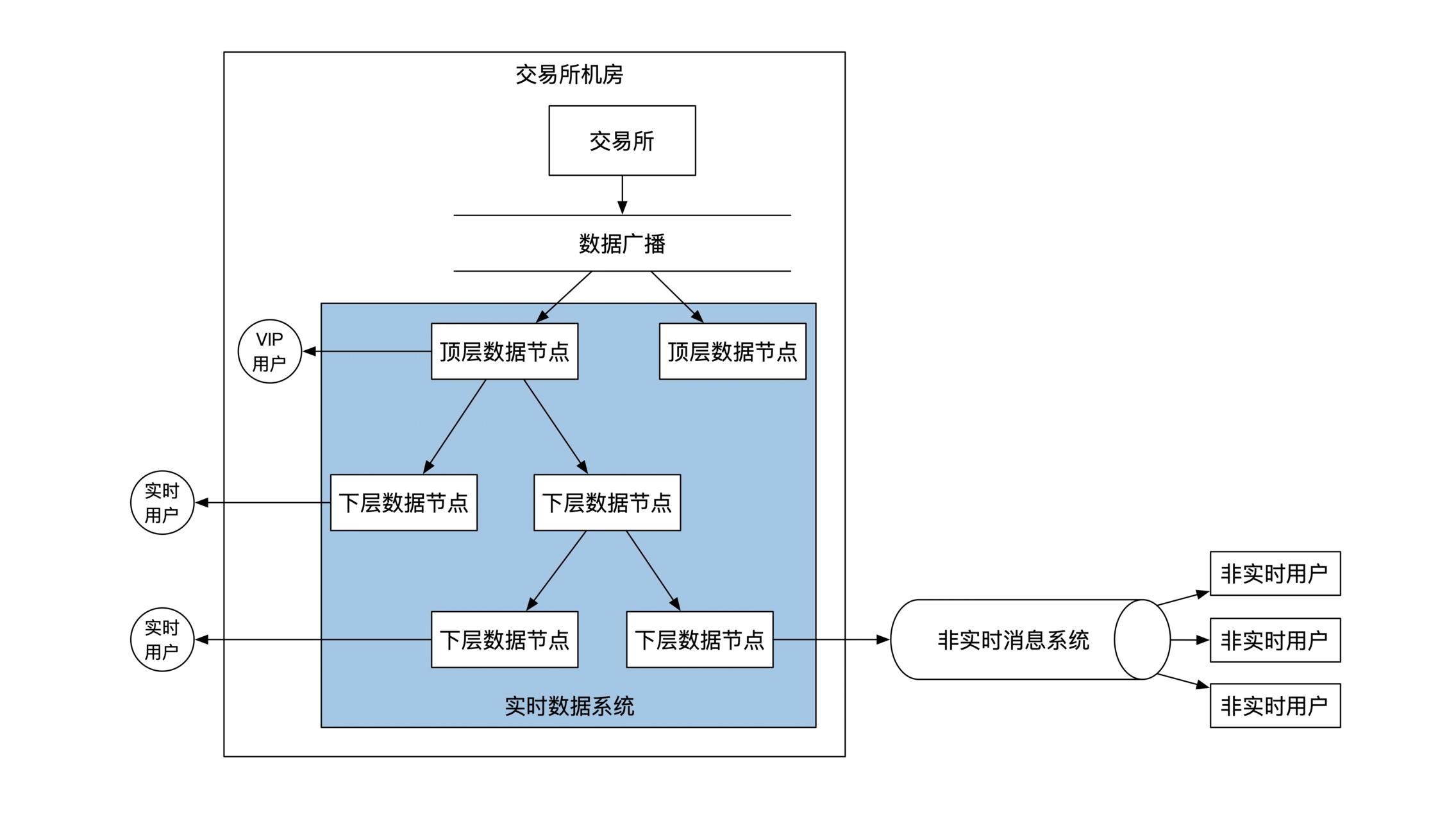
金融系统的数据库选择
数据按照关系类型可以分为以下三种,分别对应三种类型的数据库:
- 图数据类型: 图数据库
- 没有关系的数据类型:时序数据库
- 树状数据类型:关系型数据库
时序数据库
金融市场数据一般都是时间序列数据,普遍使用时序数据库。其中 KDB 是最主要的金融行业时序数据解决方案,适用数据范围 GB~TB,有专门的查询语言。
双时序数据库
金融行业用一种特殊的双时序数据库,解决历史数据指标的查询问题。
譬如 2018年4月(TT,记录时间) 公布了2018年3月(VT,发生时间)的 CPI 指数,粉红色区域是数据的可见范围。
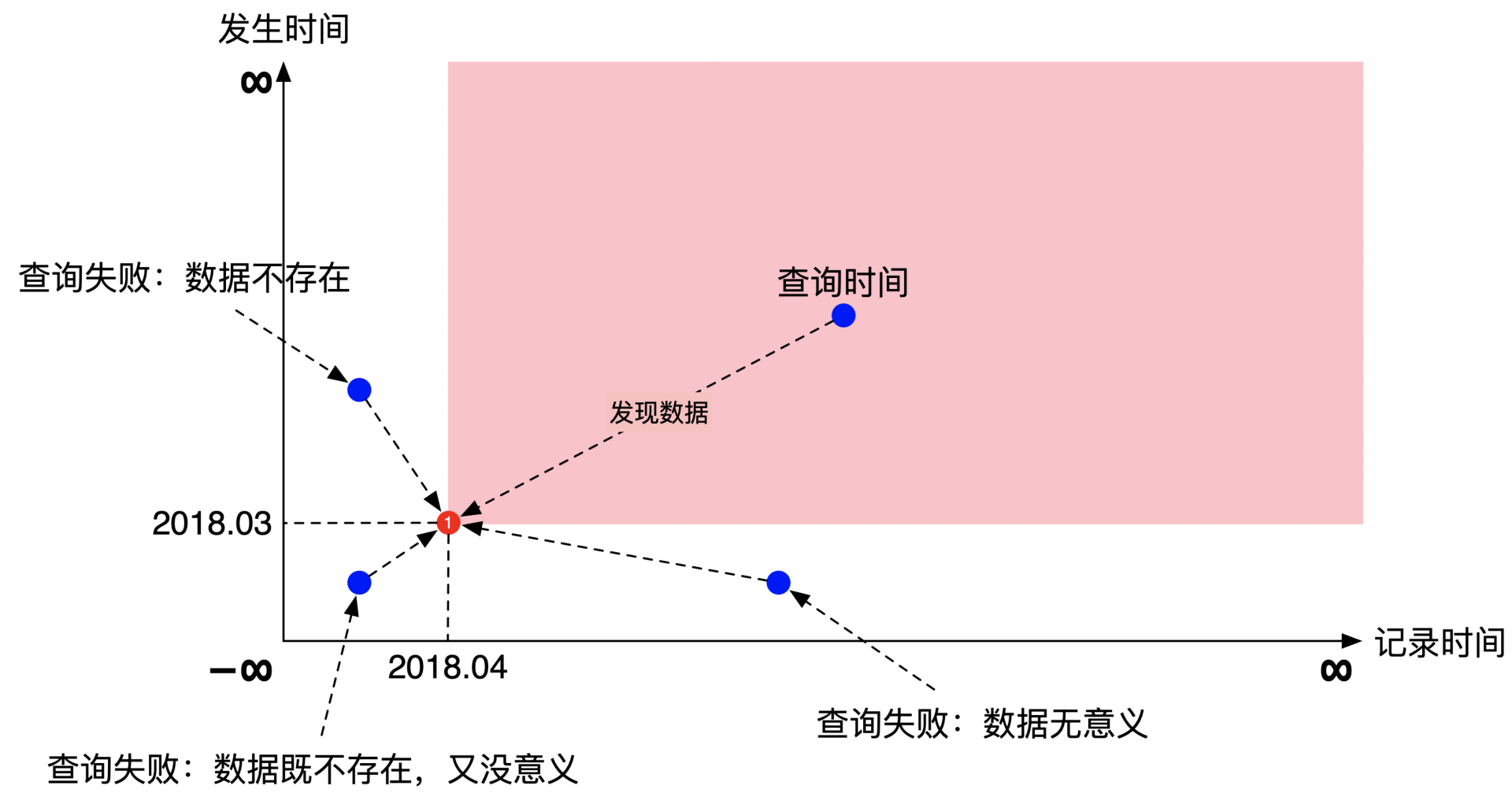
双时序数据库中的数据可见范围,即「在特定时刻下查询某个数据指标」应该用哪份数据。
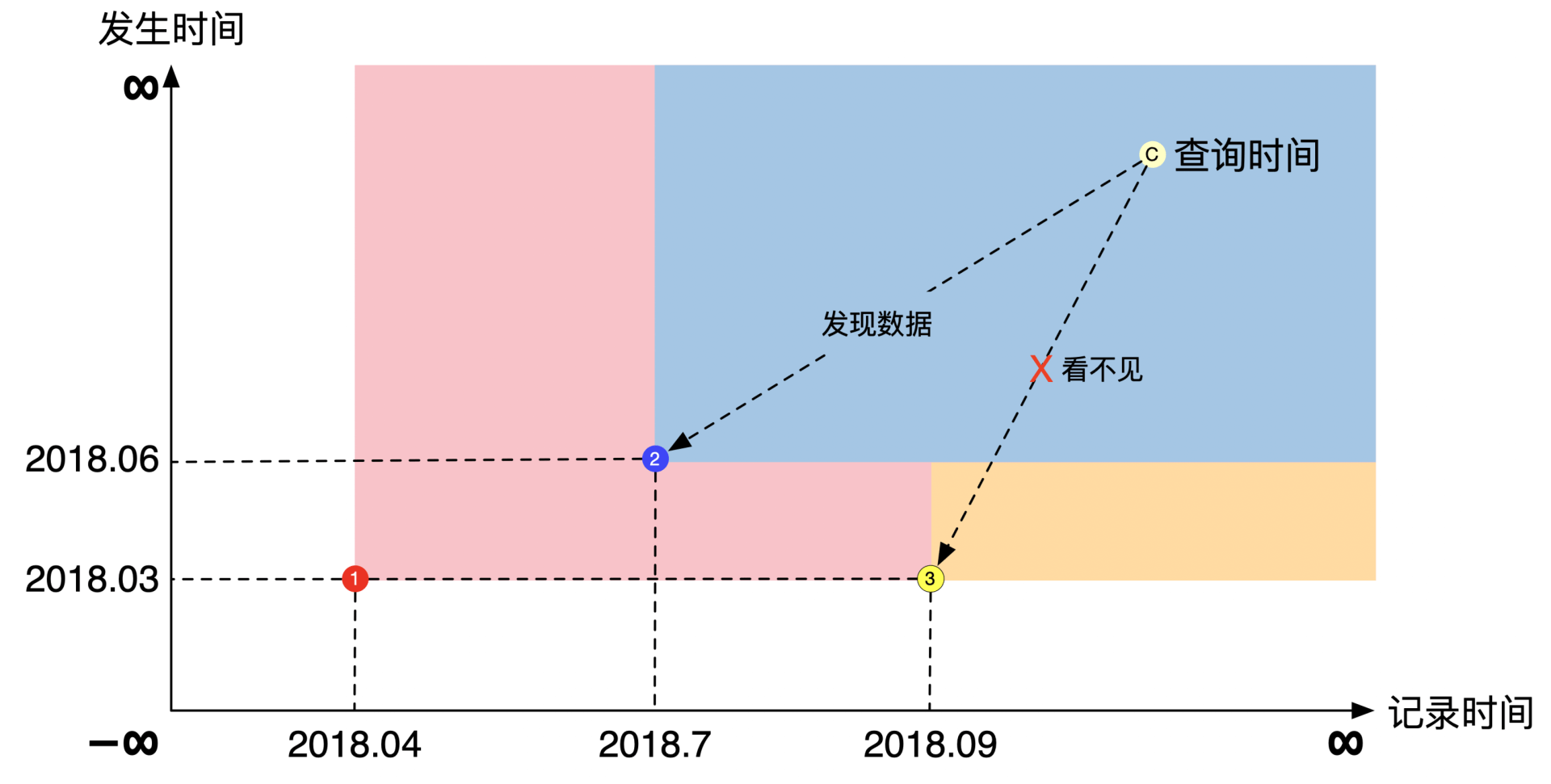
假设 2018年4月发布2018年3月的CPI,2018年7月发布2018年6月的CPI,2018年9月修正了2018年3月的CPI。在 2018 年10月查询2018年9月的CPI指标是,用目标时间所在方块的左下角数据:
2018年10月时,9月的CPI数据还没有工作,使用最近一次的CPI数据,即 6 月份的数据
关系型数据库
关系型数据库具有「对象关系阻抗不匹配(Object relational impedance mismatch)」,将对象数据存放到关系型数据时需要需要进行额外的翻译,两种数据描述方式互相冲突。
- 面向对象编程的对象之间关系形成图,用数学上的图论研究
- 关系数据库基于关系代数,是同构列表组成的集合,用数学上的集合论研究
- 将对象存储到关系数据库的过程,是将图论翻译到集合论的过程
