《分布式金融架构课》阅读笔记2: 线性一致的分布式数据系统的实现过程
目录
说明
以下内容摘录自仁杰的技术专栏《分布式金融架构》,这是第二篇笔记,背景和基础知识见第一篇笔记:《分布式金融架构课》阅读笔记:单机并发/多机并发/多副本读写的正确行和一致性。
这里推演线性一致的分布式数据系统的实现,以分布式数据库为例。
什么是分布式数据系统
由多台机器组成的、提供数据存储/访问功能的系统,都算分布式数据系统,譬如以下系统:
- 由一主一从组成的 mysql 数据库集群
- 由一主多从组成的 redis 缓存集群
- 由多台机器组成的 kafka 消息队列
- 由多台机器组成的分布式存储、分布式数据库
分布式数据系统的正确性
无论是部分机器故障还是并发操作,都需要保证所有机器上的数据正确。
要保证数据正确,分布式系统需要实现「分布式事务」,见 多机操作的正确性保证。
分布式数据系统的读写一致性
分布式系统中的数据存在多个备份,需要对数据的并发读写做出一致性承诺。
一致性分为很多种,见 多机数据备份的一致性。
分布式数据库实现
分布式数据库是对正确性和一致性要求最高的分布式数据系统:
- 需要实现数据容灾
- 数据读写要满足线性一致性
- 需要支持分布式事务
分布式数据库:容灾与读写的线性一致性
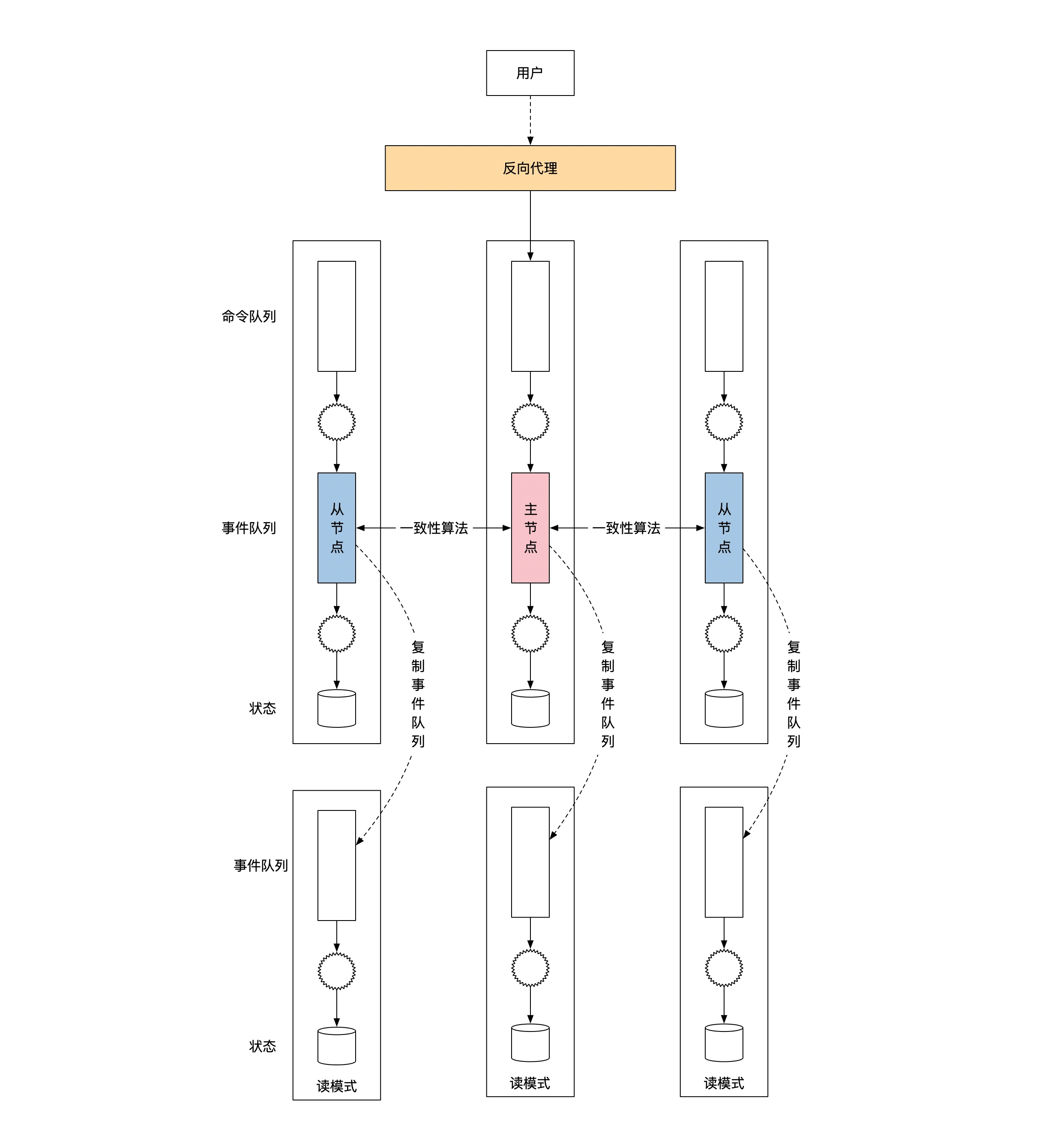
用「事件溯源架构」+「分布式算法」实现数据读写的线性一致性:
- 多台机器通过 raft 算法,达成共识选出唯一主节点
- 主节点将事件队列全序广播到从节点(复制状态机),实现事件队列的线性化存储
- 线性一致性读取:查询请求发送到主节点,与写操作一起排序,主节点将查询结果返回
- 非线性一致性读:查询请求发送读节点(读写分离架构),读节点通过读模式状态机,计算出查询结果
如果要线性一致性读,查询请求要发送到主节点,下图未体现
分布式数据库:分布式事务
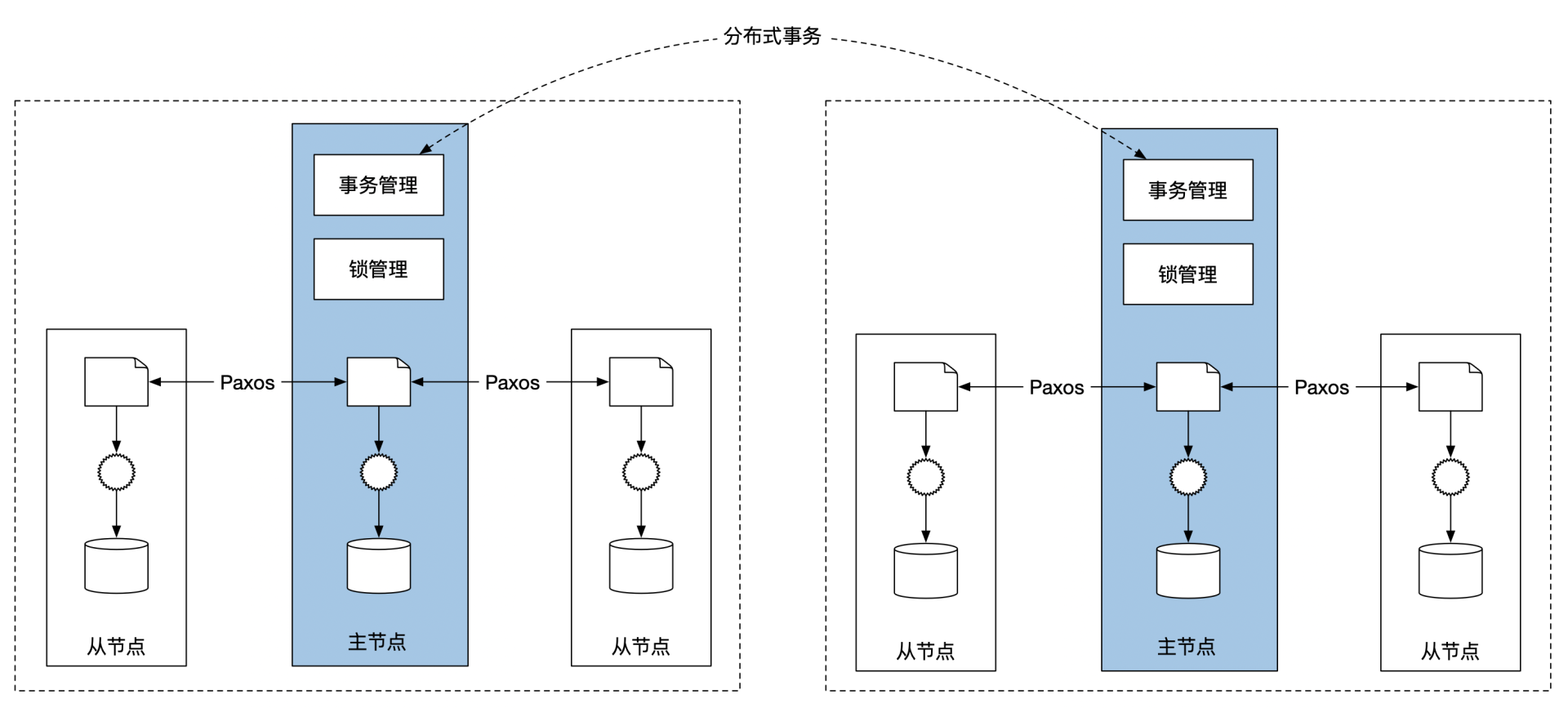
分布式事务有 2pc 和 tcc 两种实现方式,详情见:多机操作的正确性。
无论是 2pc 还是 tcc 会引入新的角色——协调者,协调者本身不能是单点,也需要用多台机器实现容灾,又带来同样的「读写一致性」问题。