NewSQL/NoSQL 试图解决对象关系阻抗不匹配,解决了对象的存储问题,没有完美解决对象的查询问题。NewSQL普遍采用分布式架构,二级索引一般采用最终一致性,会导致查询不准。
金融行业主力使用的还是关系型数据库,单机事务极大简化了架构难度。迫不得已的时候,才会使用分布式存储,升级成 异步处理架构。
金融系统的数据处理架构
事件溯源(Event Sourcing)是金融行业使用的数据处理架构。
事件溯源的概念
事件溯源是指将所有操作(无论多么复杂)都拆解成命令、事件和状态的组合。
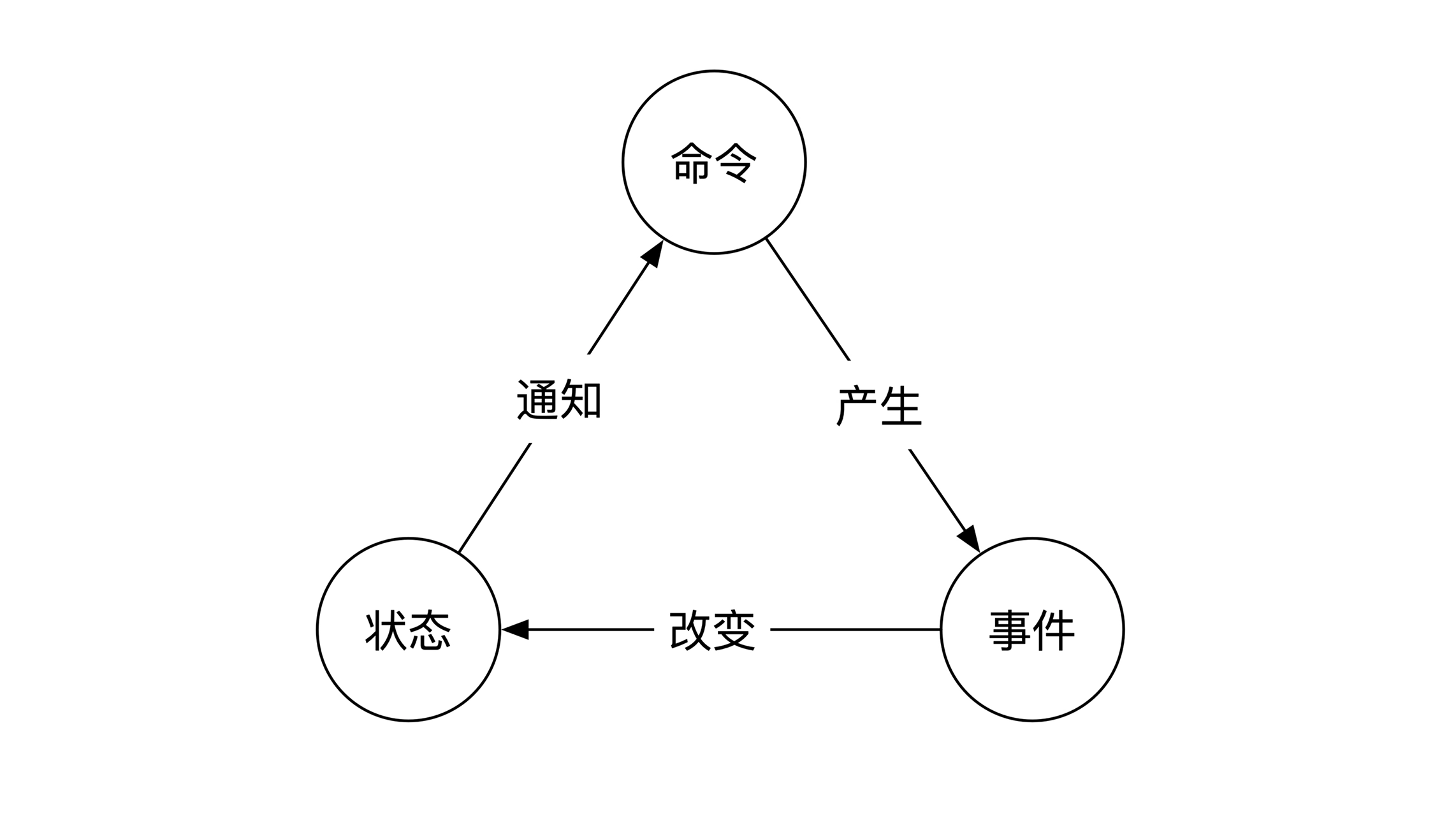
一个复杂的操作,可以用下面的简单组合描述:
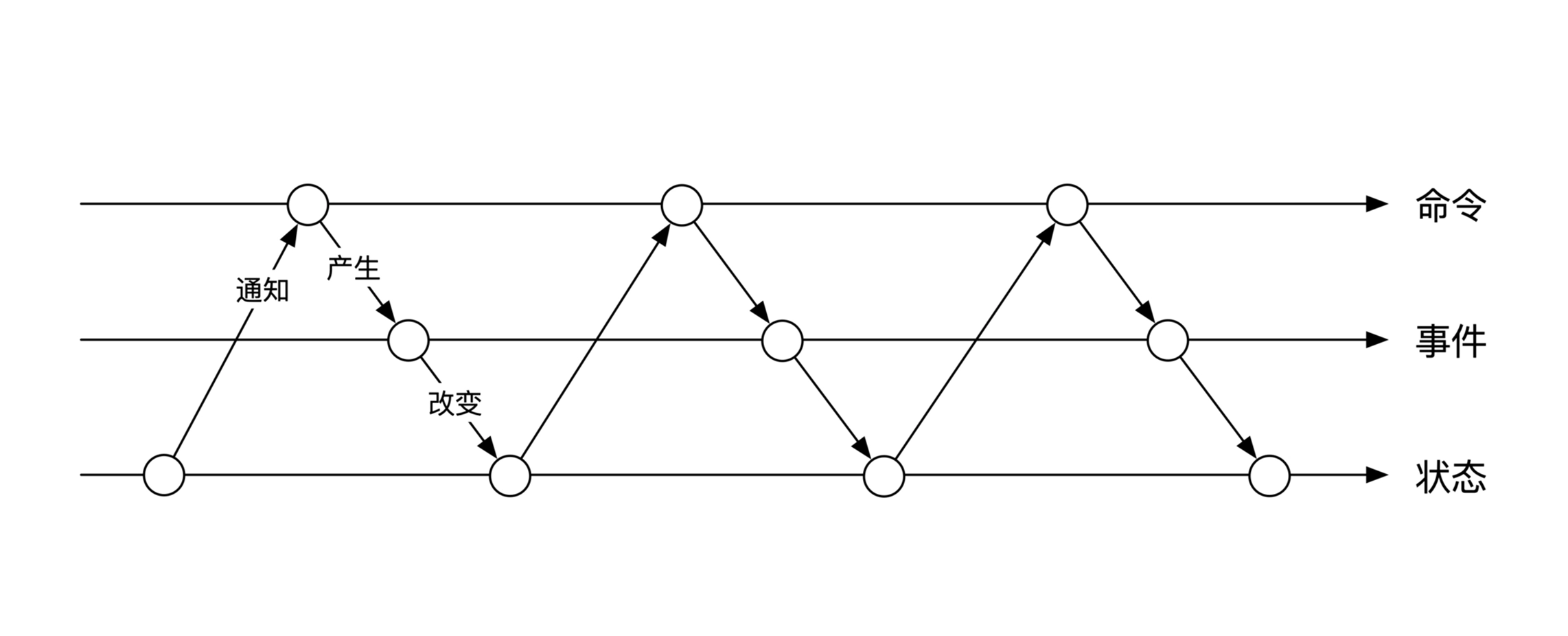
例如转账操作,用事件溯源的方式描述如下:
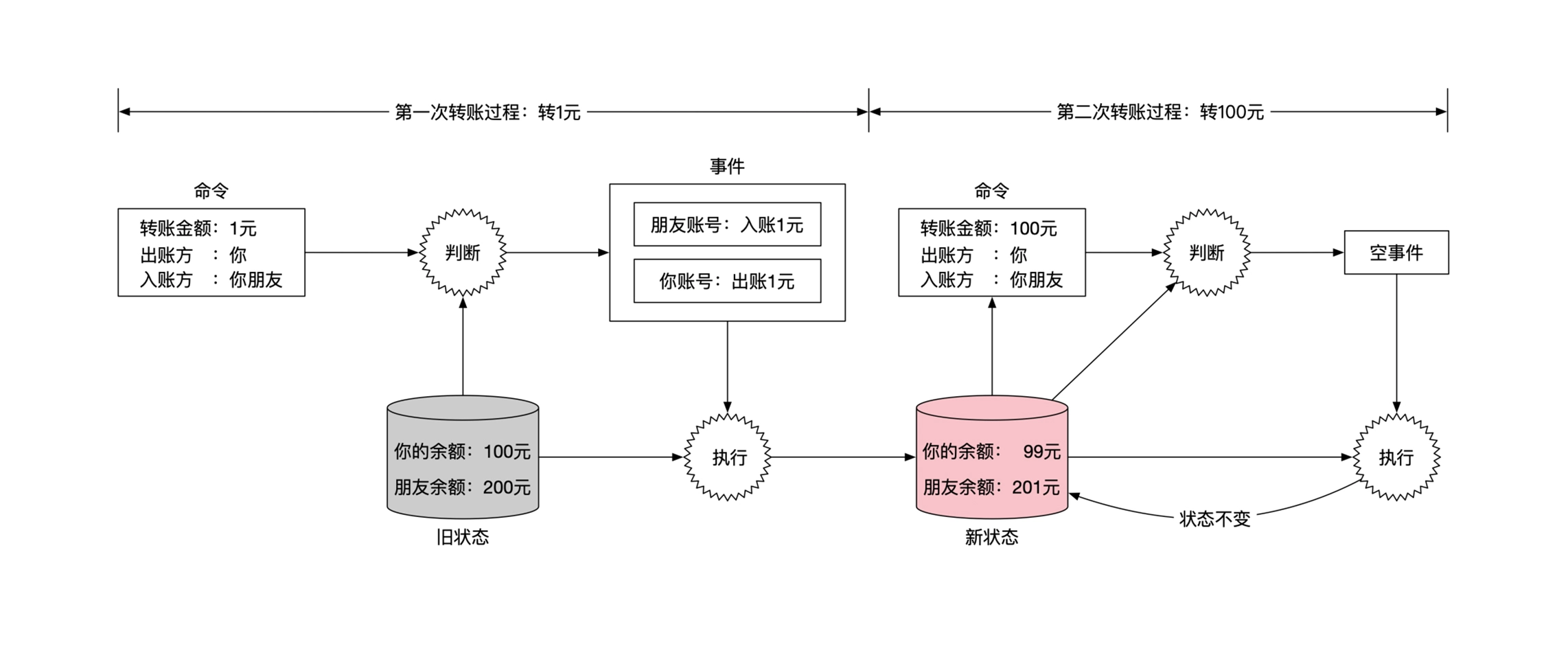
命令/事件都要有确定顺序,如果顺序变化了,就是另一种结果:
事件溯源的实现
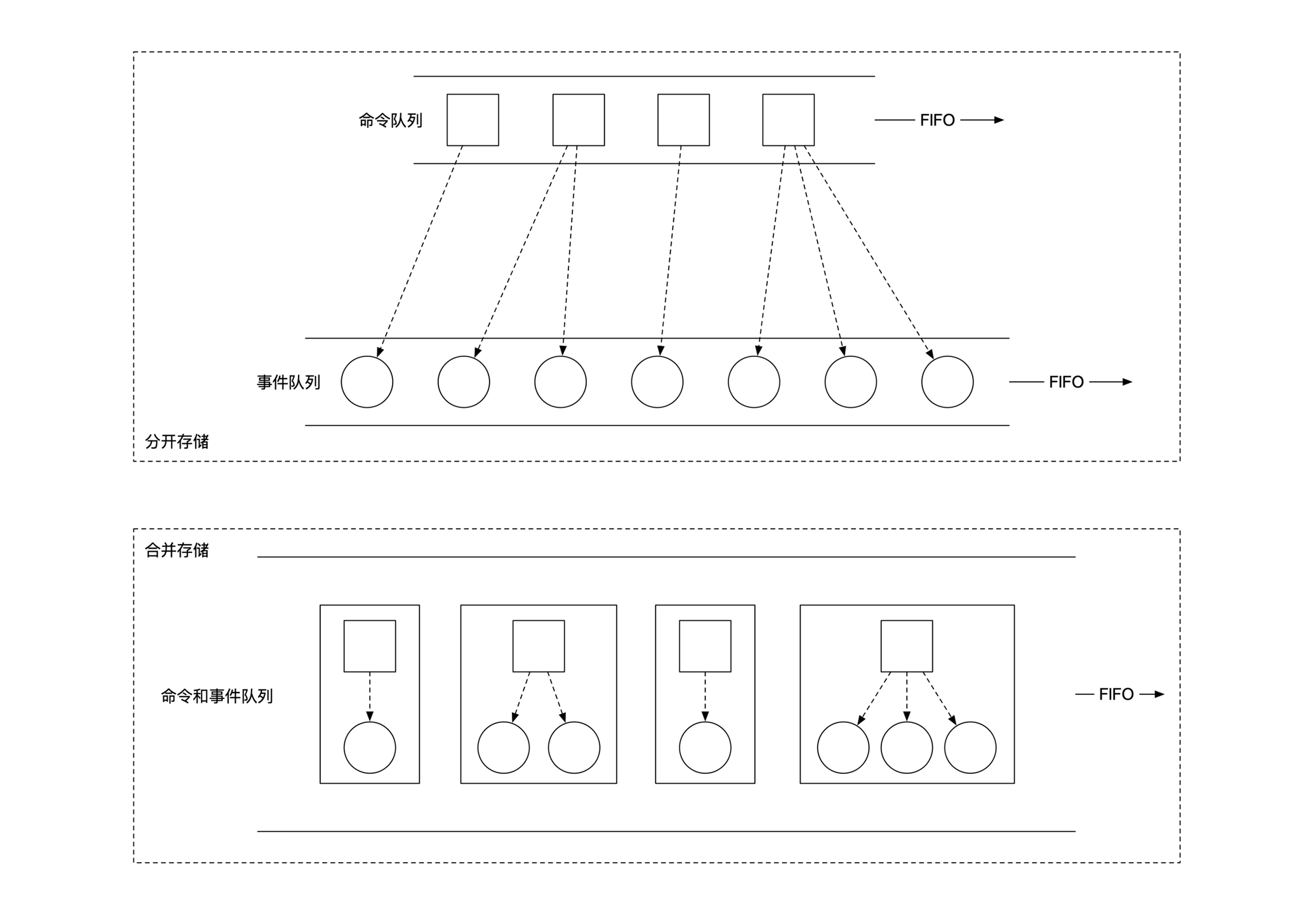
事件溯源中命令/事件都需要保证顺序,采用队列模型,用顺序写磁盘文件的方式实现:
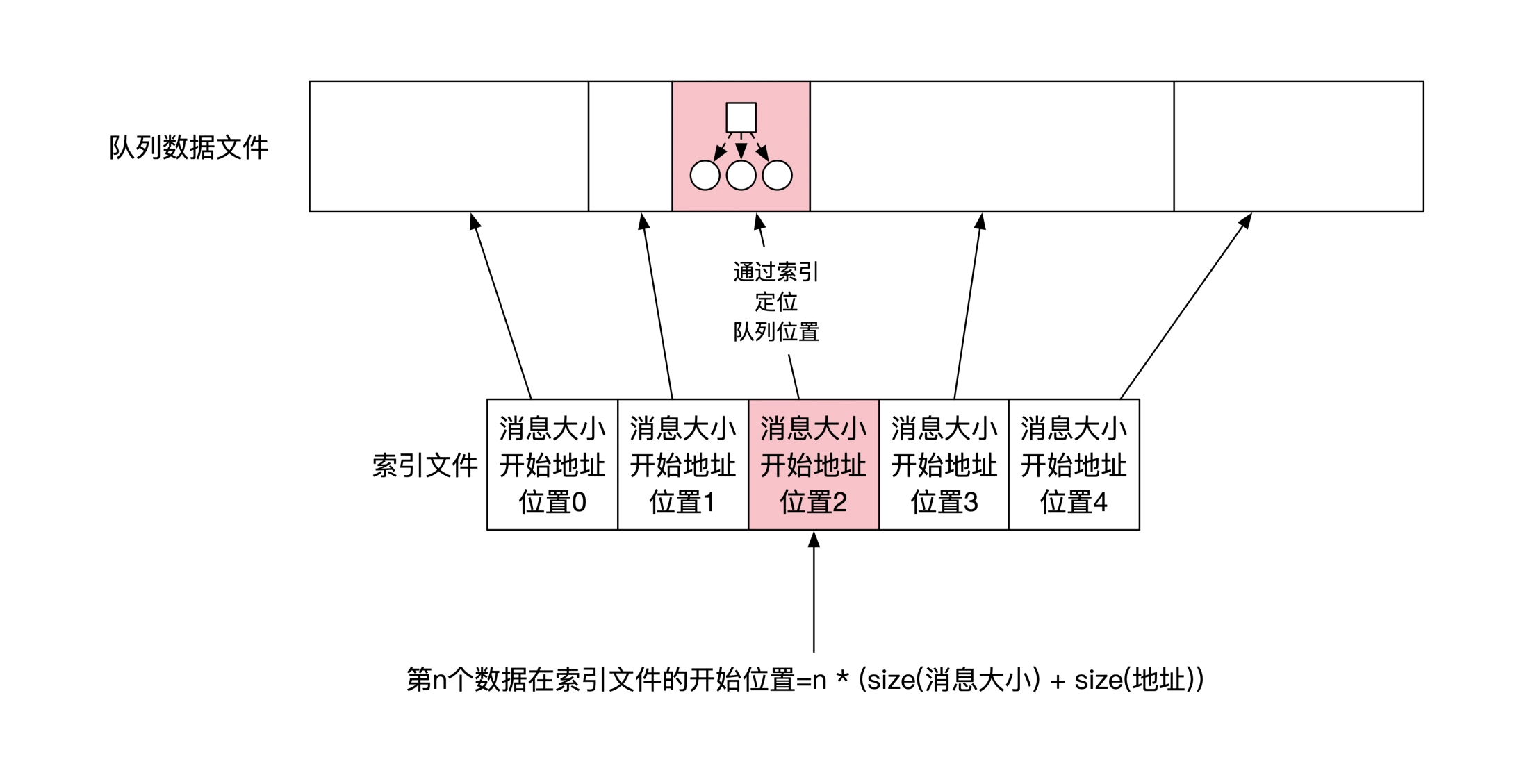
使用「自动机模型」实现事件执行、状态变更:
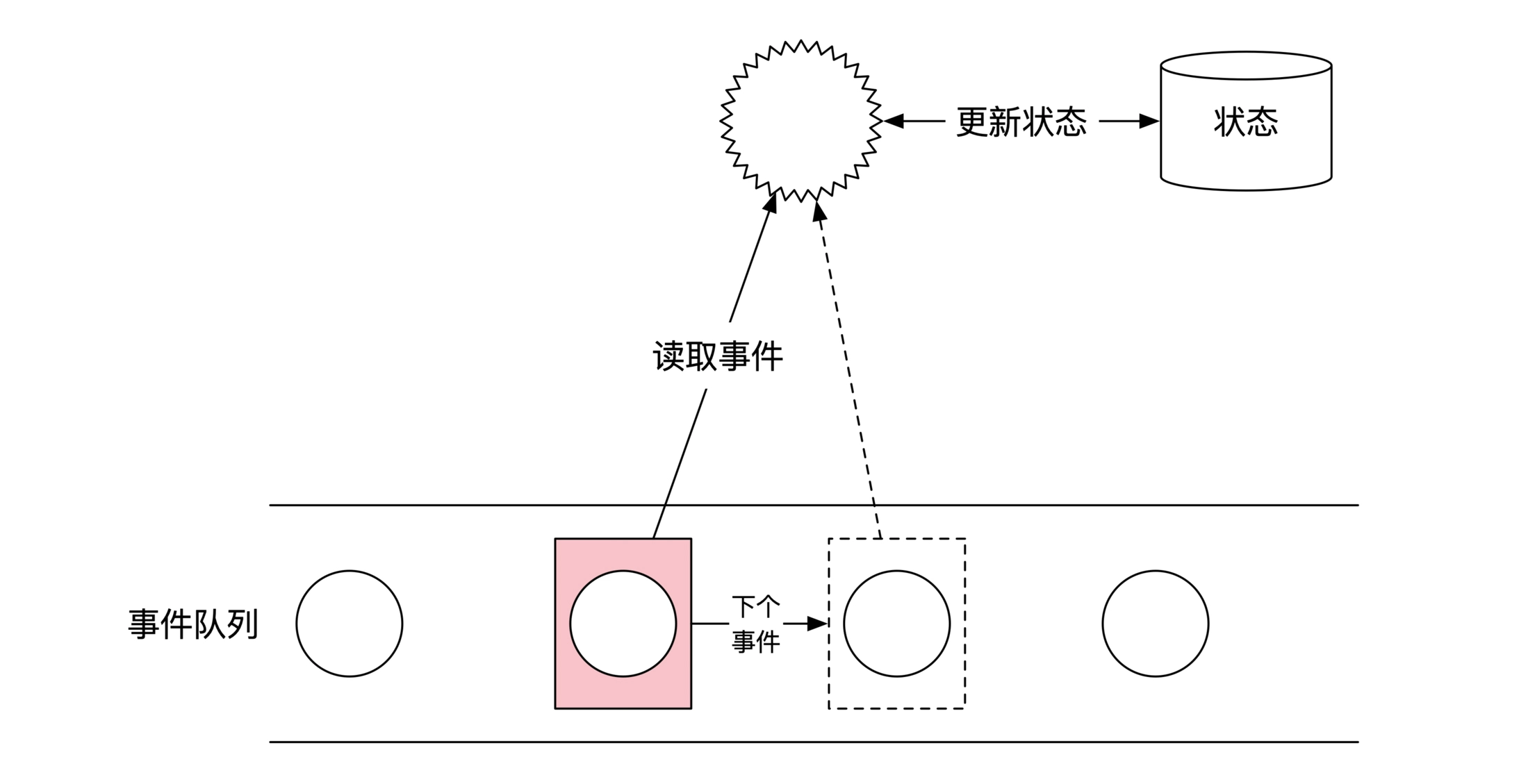
自动机需要保证 只要开始状态一致,相同事件的执行结果一定是相同的,编码时要注意:
- 不使用随机数,避免每次执行产生不同结果
- 不使用外部输入,避免外部数据数据变化导致结果发生变化
通过把事件加载到一个读模式自动机,实现任意时刻事件和状态的查询:
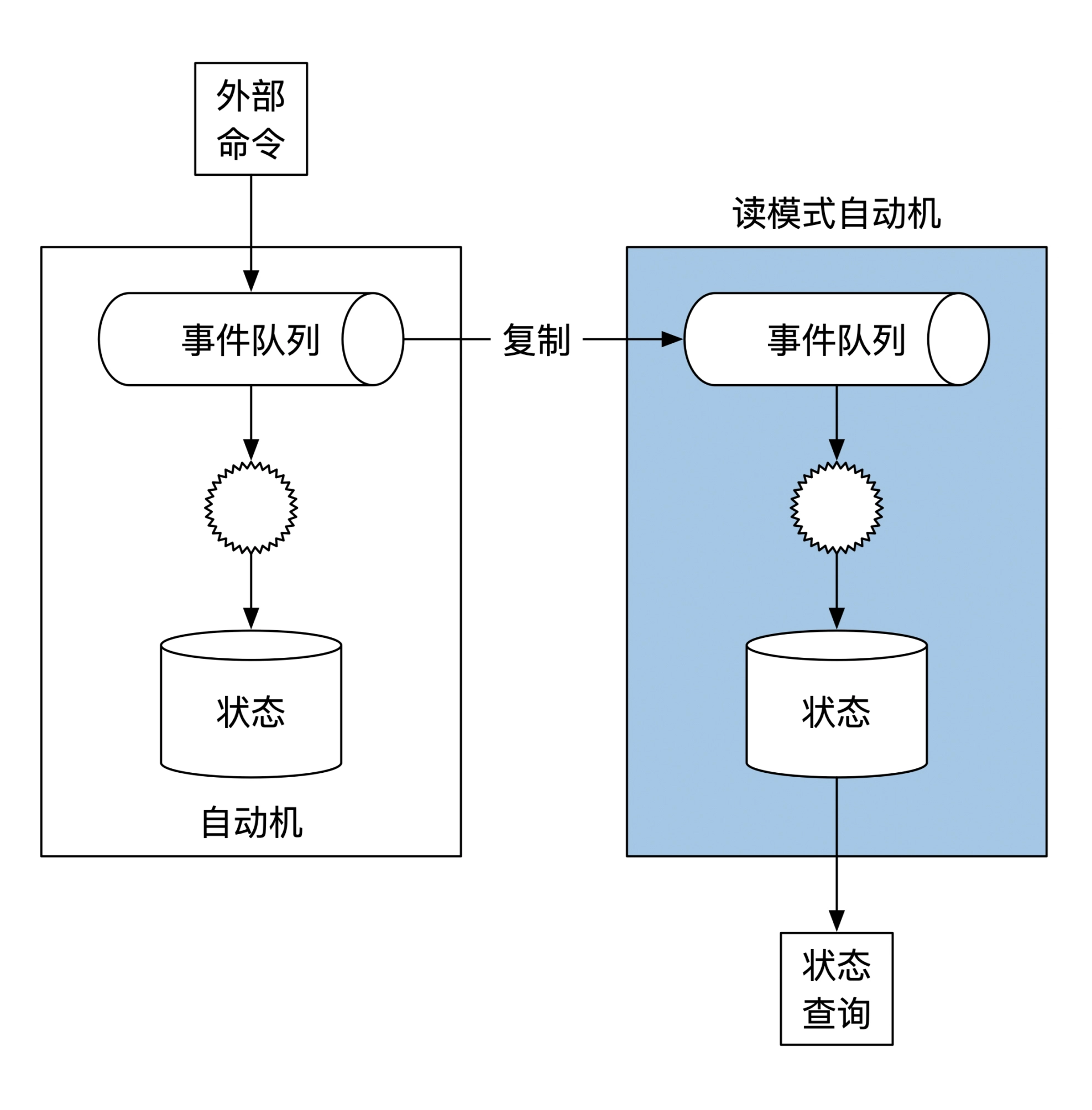
事件溯源的使用
拥有事件溯源系统后,就具备了用「时光机审计」、「事件容灾」的能力.
时光机审计:回退到任意一个过去时刻,重新执行事件,检查每个事件执行的准确性。
事件容灾:状态数据全部丢失后,用事件文件从初始状态恢复出状态数据。
可以使用「快照」技术缩短恢复时间,金融系统通常每晚12点进行「日切」,并且按月/季度/年份进行清点:
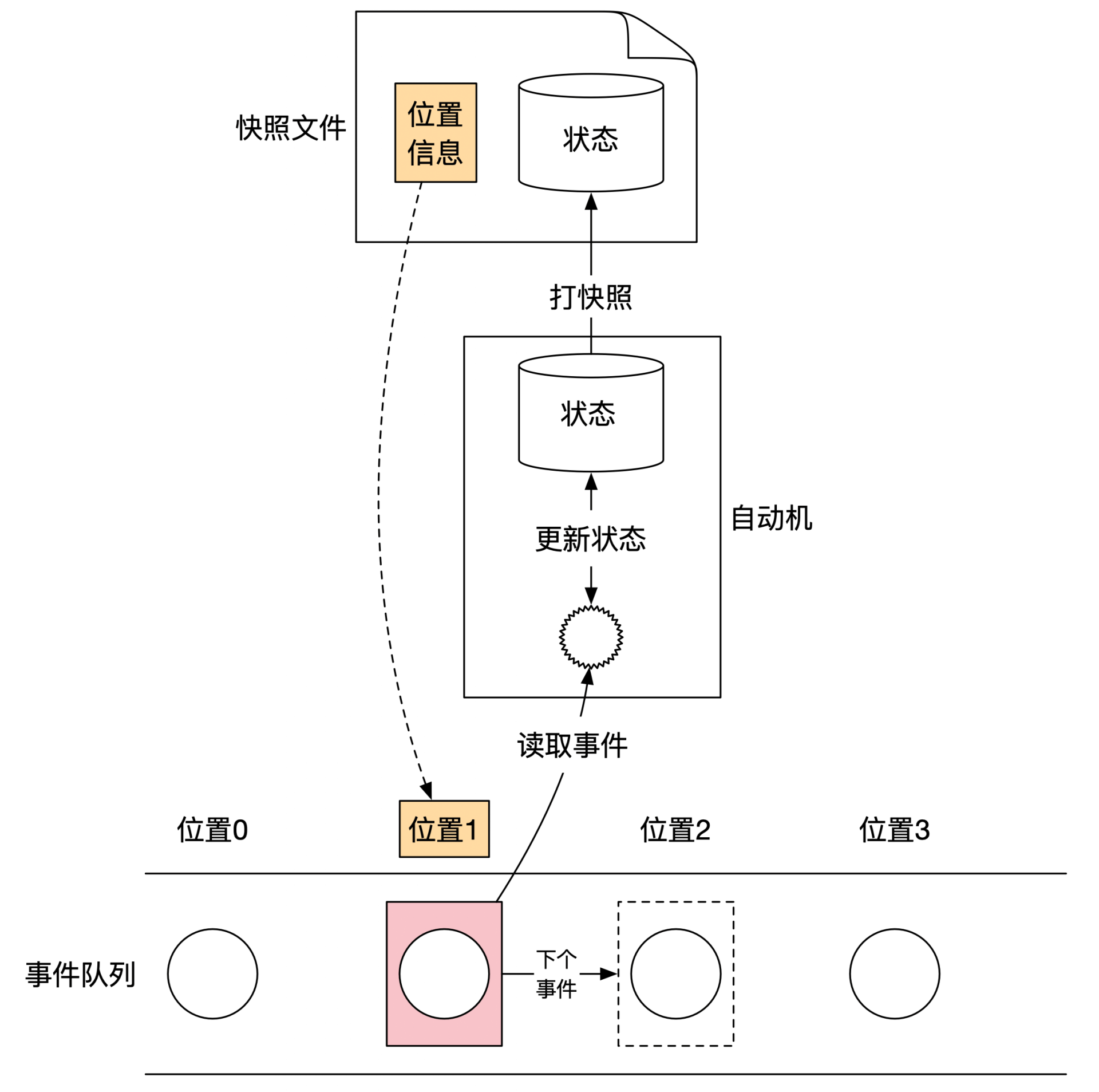
事件溯源的本质:不可变架构
事件溯源实际是一种不可变架构/Immutable Architecture,数据只能追加写入,不能修改,数据一旦生成不能再发生变化。
数据分为「事件」和「状态」两类,任何一个事件的状态等于之前所有事件效果的累计:
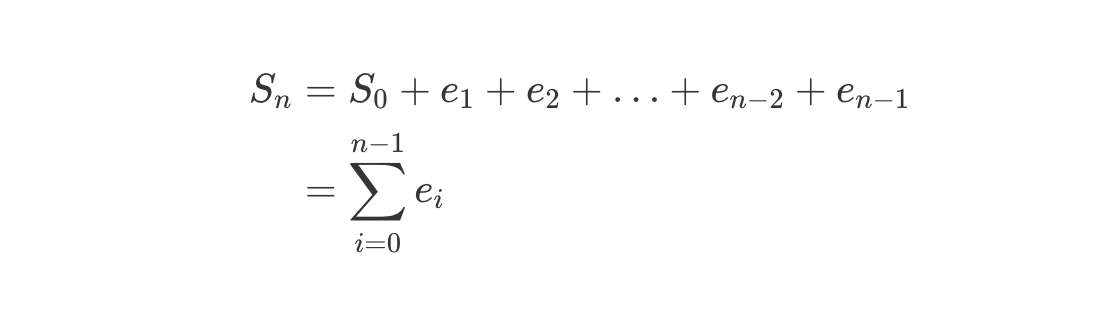
金融系统的运算结果准确性
金融系统运算结果的准确性,需要从「事前」「事中」「事后」三个阶段进行保障。
事前保障:输入正确
第一:要查询到正确的数据,用双时序数据库等技术获取到「特定时刻应该使用的数据」,并且要对数据进行完整性校验。
第二:系统间进行消息传递时,做到不乱序、不丢失、不重复。中游用消息中间件,下游实现实现重复消息的幂等。
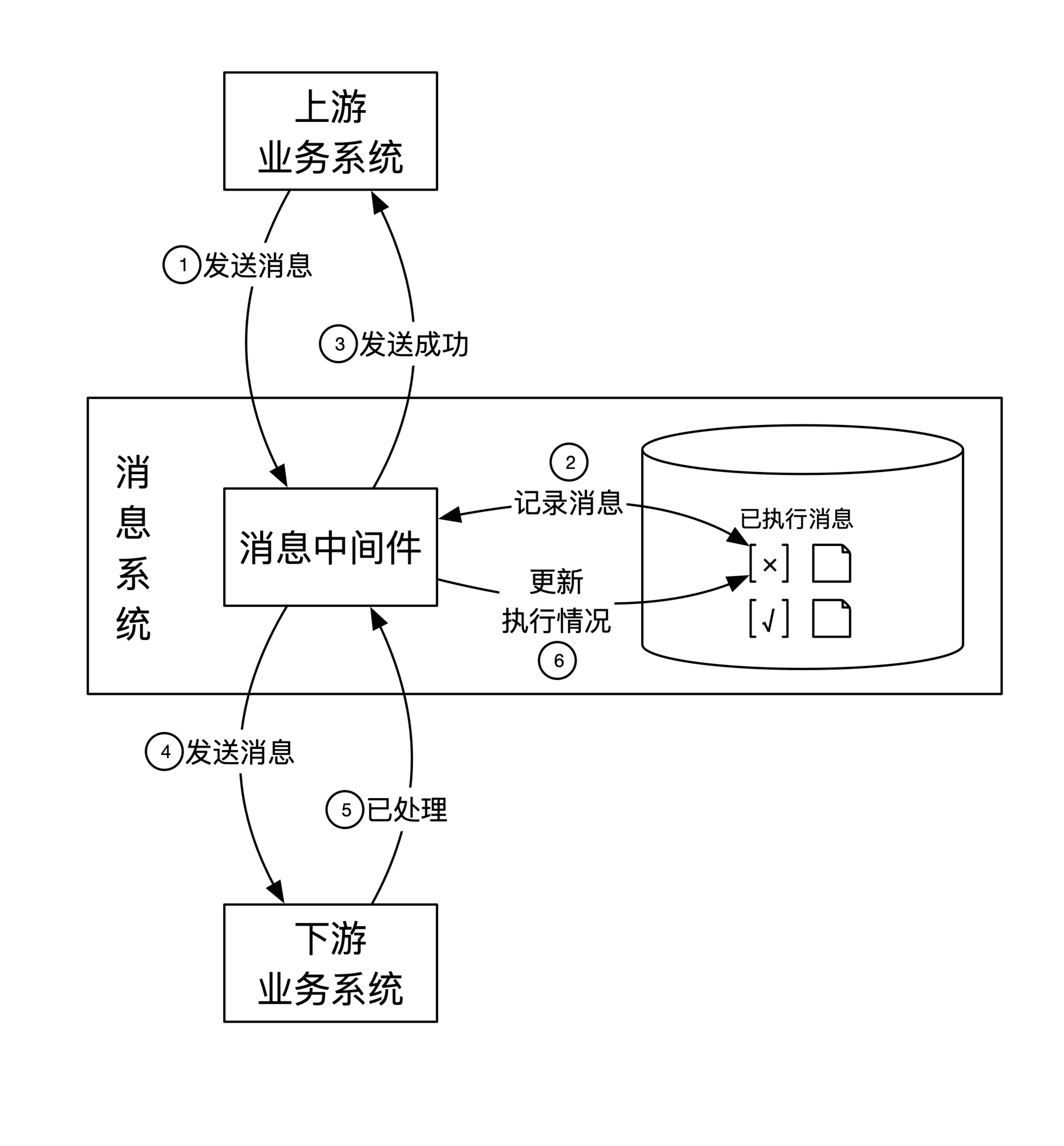
事中保障:过程正确
使用函数式编程,所有数据不可修改、函数没有随机性。函式式编程在金融系统有大规模应用:
- 高盛发明了函数式编程语言 Slang,用它实现了数据系统 SecDB,这个语言貌似不对外:Where can I learn more about Slang and SecDB
- 摩根士丹利发明了 A+,修改了 Scala
- Jane Street 使用 Ocaml
- 渣打银行使用 Haskell
- 金融行业里使用的时序数据库 kdb 使用的也是函数式语言
事后保障:多系统验证
事后主要是对结果进行验证,由于采用了双时序数据库和事件溯源,可以无限次的反复验证,通过反复验证确保结果准确和发现问题。
飞机和航天器材的软件系统一般验证 3 次,会有四个系统同时工作,至少 3 个结果相同的情况下,才能输出结果。
金融软件一般验证 1 次。
为什么需要事后保障摘录一段知乎上的回答,宇宙射线对计算机讯号传递的错误率有多大影响?,原报道神舟飞天的秘密–独家揭秘神舟九号的太空计算机:
太空中,计算机最怕什么?专家说宇宙射线是计算机运行最大的危害。地球上的计算机,因为有地球大气层的保护,可以挡住大部分来自太阳的高能粒子射电流,而在太空,天宫一号控制计算机将遭到质子、中子、重离子、电子的轰炸。“总剂量效应”和“单粒子效应”是两种典型的太空射线对空间计算机造成的损害,也是星载计算机同其它地面计算机的最大不同。专家所说“闩锁效应”是指空间重粒子作用到计算机芯片造成短路,进而引发“可控硅”效应,严重的会造成计算机电路“烧毁”。若发生“闩锁效应”,地面控制中心的工程技术人员即可察觉,相比之下,“单粒子翻转效应”使计算机存储单元的内容发生“位翻转”,造成物理损坏,只是悄无声息地改变存储内容,造成不易发现的破坏。从天宫一号控制计算机地面遥测数据分析,天宫一号控制计算机今年已发生6次存储器单粒子翻转事件,其中有一次就发生在第二次交会对接前几小时。天宫一号控制计算机系统能有有效抵御单粒子翻转的危害,在轨稳定工作、表现优异。
单机操作的正确性保证
对单机上的数据进行操作时,面临两个问题:
-
操作到一半时发生故障,数据只改写了一半,另一半未改写,要怎么办?
-
「实际由多个步骤组成」的原子操作并发执行时,结果应该是怎样的?
第一个问题解决方法是 提供「原子操作」。
面向磁盘读写时,假设要在磁盘上写 4k 数据,写完 2k 后机器断电,之后从磁盘读取的是改写了一半的数据,磁盘无法提供原子保证。如果开发一个直接读写磁盘的服务,必须考虑数据操作的原子性。
数据库是一个典型的例子,它构建在磁盘之上,对用户屏蔽了磁盘操作。磁盘上依然会存在更新了一半的数据,但是数据库通过一系列设计让用户读不到这些不完备的数据。用户面向数据库读写时,数据操作是原子的。
依此类推,除了数据库,还有那些系统需要或提供了类似的原子保证?如果要自行实现原子操作,需要怎么做?
定义了原子操作后,引出了第二个问题, 怎样规定并发行为。
原子操作是一个逻辑概念,它指的是「一系列动作的最终结果是原子的」。在一个原子操作中,会有很多个数据处理步骤。当很多个原子操作并发执行时,这些原子内部的操作可能会同时操作同一段数据,这时候要遵循怎样的规则?
数据库给出的解决方法是定义了四种隔离级别,即四种规则,有用户根据实际情况选择。
单机操作的并发行为约定
单机上的数据并发操作时,总共有三种冲突场景:
- 写写
- 写读
- 读写
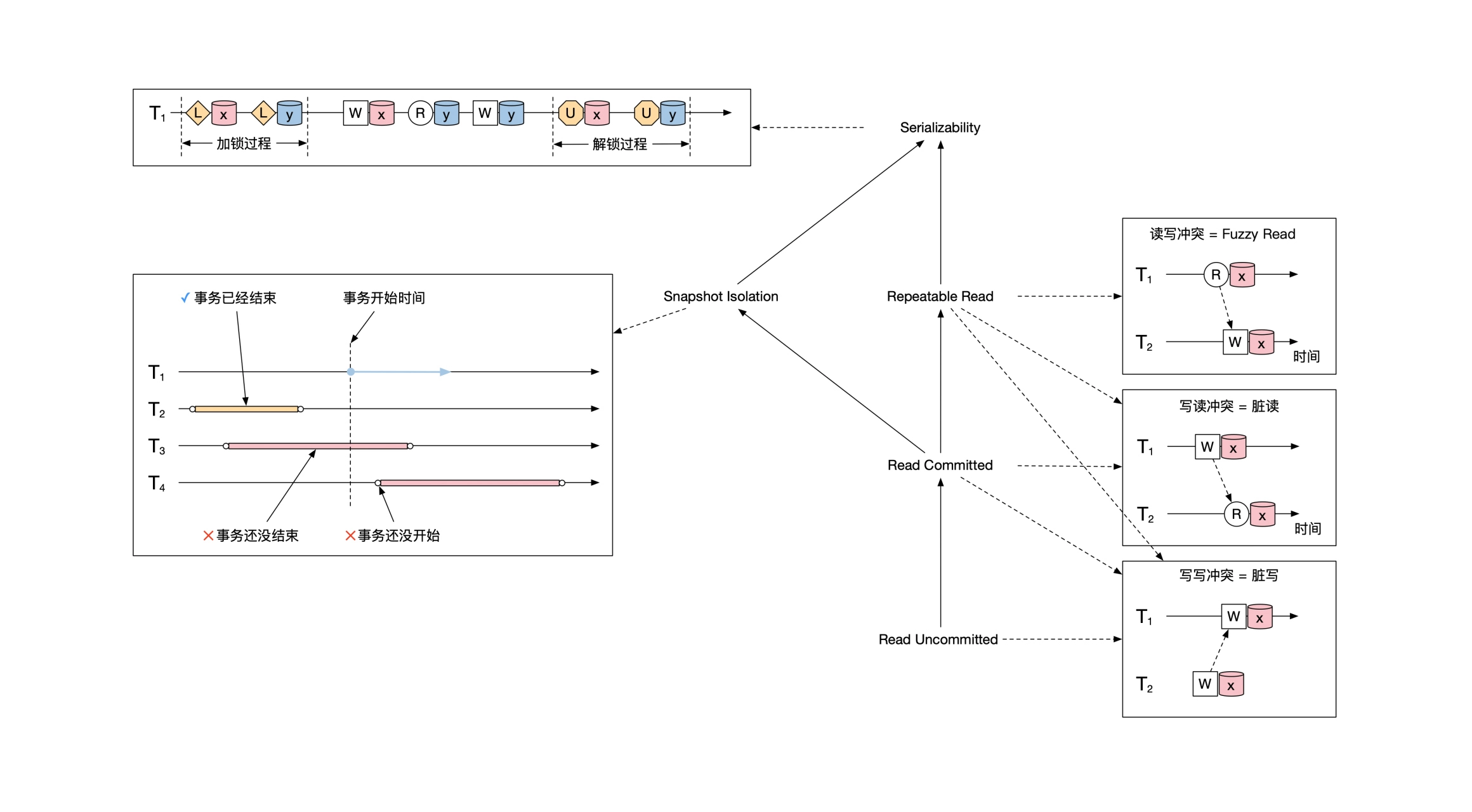
写写冲突,事务 T2 还在执行时,就被另一个事务覆写了——脏写/Dirty Write,:
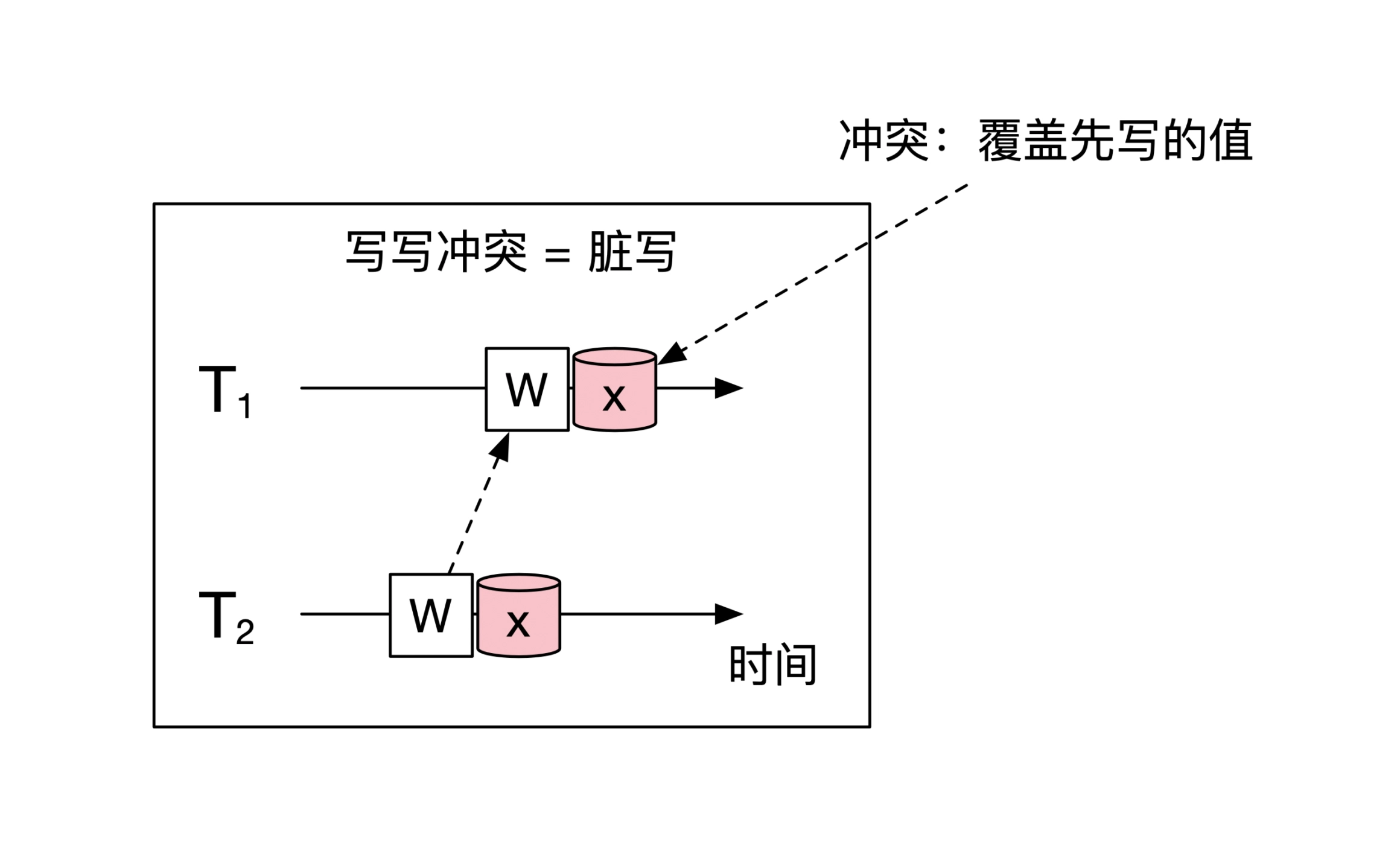
写读冲突,事务 T2 执行是读取到了 T1 改写的数值,但是随后 T1 回滚,T2 相当于读了一个不存在的数值——脏读/Dirty Read:
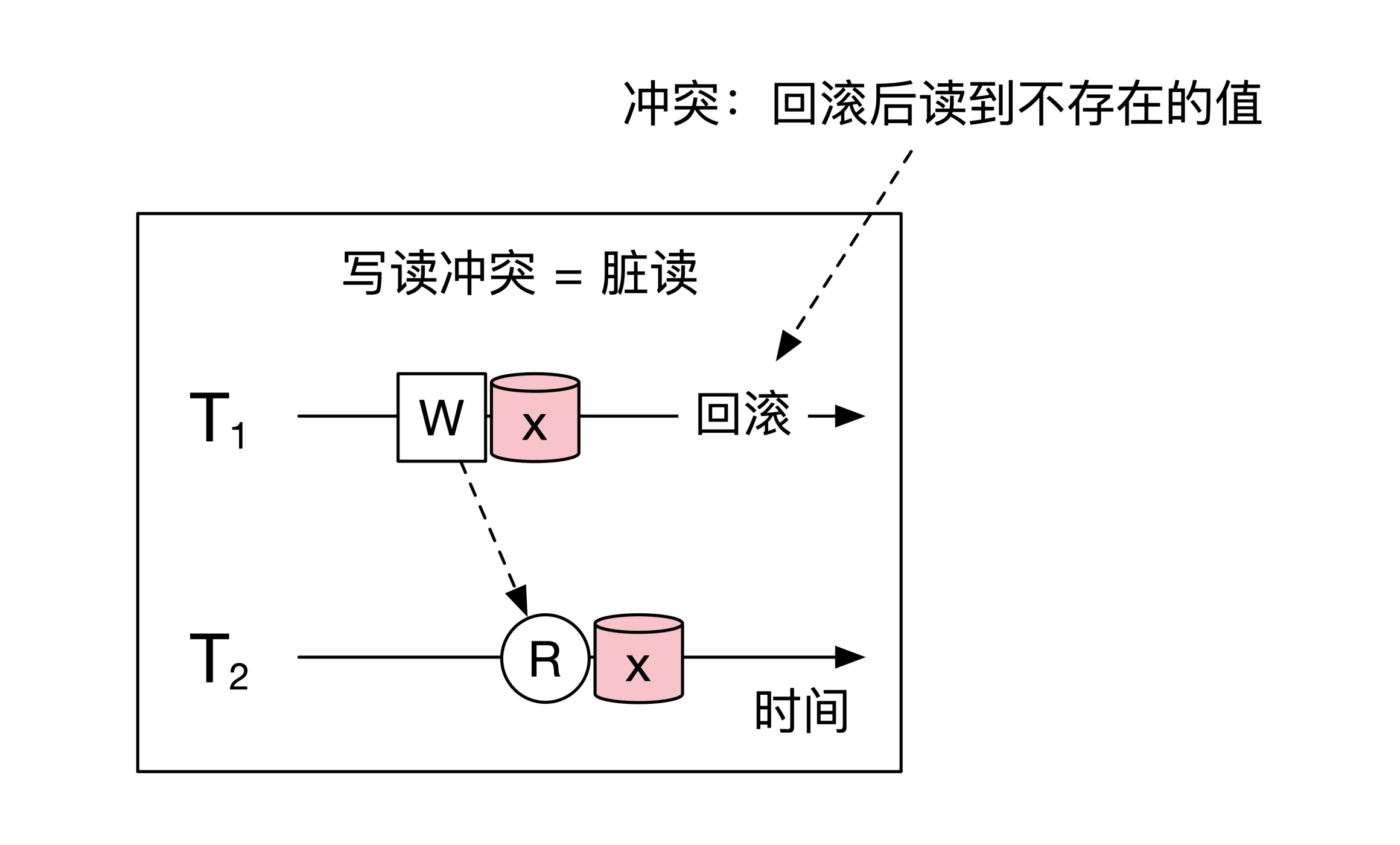
读写冲突,事务 T1 第一次读取到数值,被另一个事务改写,事务T1 再次读取时,读到一个另一个数值——模糊/Fuzzy Read:
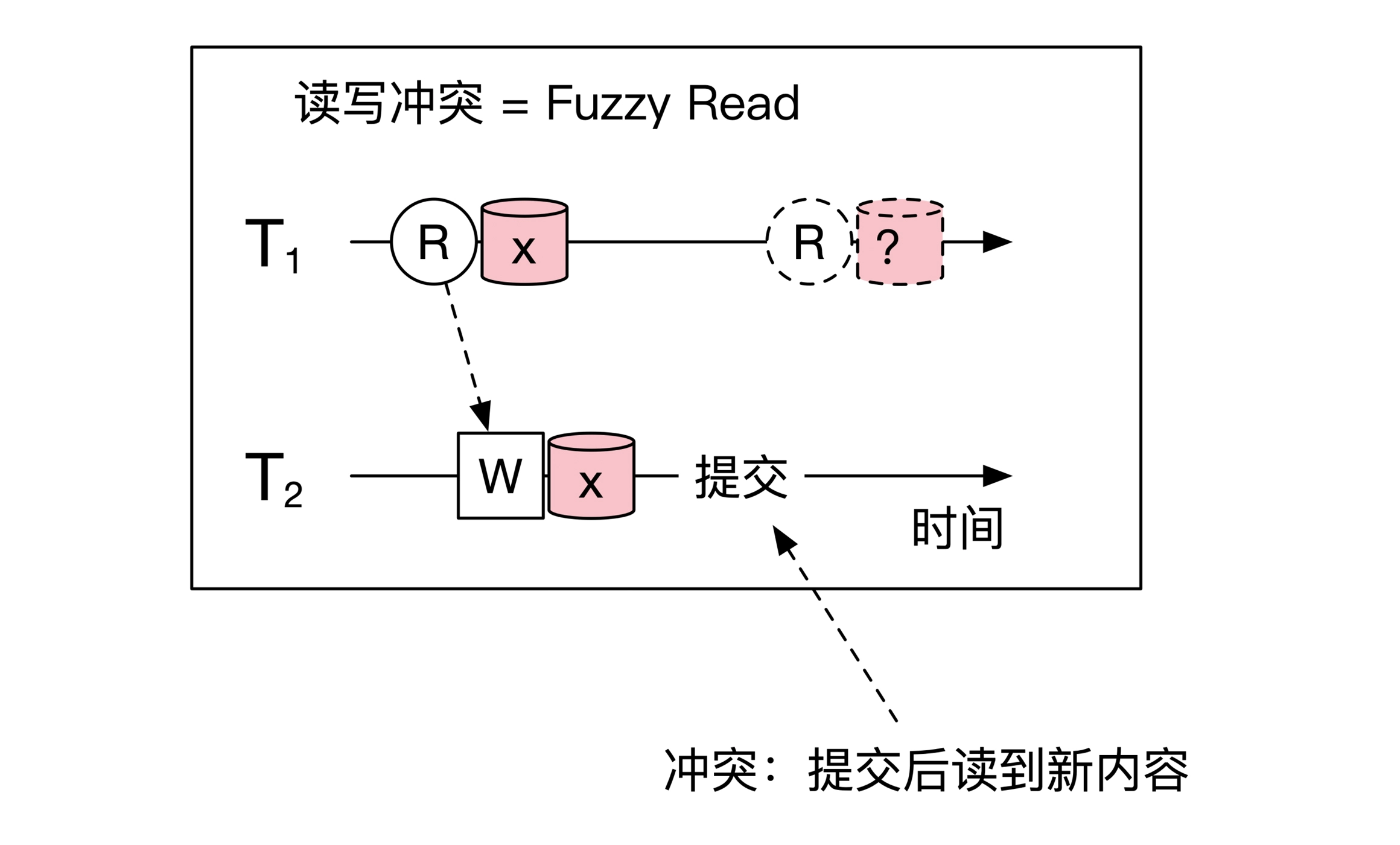
数据库作为典型的单机系统,针对以上三种冲突,设计了多种并发行为,得到广泛应用:
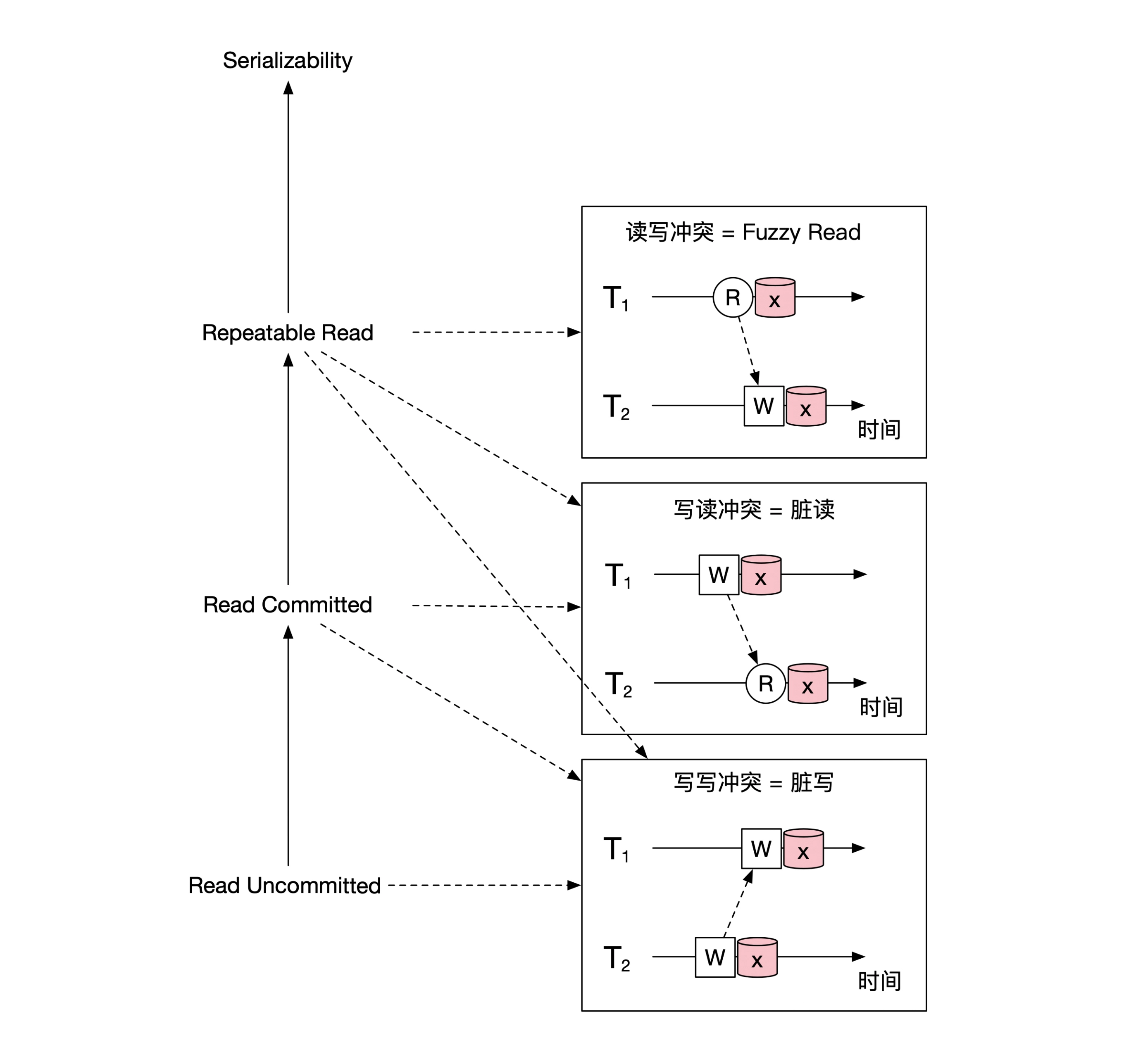
- 读未提交,Read Uncommited,能够读到事务已改写但未提交的的数据,相当于无隔离,什么冲突也没解决
- 读已提交,Read Commited,事务尚未提交的改动不允许读取,解决了 Dirty Read
- 可重复读,Repeatable Read,事务执行期间的多次读取到的数据是相同的,解决了 Fuzzy Read
- 可串行化,Serializability,多个事务并发执行的结果等同于将事务串行执行,不会有任何冲突问题
- 严格可串行化,Strict Serializability,多个事务并发执行的结果等同于按照事务的发生时间排序的串行执行,不会有任何冲突
可串行化定义和实现方法
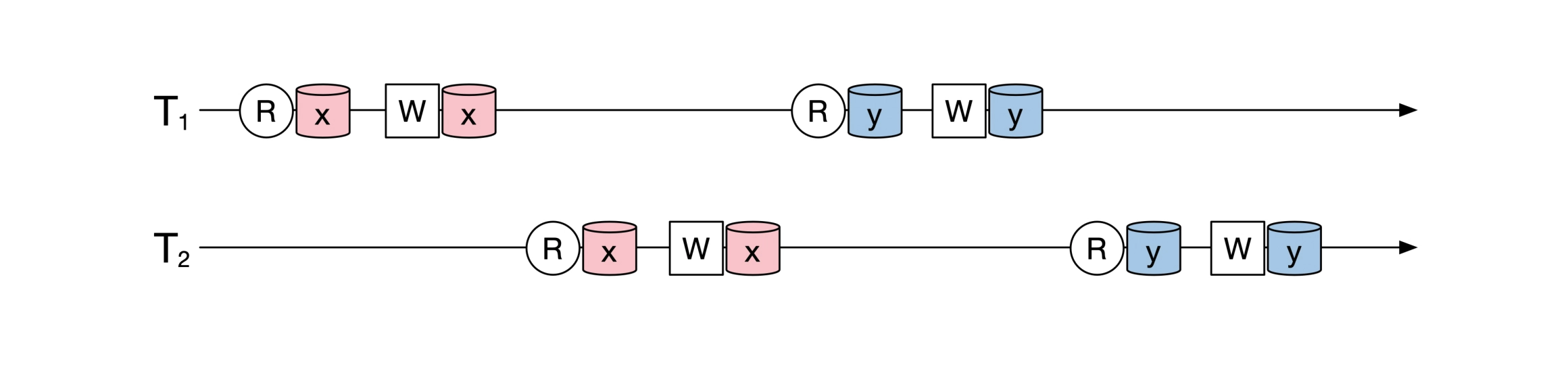
事务隔离的最高级别「可串行化」不是要求所有事务必须串行执行,而是要求事务并发执行的结果等价于这些事务按顺序串行执行的结果,只要求结果等价,不要求实际串行。如何实现等价,是系统设计的问题。
例如,下面是两个并发执行的事务,两个事务的持续时间是重叠的:
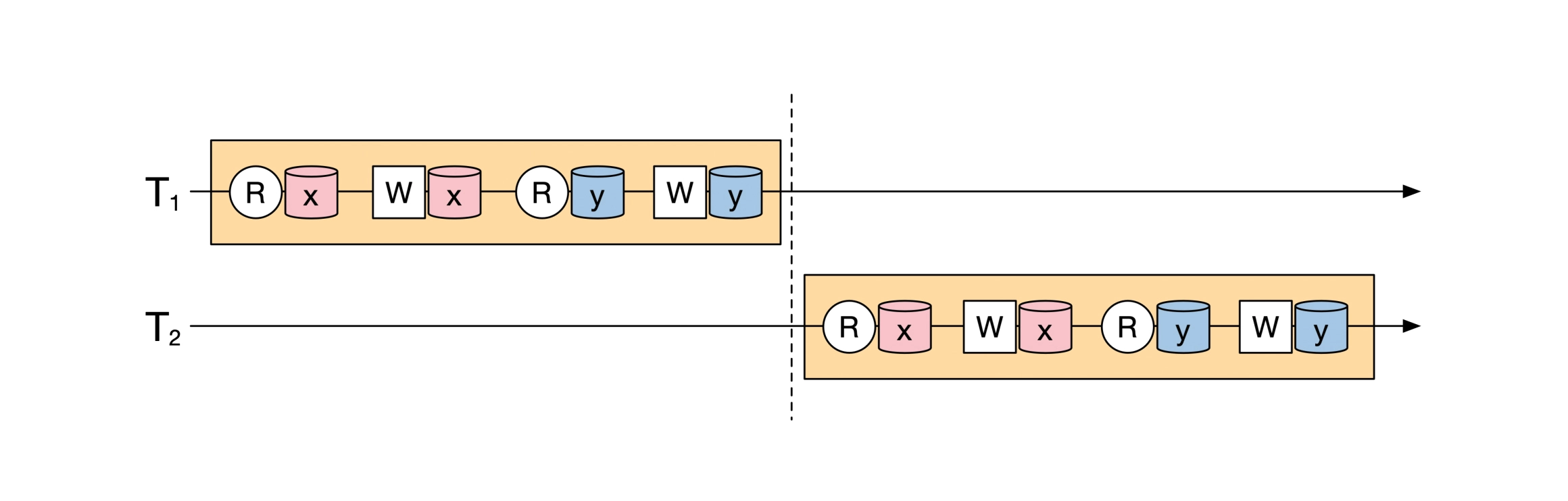
如果他们的执行结果等价于下面的操作,就是可串行化:
两阶段加锁:冲突可串行化
可串行化的一种实现方式是加锁,这种方式叫做 2PL(Two Phase Lock,两阶段锁),即在事务开始前对所有要访问的资源添加排他锁,操作完成后再解锁。 加锁的方式实现的可串行化,实际上是一种更严格的「冲突可串行化」,2PL方案不仅解决串行化问题,还解决了冲突问题。
可串行化不等于无并发冲突。譬如下面的三个事务存在冲突,但是可以串行化:
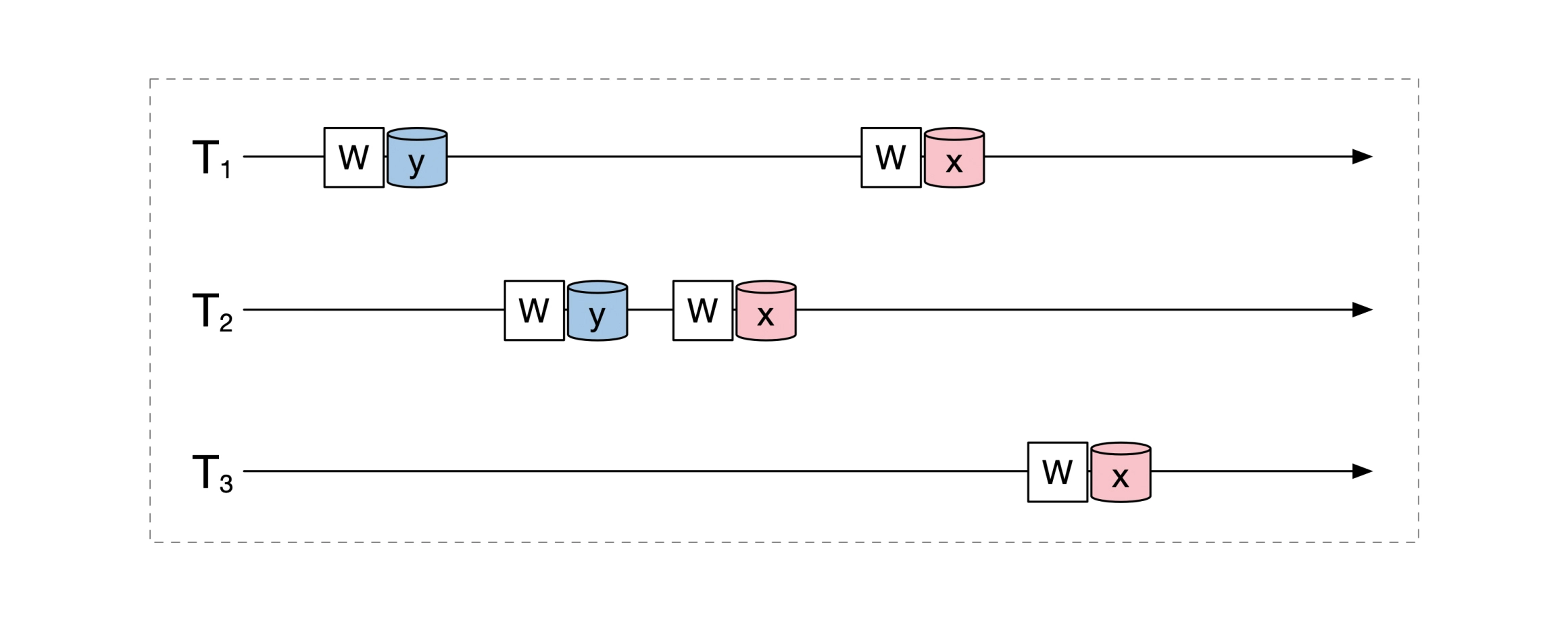
串行化调整结果,t1、t2、t3 串行执行结果和并发执行结果是相同的:
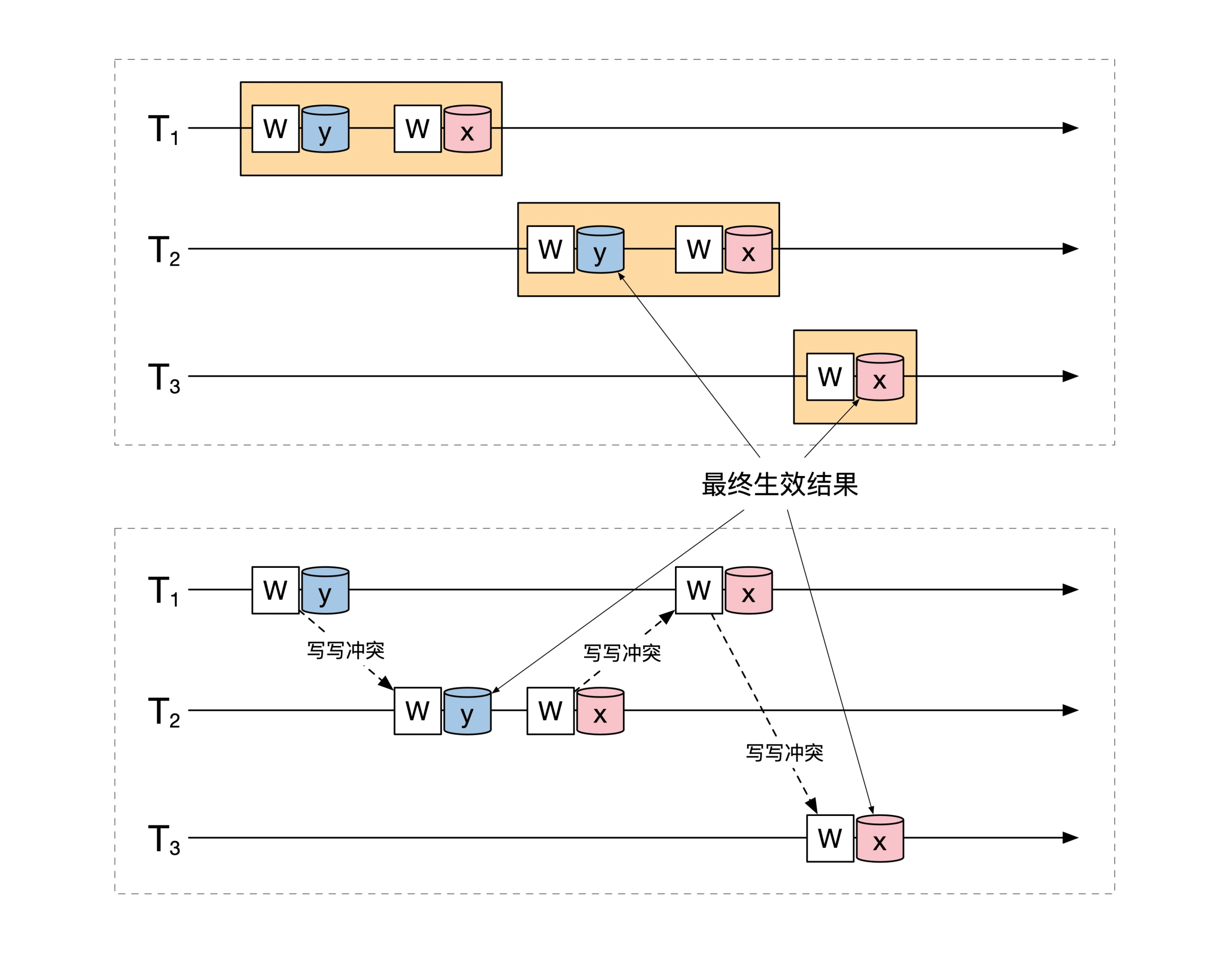
虽然存在冲突,但是这三个事务并发执行的最终结果,等价于串行执行。虽然 t1 和 t2 对 y 的写操作冲突,t1、t2和t3 对 x 写操作也冲突,但是结果依然等价于串行执行。
冲突可串行化要求两个事务之间不能有冲突,比可串行化更严格,是更彻底的串行化。按照冲突可串行化要求,上面的例子中 t1、t2 存在写冲突,能串行化但是不是冲突可串行:
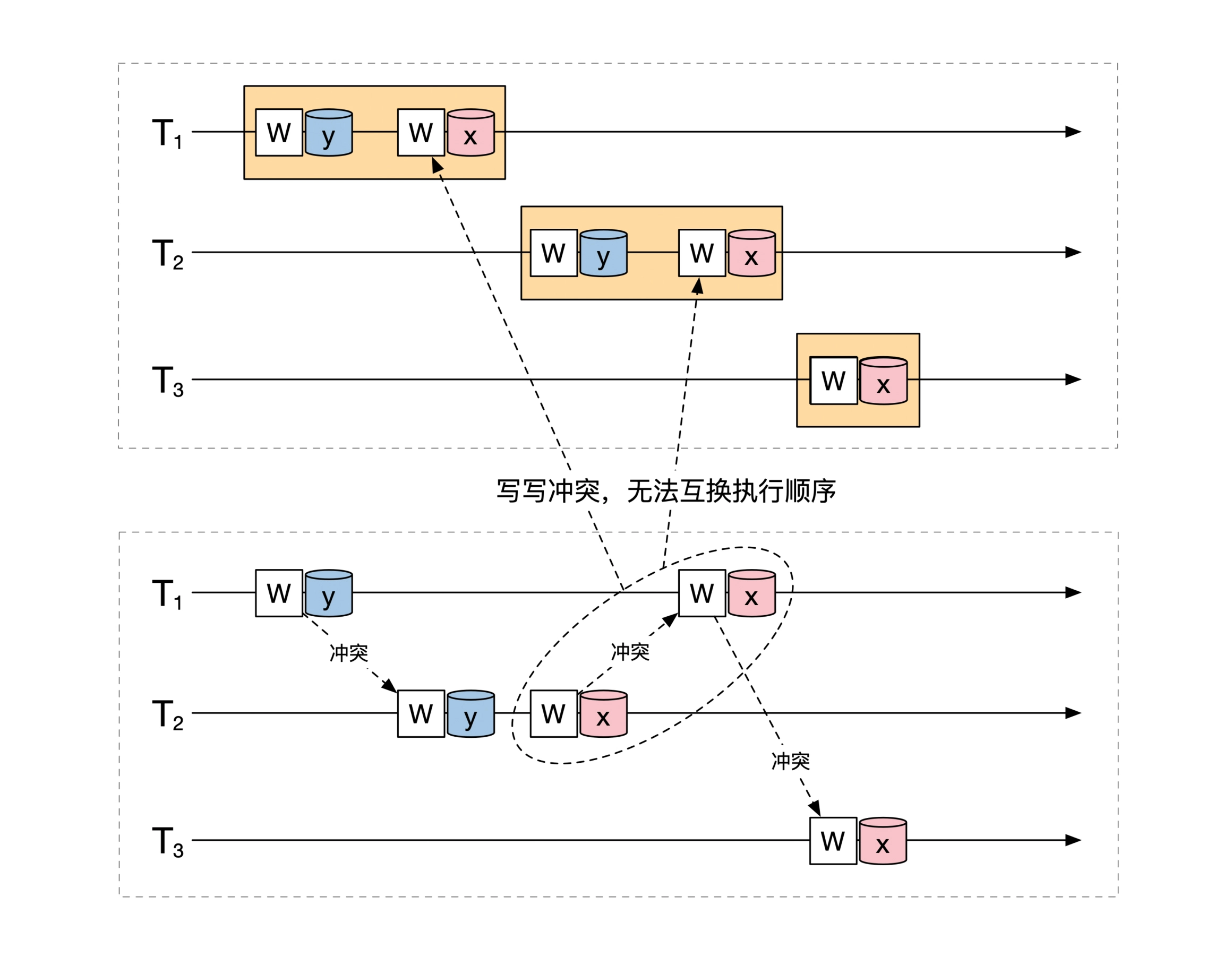
思考以下,如果用加锁的方式实现可串行化,实际得到的更严格的冲突可串行化。但是可串行化就足够了,没必要做到冲突可串行,冲突可串行会导致并发性能下降。
快照隔离MVCC:可串行化
MVCC机制保留了数据的多个版本,根据事务的开始时间,确定每个事务应该看到的数据版本。它是 通过修改数据操作的义,消除了大量了读写冲突,即要被操作的不是每个数据的最新版本,而是指定版本,如果两个并发动作分别操作同一数据的不同版本,定义为没有冲突,只有操作同一数据同一版本时(当前读场景),才用加锁的方式实现串行。
mvcc给每个数据引入了纵深,如下图所示,没有 mvcc 之前,dataA 只有一个value,op1/op2/op3 操作的是dataA 彼此构成冲突。引入 mvcc 之后,dataA 可有有三个 value,当 op1/op2/op3 分别操作的是 dataA 的三个版本时,彼此没有冲突。
data A (before mvcc) data A (after mvcc)
+--------+ +----+---------+
| valueA | | v3 | valueA3 | <----- op3
> +--------+ < +----+---------+
-/ ^ \- | v2 | valueA2 | <----- op2
-/ | \- +----+---------+
/ | \ | v1 | valueA1 | <----- op1
op1 op2 op3 +----+---------+
conflict no conflict
MVCC 是引入了一种新的数据操作定义,不止在可串行化用到,在其它隔离级别也有使用:
严格可串行化
另外还有一种 Strict Serializability,严格可串行化对事务的串行化的顺序也提出了要求, 必须和按照事务的提交顺序的串行执行结果一致(可串行化只要求和某个串行执行结果一致)。严格可串行化运行效率特别低,一般很少用到。
多机操作的正确性
多机数据操作的正确性构建在单机数据操作正确性之上,多机场景下产生了新的问题: 部分机器上操作成功,部分机器上操作失败, 由多台机器构成的数据整体只改写了一半,要怎么办?
参照单机的处理思路,可以想到的一种处理方法是:实现分布式原子操作,即分布式事务。分布式事务实现有多种方式,譬如下面的 2PC 和 TCC。无论用哪种方式实现,都会再次引入两个问题: 怎样处理乱序, 怎样处理并发冲突。
方案1:两阶段提交(2PC)
2PC,Two-Phase Commit,是一个解决多机数据操作正确性问题的方法(分布式协议),不同的系统可能有不同的实现方式,譬如分布式数据库和具体场景下的分布式业务,两阶段的具体操作可能是不同的。
2PC的核心思想是引入一个「协调者」,将多机数据操作分为「更改」和「提交」两步。第一步,协调者向目标机器发出数据操作请求,如果有一台机器失败或超时,事务失败。第二步,协调者收到所有机器的修改完成响应后,再次向所有机器发送提交指令,如果有一台机器提交失败或超时,事务失败。
借用 Two-Phase Commit (2PC) 的说明图:
第一阶段:发送更改指令,统计响应结果:
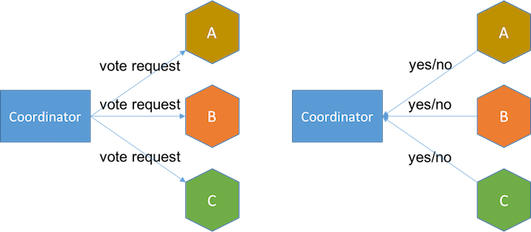
第二阶段:发送提交指令,统计响应结果:
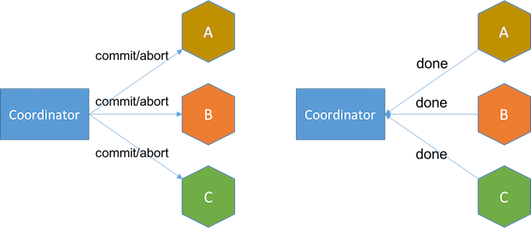
多机操作中使用两阶段提交协议实现事务时,事务中间状态的问题更加突出。需要多机操作并通过网络进行交互确认,事务中间态的持续时间被拉长,中间态时要怎样控制每台机器上的数据的可见性,以及协调者宕机时,处于中间态的事务要怎样处理,需要有明确的规则。
示例:使用2PC实现分布式转账
任杰在《分布式金融架构课》中给出了一个用 2pc 协议的分布式转账案例。
转出账户 x 位于数据库 A 中,转入账户 y 位于数据库 B 中,x 和 y 的账户数据分布在两台机器上。现在要从 x 转出 100 元到 y。
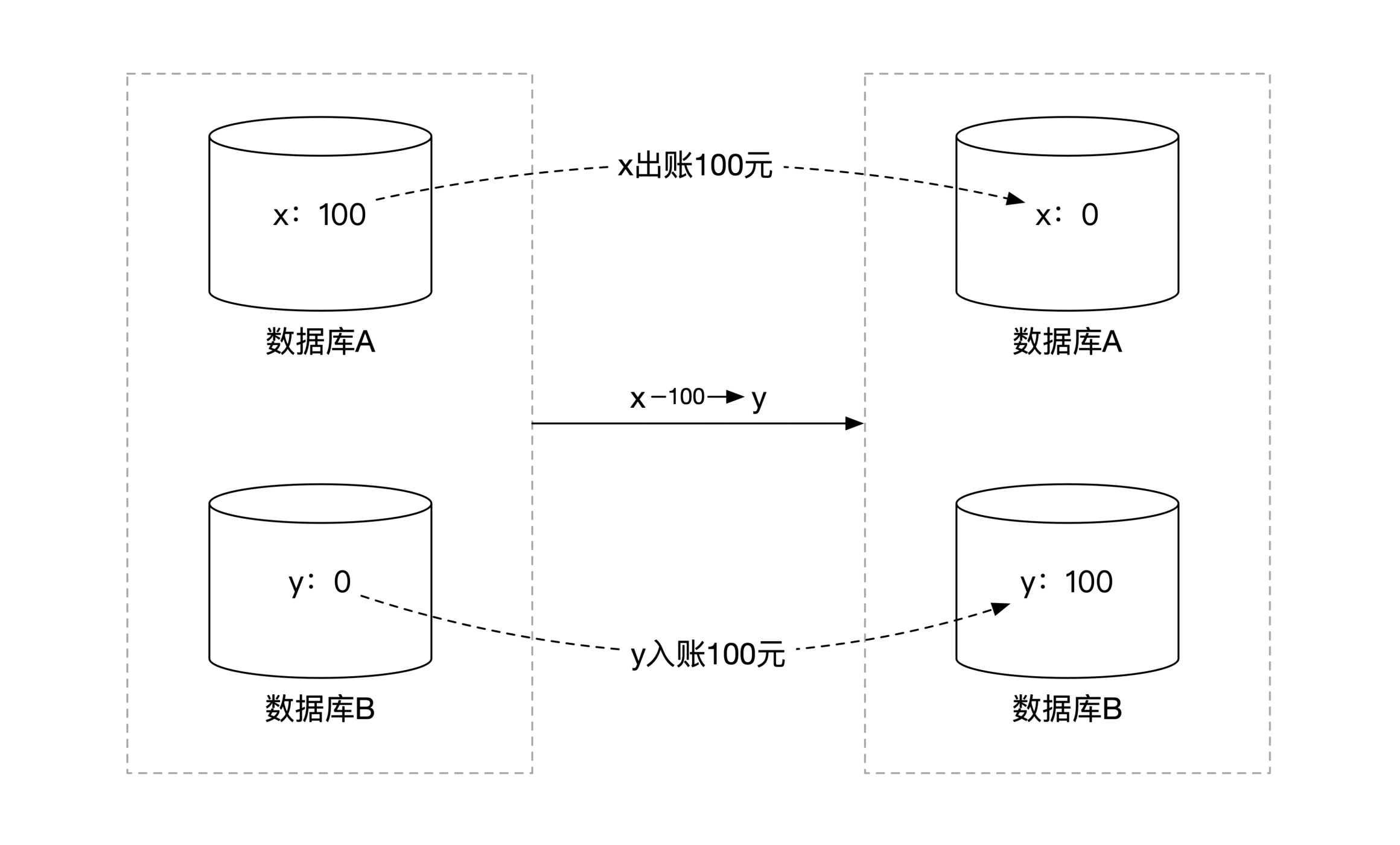
如果 x y 位于同一个数据库中,用下面的事务语句即可,假设只需要更新账户余额,x 账户初始余额 100 元,y 账户初始余额 0 元,转账就是 x 账户清零,y 账户增加 100:
begin transaction
update A set balance= 0 where accountID='x'
update B set balance=100 where accountID='y'
end transaction
现在,x 和 y 位于两台机器上的两个数据库中,不能用单机事务语句,两阶段的实现方法如下:
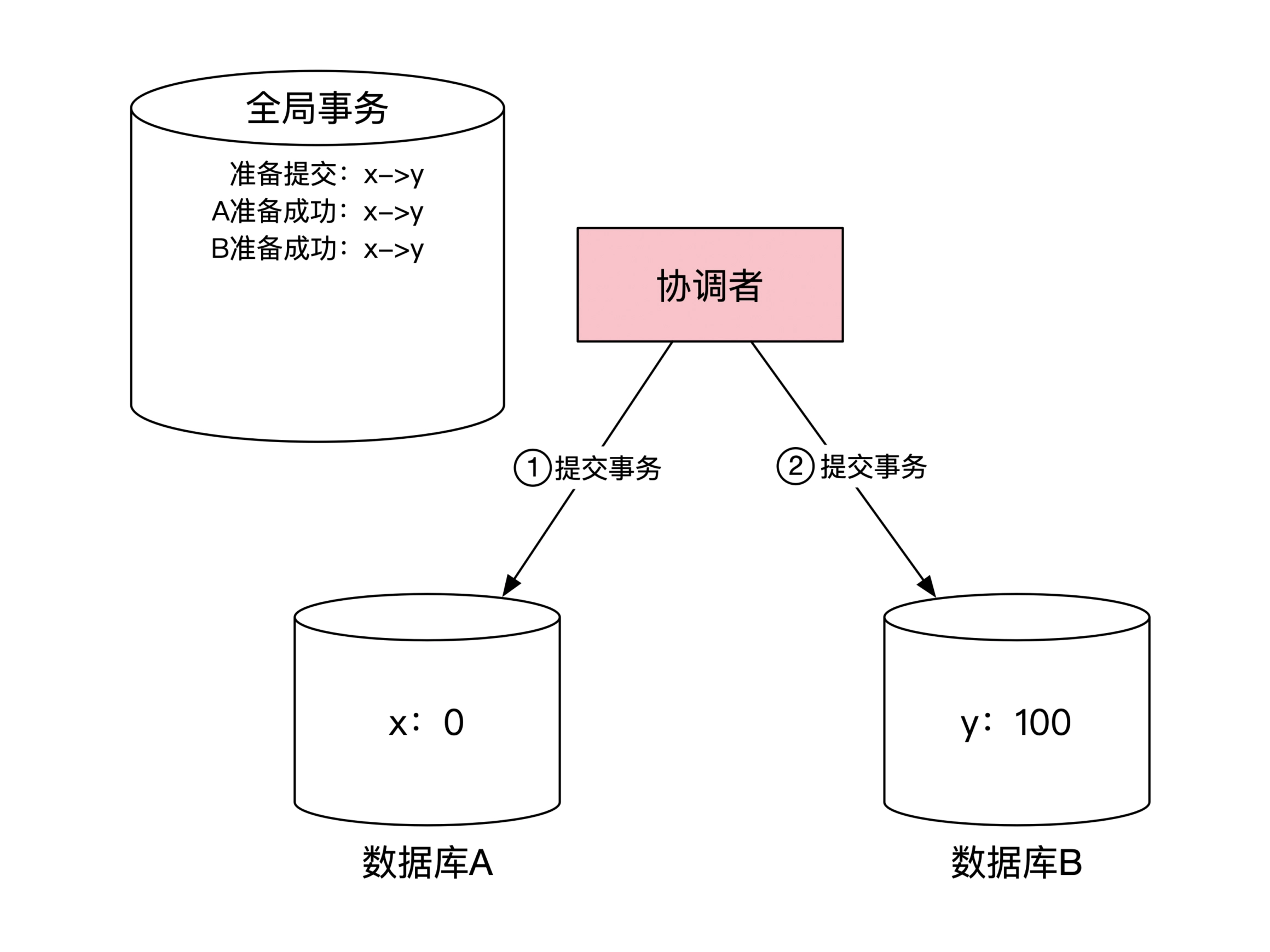
1. 协调者发送变更指令 :
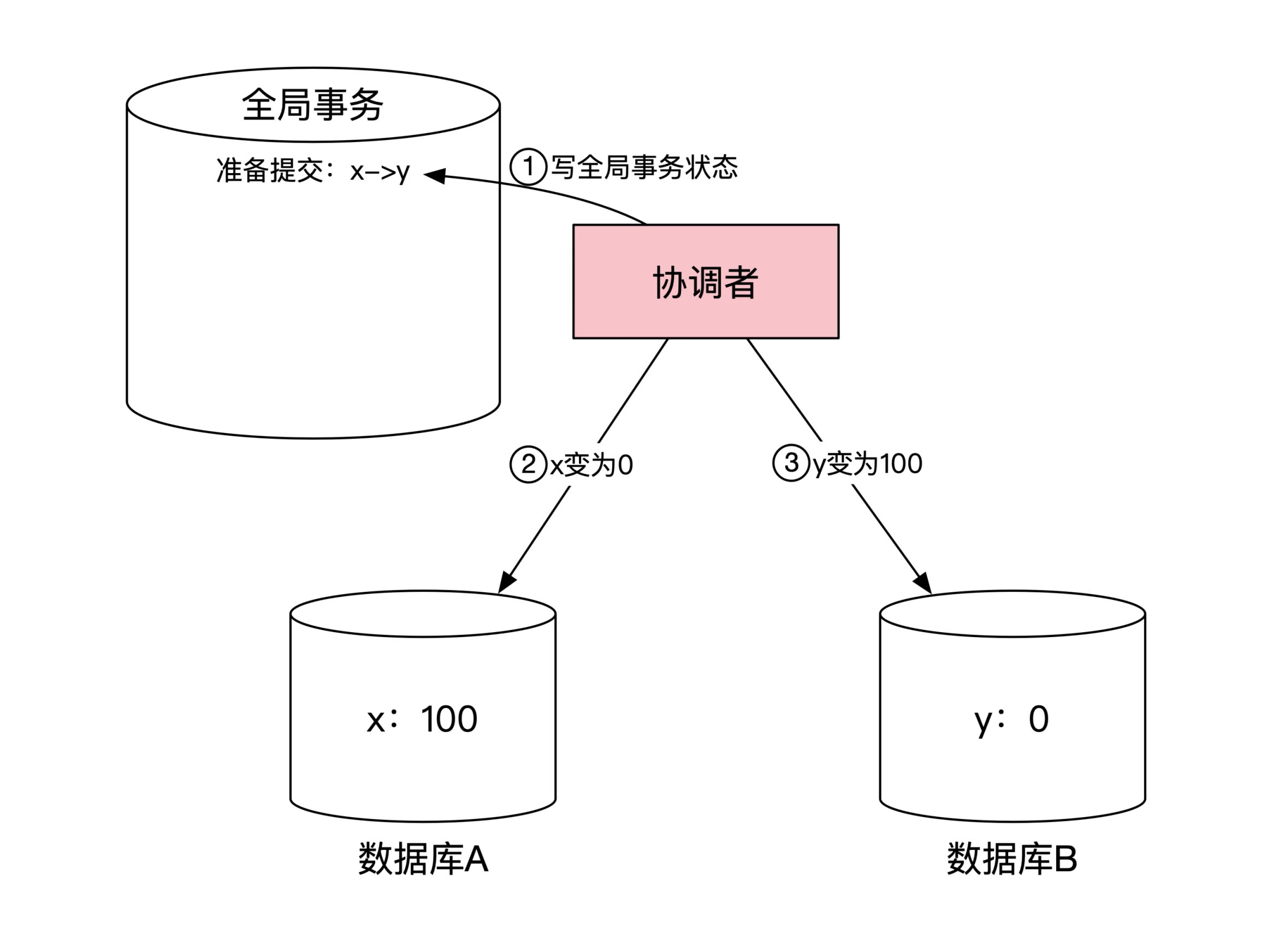
2. 协调者等待目标机器确认:
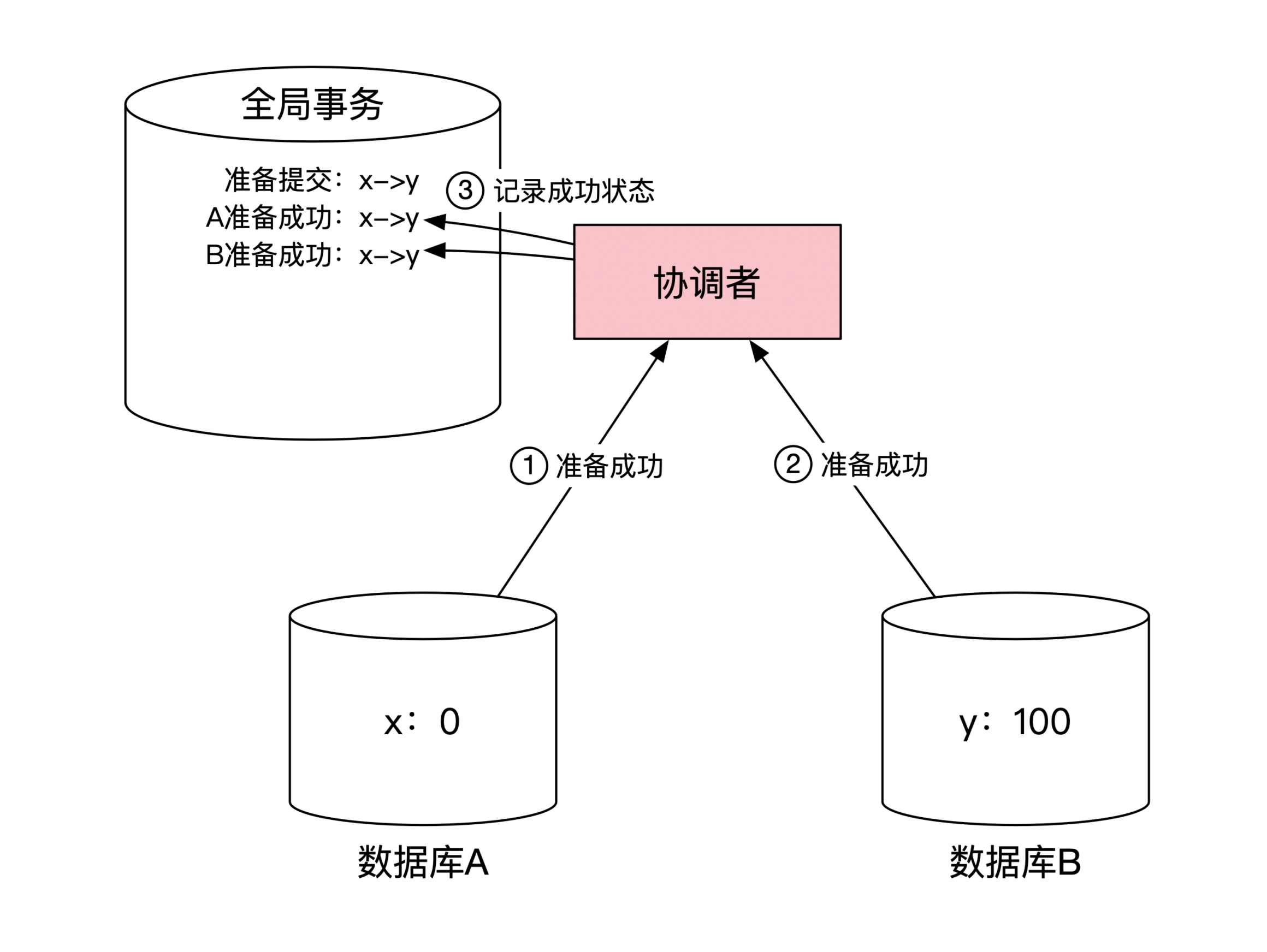
3. 协调者发送提交指令:
4. 协调者等待目标机器确认:
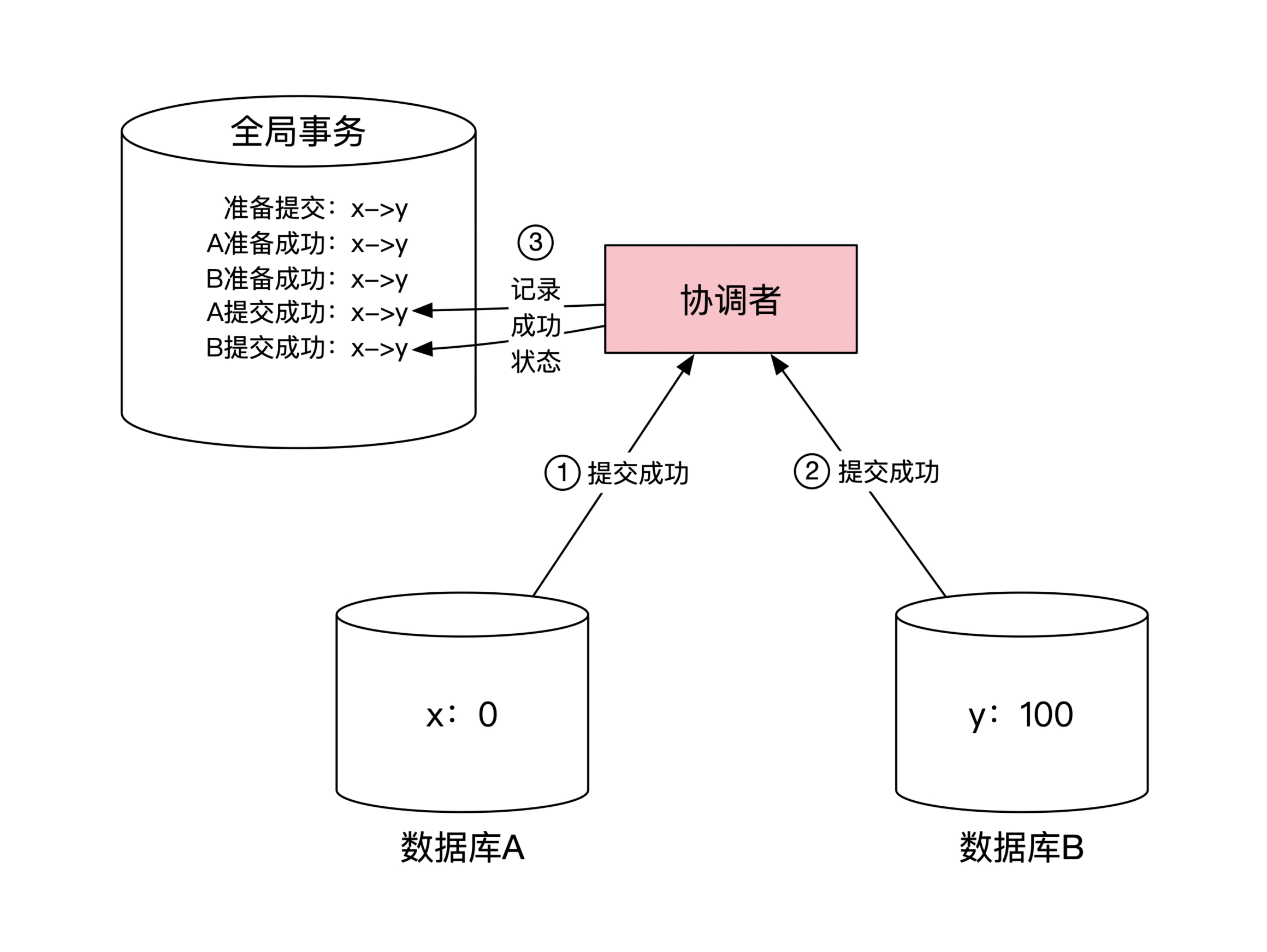
站在协调者角度,整个过程需要和每台机器进行两次网络往返通信。2PC 最大问题是性能,2pc 协议中,当时事务处于中间状态时,每个机器上对应的数据操作是阻塞的。
方案2:Try-Confirm-Cancel
TCC,Try-Confirm-Cancel,是另一个解决多机数据操作正确性问题的方法(分布式协议)。TCC 也是有一个协调者,然后分两阶段处理的。协调者先发送操作指令,等所有机器确认后,再发送提交指令。
和 2PC 不同的是,TCC 中目标机器只负责执行本地事务,感知不到分布式的全局事务,TCC 发送给目标机器的操作执行是执行完成一个本地事务,分布式事务执行失败时,TCC 向目标机发送的指令是再执行一个反向的本地事务。
2PC 实现的是一个更严格的分布式事务,目标机器需要参考全局事务的执行状态,确定本地数据是否可见,TCC 实现的分布式事务不那么严格,在全局事务的中间状态,目标机器上的本地数据是可见的。
2PC 适用于要对外提供事务功能的分布式系统,譬如分布式数据库,用户只需要开启事务、执行语句、提交事务,不需要关心事务的回滚过程。
TCC 适用于业务系统开发,用户要定义两组操作:1. 正向的数据变更动作;2. 负向的数据变更动作。
示例:用 TCC 实现的分布式转账
《分布式金融架构课》中的例子,使用 TCC 协议实现分布式转账时,定义的两个阶段的两组操作如下。
目标机器 A 和 B 上的正向操作:
-
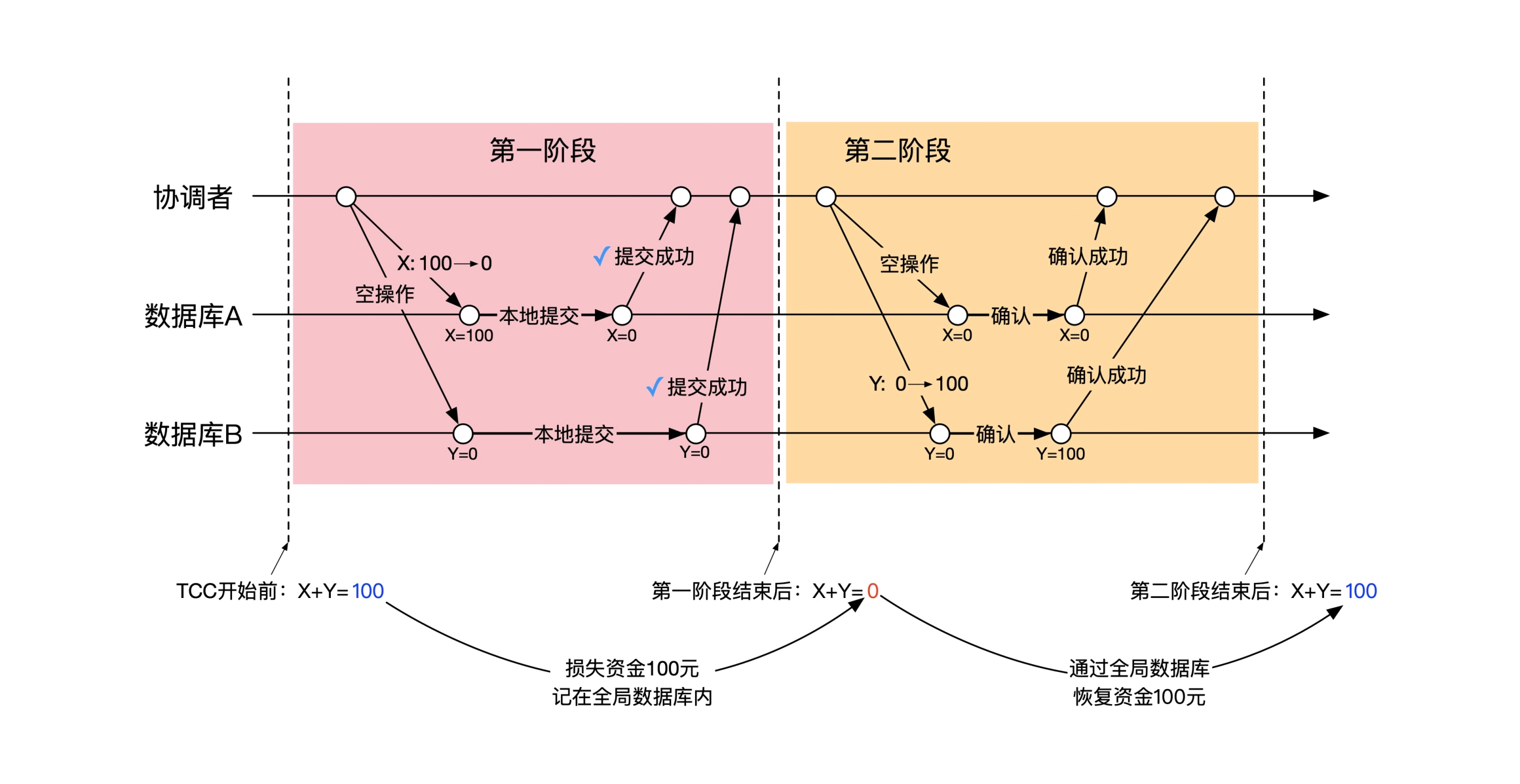
第一阶段:A 机器完成 x 账户 -100 的本地事务,B 机器执行空事务(什么也不做),x 和 y 账户余额都为 0
-
第二阶段:A 机器执行空事务(什么也不做),B 机器完成 y 账户 +100 的本地事务,x 和 y 账户余额回归正确值
目标机器 A 和 B 上的反向操作:
-
第一阶段的撤销:第一阶段失败,只能是 A 机器的本地事务执行失败。A 机器上的数据未变化,B机器上无操作,撤销操作为取消 B 机器的空事务。A 和 B 机器上的数据都没有变化,撤销时不需要执行数据修改操作。
-
第二阶段的撤销:第二阶段失败,只能是 B 机器的本地事务执行失败。A 机器上的数据在第一阶段被修改,B 机器数据一直未发生变化,撤销时需要给 A 机器发送一个执行反向操作的指令。只在 A 机器上修复数据。
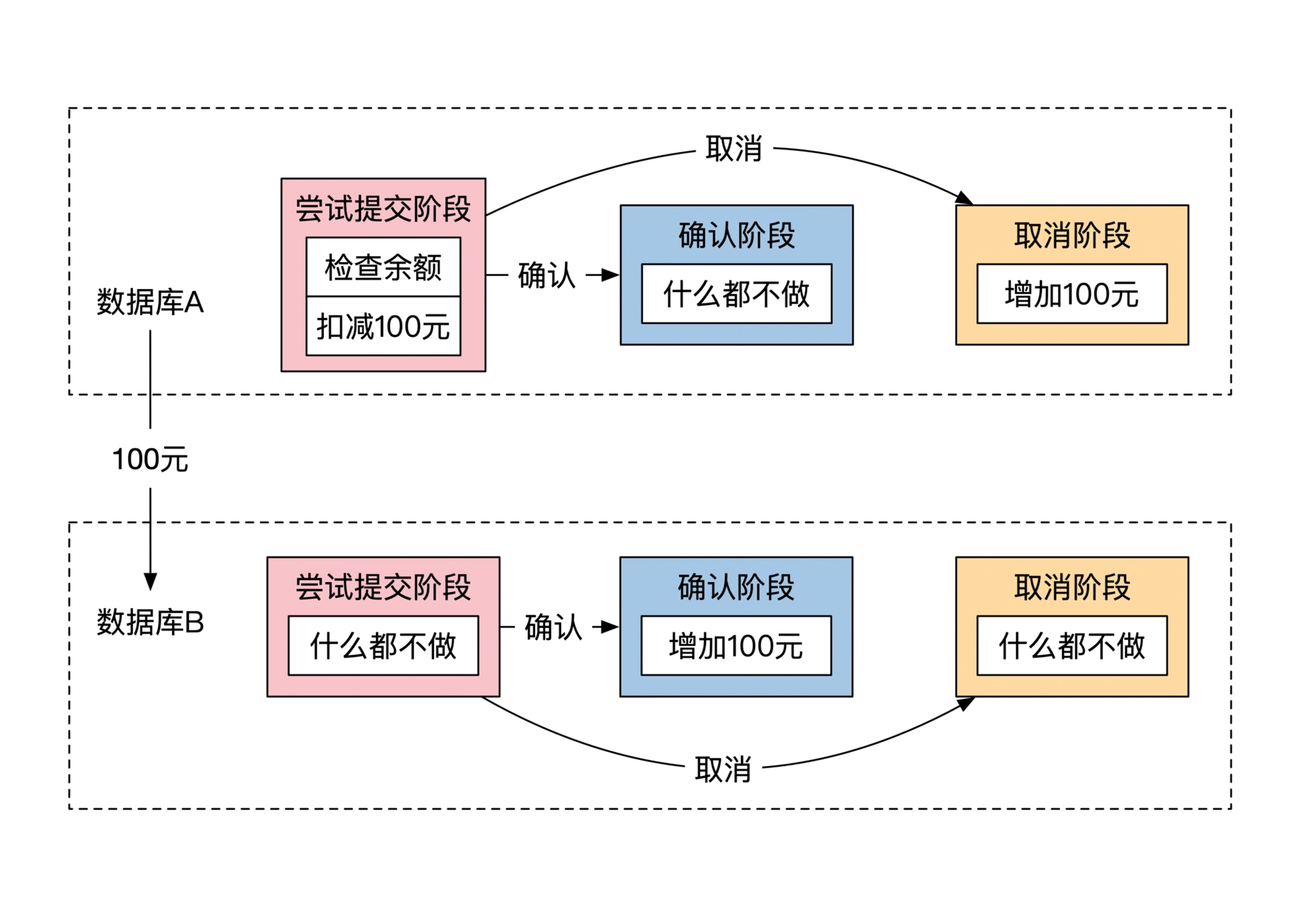
在转账这个案例中,每个阶段只对一个机器进行实质操作,并且先操作被扣款的帐户所在的机器。这种设计巧妙之处是,当全局事务处于中间状态时,x 的余额为 0,y 的余额也为 0,这种中间状态数据可见时,处理系统中的总金额减少了 100,不会导致其它不可接受的错误。
举个反例,如果先对 y 账户 +100,在对 x 账户 -100,全局事务的中间状态为 x 账户余额 100,y 账户余额 100。这个状态对外可见,意味着在另外一个并发执行的事务中, x 账户还有余额可以花费,y 账户也有余额可以花费,另外一个事务不仅可以对 x 继续划账,还可以对 y 继续划账。如果 x 到 y 的最终转账没成功,或者另一个事务先把 x 上的余额扣的不足了,需要连串的撤销已经提交成功的事务。如果先扣减 x 账户,中间状态时,第二个并发事务不可能成功或不会产生不可容忍的错误。
多机操作的乱序和并发问题
无论是 2PC 段和还是 TCC,对每台机器都需要进行两步操作,并且操作指令是通过网络传输。只要通过网络传输就会存在乱序问题。
譬如在一个分布式事务中, B 机器没有收到第一阶段的变更指令,协调者认定超时后,发出了取消事务的指令,B 机器先收到取消指令,然后才收到了最初的变更指令。
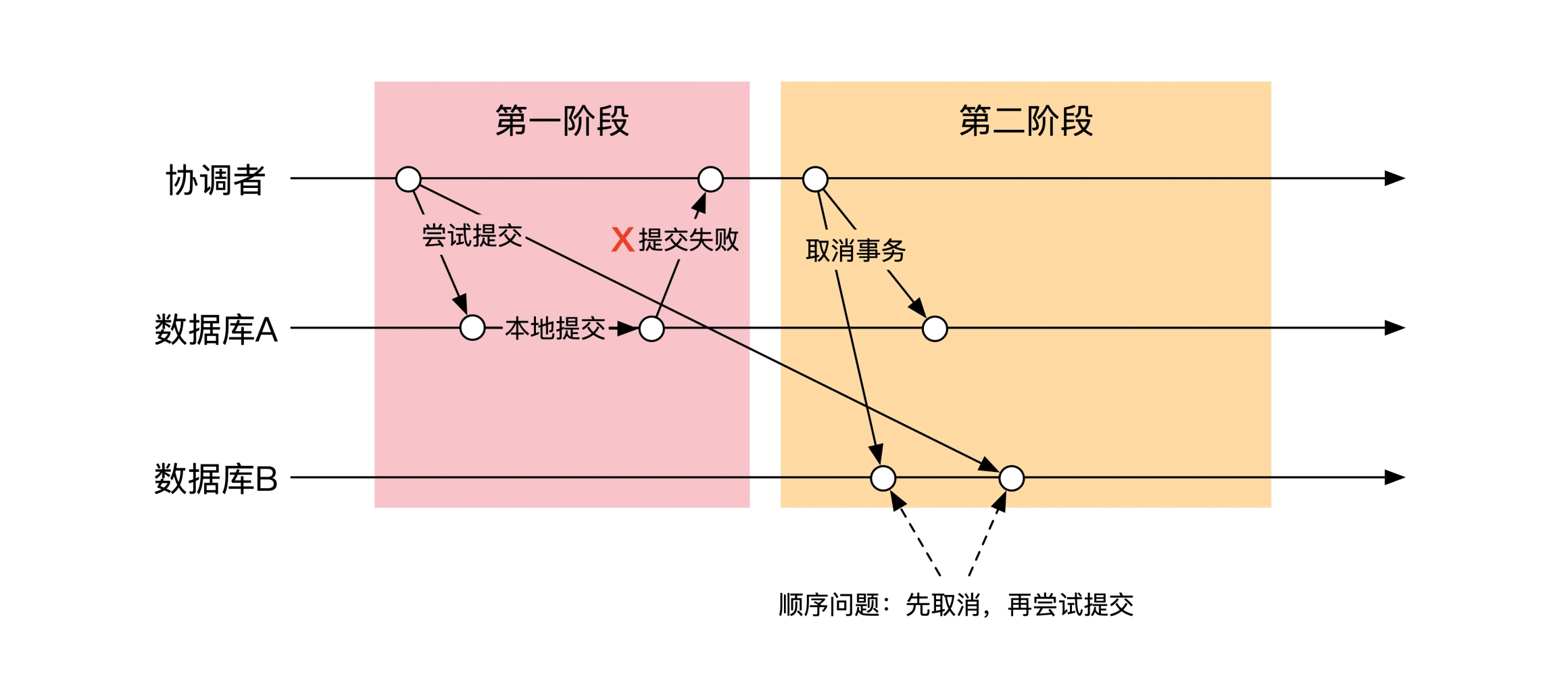
除此之外,多机数据操作同样存在并发问题。
示例:TCC 实现分布式转账的乱序和并发
前面实现的 TCC 分布式转账对乱序问题的解决方法:让每台机器意识到乱序发生了,并采取行动。
譬如对 B 机器而言,当它先收到一个取消指令时,能够通过检索本地记录发现这个取消指令没有对应的变更指令,是一个后发先到的乱序指令。B 机器这时候进行「空回滚」,并且记录下这个空回滚指令。等先发后到的变更指令到达时,B 机器再次检索本地记录,发现这个指令有对应到空回滚操作,拒绝处理变更(这个动作叫做防悬挂)。
TCC 对并发的解决方法是:仔细规划两阶段里操作,保证在事务的中间态时,另一个事务的能够执行。
能够执行是指,在事务 A 处于中间态的时候执行事务 B,不会出现不能容忍的错误。
多机数据备份的一致性
「一致性」这个词至少有两个使用场合:
-
数据库ACID模型中的一致性:读取的数据要么是新数据,要么是旧数据,不能是两者的混杂,ACID。
-
数据多副本冗灾中的一致性:主节点和副本的各种读写组合的结果的约定。
这里要研究的是数据多副本时的一致性问题。
首先要分辨下概念,「多机数据操作」和「多机数据备份」是完全不同的问题。
-
多机数据操作:一份数据被拆分成多块分布在多台机器上时,要如何操作才能保证数据的正确性。
-
多级数据备份:同一份数据延迟复制到了多台机器上,随机读取主副本机器,读取的是新数据还是旧数据。
多机数据备份还需要考虑同机房/跨机房、同城/异地等实施场景。
CAP 理论框架
CAP 是一个经过数学证明的结论:集群发生网络故障,脑裂成为无连接的两个集群后,要么所有集群不可用(Availability不满足),要么集群可用但是数据不保证一致(Consistency)。
CAP 给出的指导意见是:当脑裂发生后,需要做的是选择怎样的牺牲方式,是牺牲可用性,还是牺牲一致性。
需要注意的是,任杰在专栏中指出: CAP 对一致性的定义太过简单,学术界已经不太建议用这个术语。
分布式环境下多副本数据的一致性有几十种分类,CAP 使用的一致性定义是「可线性化(Linearizability)」,区分度不够,并不是所有场景下都需要「可线性化」的一致性。
下面介绍几种不同场景下的一致性:
1. 最终一致性
2. 单会话场景:
2-1: 单调写一致
2-3: 单调读一致
2-3:单调读一致
3. 多会话场景:
3-1:先读后写
3-1:线性一致
理论中的最终一致性
最终一致性,对主节点的数据修改操作,最终会在副本机器上可见。最终一致性没有给出「最终」的时间范围,在工程上上的指导意义不大。
单会话中一致性
多机备份中,同一个用户的请求可能会被分发到不同的副本机器上,数据变更扩散到副本机器上需要时间。
需要定义一次「会话/Seesion」中读写一致性标准。
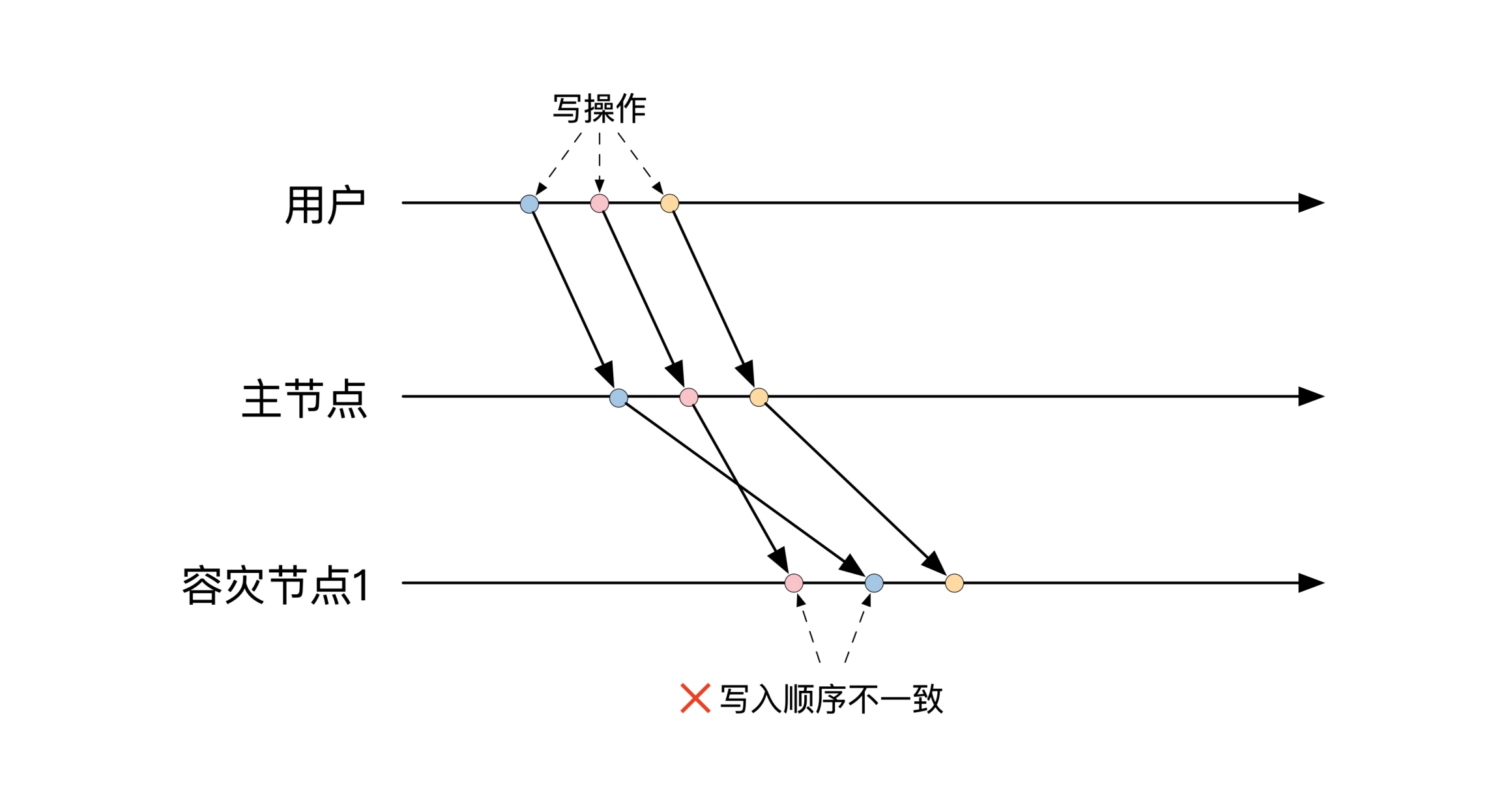
单会话:单调写一致
Monotonic Write,一次会话中,备份节点的数据写入顺序,和用户在主节点上的发起的写入顺序相同。
下图是不符合单调写一致性的场景,副本机器上的写入顺序和主节点不同:
单会话:单调读一致
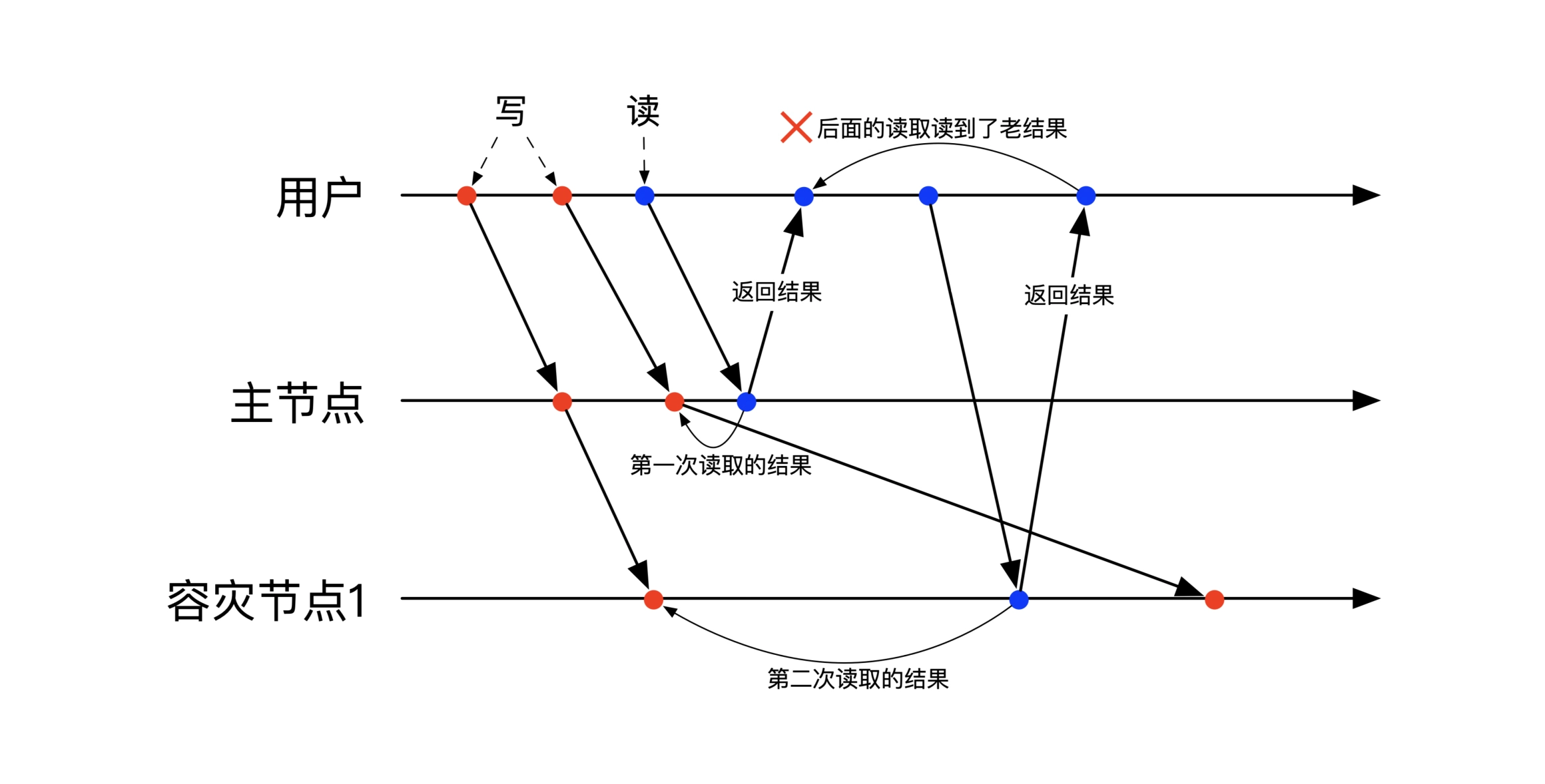
Monotonic Read,一次会话中,后面的读操作获取的数据,一定不比之前的读操作获取的数据老。
即单会话中,读出一份数据后,后面的再进行重复读,只能读到更新的版本,不能读到更老的版本。
下图是违背单调读一致的场景,副本的更新有延迟,用户第一次从主节点读取到更新后的数据,第二次从副本读取时,副本你还没有收到完成更新,用户读到了老版本的数据:
单会话:自读自写
Read Your Write,一次会话中,连续写读,读取时返回多个版本的数据,分别对应每次的写入结果。
即读取出来的不是一份数据,而是一份数据的多个版本,这样设计的目的是让用户能自行判断出数据的新旧。
下图是违背自读自写的场景,用户从副本读取时,副本还没收到第二次更新,用户读不到之前的所有版本:
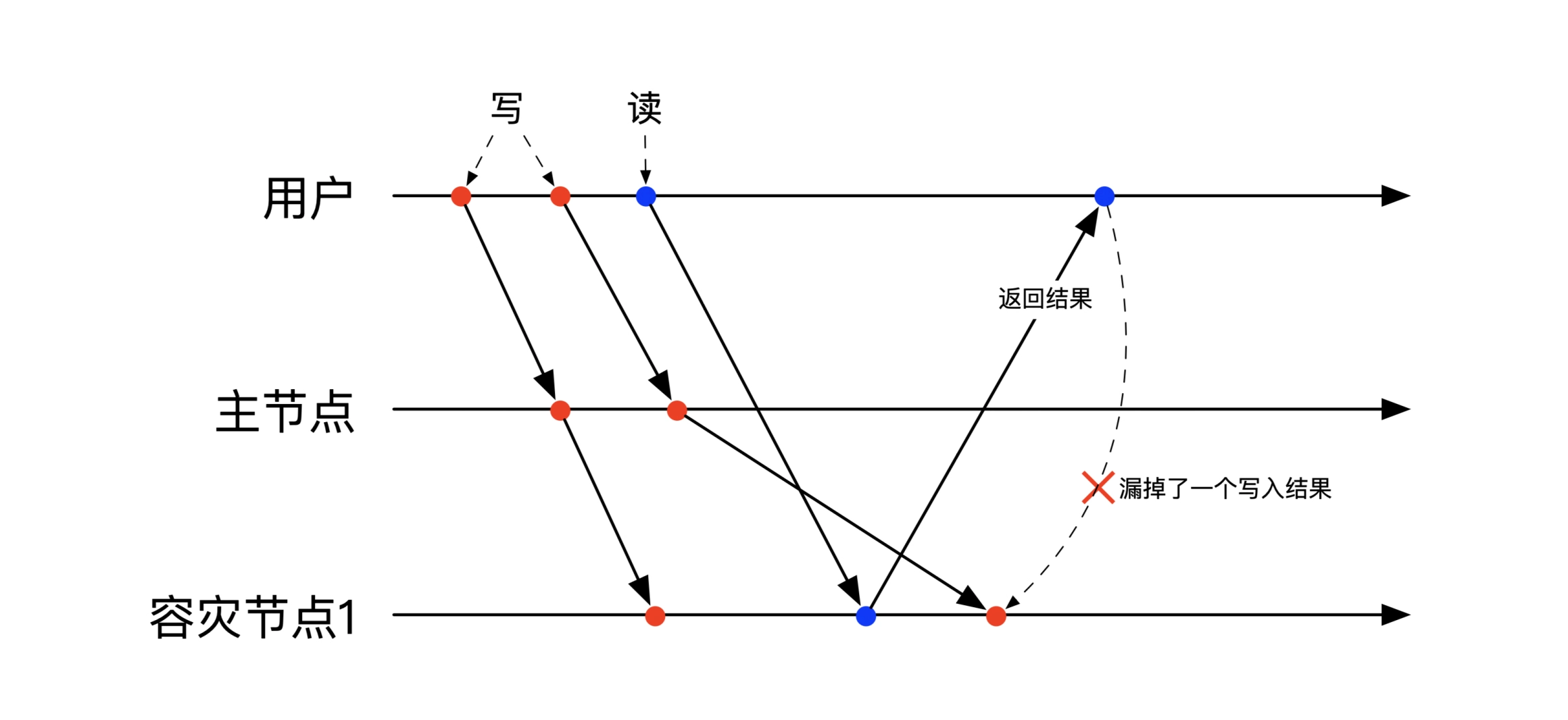
多会话的一致性
多会话一致性,对同一份数据进行并发读写时的结果进行约定。
多会话:先读后写
Write follow Reads,当前会话读取到前一个会话的修改结果,当前会话的写操作必定会在前一个会话的写操作之后.
主要是约定副本机器上的写入顺序,无论在哪台机器上,当前会话的写操作都要排在上一个会话之后。
下图是违背先读后写的场景,用户2的更新比用户1的先到达了副本机器,副本机器先执行用户2的更新违背了先读后写:
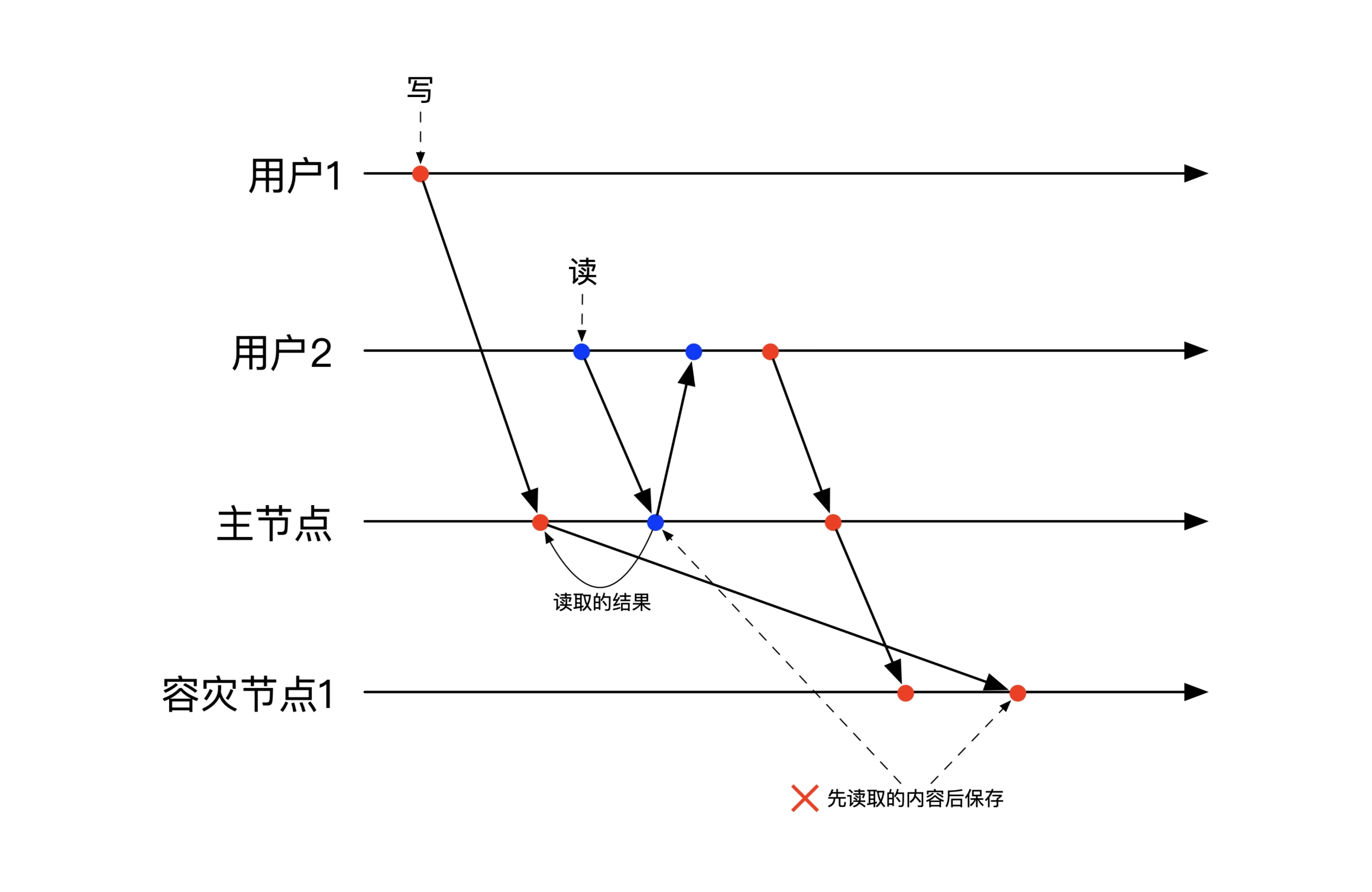
多会话:线性一致性
Linearizability,线性一致性和事务中的可串行化/Serializability 类似,在时间上有重叠的并发操作,能够被转换成无并发的顺序操作。即并发操作的结果,和按特定顺序串行操作的结果等价。
线性一致性存储
分布式共识算法
这部分主要讲了一个证明: 在一个完全异步的分布式系统里,如果至少有一台机器可能会出问题,那么就不存在非随机的共识算法。Paxos 和 Raft 通过给每台机器增加一个时钟来判断发送的消息是否丢失,去除完全异步的限制,从而实现分布式共识。
详细证明过程这里不摘录,相关论文:
- 1985,Fisher,Lynch,Patterson, Impossibility of Distributed Consensus with One Faulty Process, 证明完全异步下,机器可能故障情形下,分布式共识不可能,被称为 FLP结论,对分布式系统而言具有划时代的意义
- 1996,Unreliable failure detectors for reliable distributed systems, 证明如果存在能作出准确判断的不准确时钟,系统存在共识算法
- 1996,The weakest failure detector for solving consensus, 证明不准确时钟是共识算法的充要条件
共识的定义
共识需要满足 3 个条件:
- 终止性(termination),所有还能正常的运行的机器都需要确定一个唯一结论,并且不再更改
- 一致性(agreement),所要正常机器得出的结论是相同的
- 有效性(validity),得出的结论是有效解内的
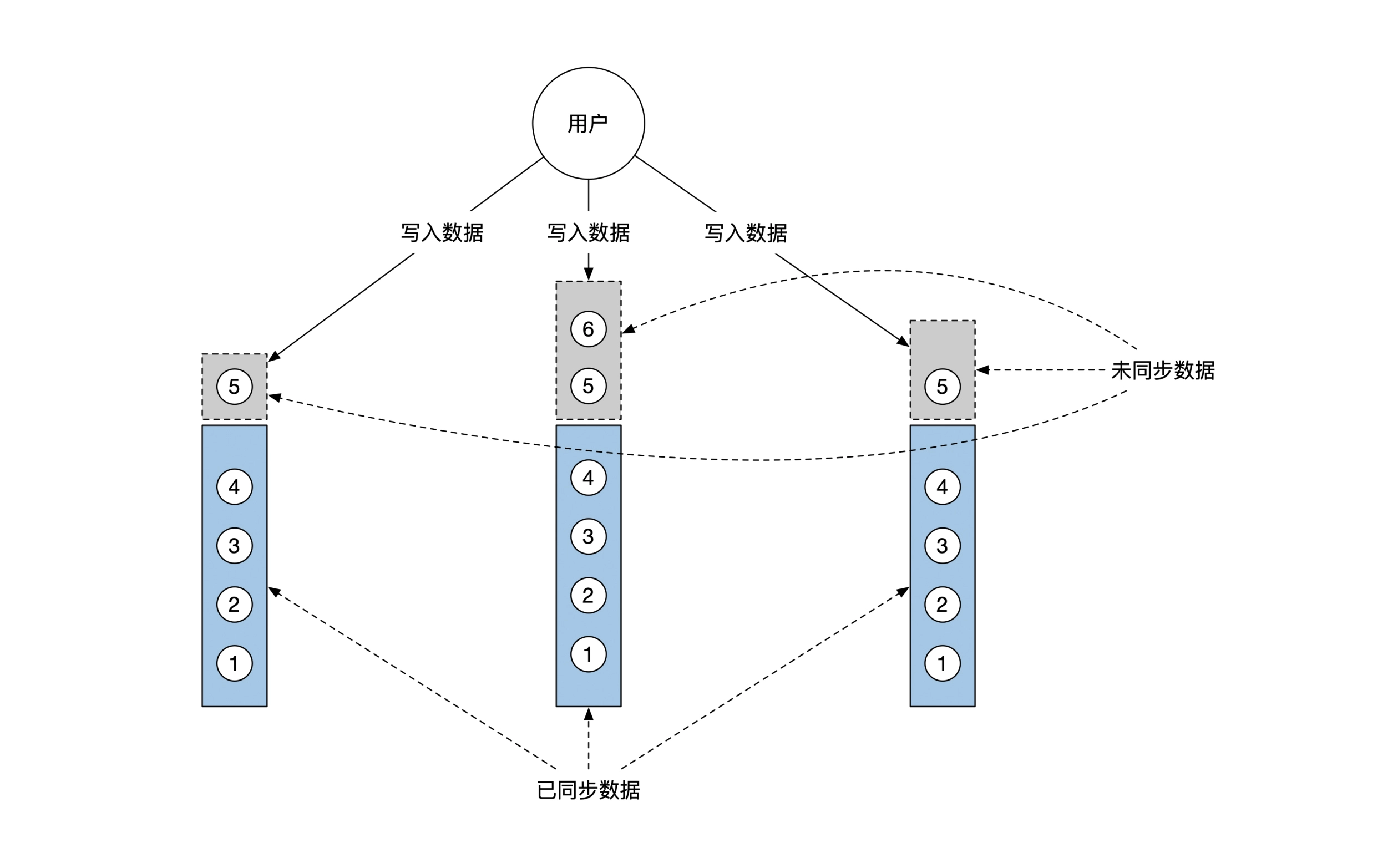
共识算法,可以让多台机器各自维护一个内容彼此同步的文件,通常被用来同步非常重要的但是数据量比较少的文件。
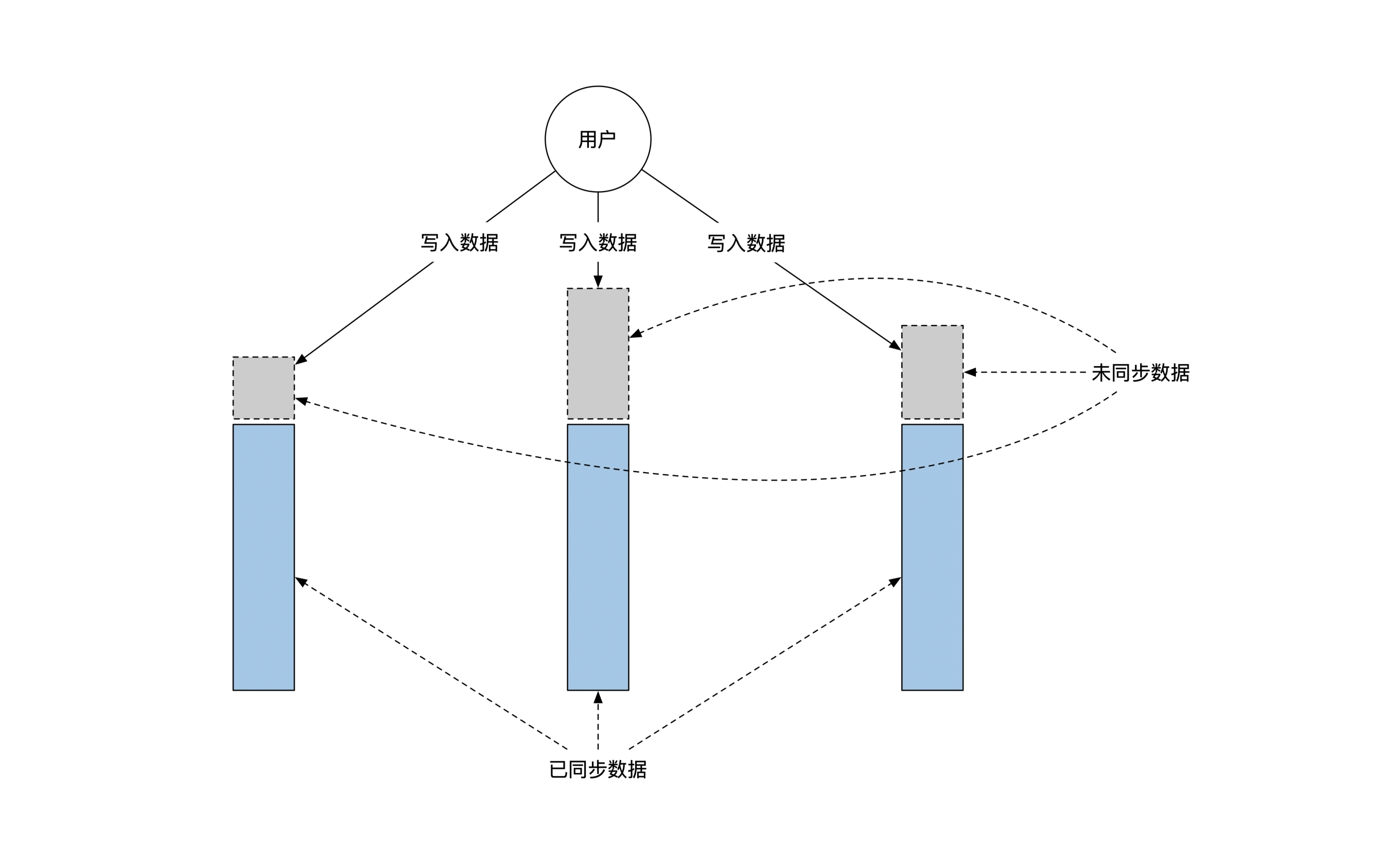
在需要达成共识的场景中,共识算法实际提供的是实现「全序广播」或「线性化存储」的能力。
全序广播和线性化存储是等价的,能实现一个,就能实现另一个。
全序广播
线性化存储
线性化存储即满足了「可线性化」的存储, 可以用来于实现分布式锁。
用户在一台机器获得锁以后,可线性化存储保证在其它机器上也获得了这把锁。
Raft 算法核心概念
通过 Raft 算法实现全序广播:多台机器之间通过 raft 算法达成选举共识,选出一个公认的主节点,所有的请求都由主节点处理,主节点完成操作后同步给其它节点,raft 主节点完成向其它节点的全序广播后,才向客户端返回成功。
Raft 主节点通过广播带有任期(term)编号的心跳信息,压制其它节点保持在从节点状态。从节点如果长期收不到主节点的心跳信息,切换为候选节点,参与选主。
使用 raft 时需要实现的行为:
- 主节点发生切换后,客户端请求到原主节点时,需要能够根据原主节点返回的信息,切换到访问新主节点
- 主节点向客户端返回失败时,客户端通过「重试」的方式,再次请求
- 主节点响应超时时,请求状态为不确定,可能成功,可能失败,需要能够对客户端重发的请求去重或幂等
Raft 算法的正确性与
由于 Raft 算法涉及到无限种可能的情况,因此无法通过形式语言来证明正确性。
混沌工程
系统的正确性是一个概率问题,正确性其实是系统不会出大问题这个结论的置信区间。
混沌工程通过一边调整因变量(SLI)、一边检测服务质量目标(SLO),来确定系统的可靠性。
Jepsen 测试,用来证明分布式系统正确性的工具:jepsen.io。
后续
《分布式金融架构课》阅读笔记2:线性一致的分布式数据系统的实现过程
书单抄录
领域驱动设计:
- 《Domain-Driven Design: Tackling Complexity in the Heart of Software》,Eric Evans,2000
- 《Patterns, Principles, and Practices of Domain-Driven Design》,Scott Millett
数据系统:
- 《Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems》,Martin Kleppmann,中文版本《数据密集型应用系统设计》,建议阅读章节后的论文列表
- 《Database Internals: A Deep Dive into How Distributed Data Systems Work》,Alex Petrov,单机部分介绍更好,分布式方面比较凌乱
- 《Database Systems: The Complete Book》,Hector Garcia-Molina,介绍数据库系统架构
计算机:
- 《Computer Systems: A Programmers Perspective》,Randal Bryant
- 《Modern Operating Systems》,Andrew Tanenbaum
性能调优:
- 《Systems Performance》,Brendan Gregg
经济学:
- 《经济学原理》,曼昆
- 《经济学》,保罗·萨缪尔森
- 《Intermediate Microeconomics: A Modern Approach》,Hal Varian
- 《通往奴役之路》,哈耶克
- 《Economics of Money, Banking and Financial Markets》,Mishkin
- CFA、FRM 考试资料
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文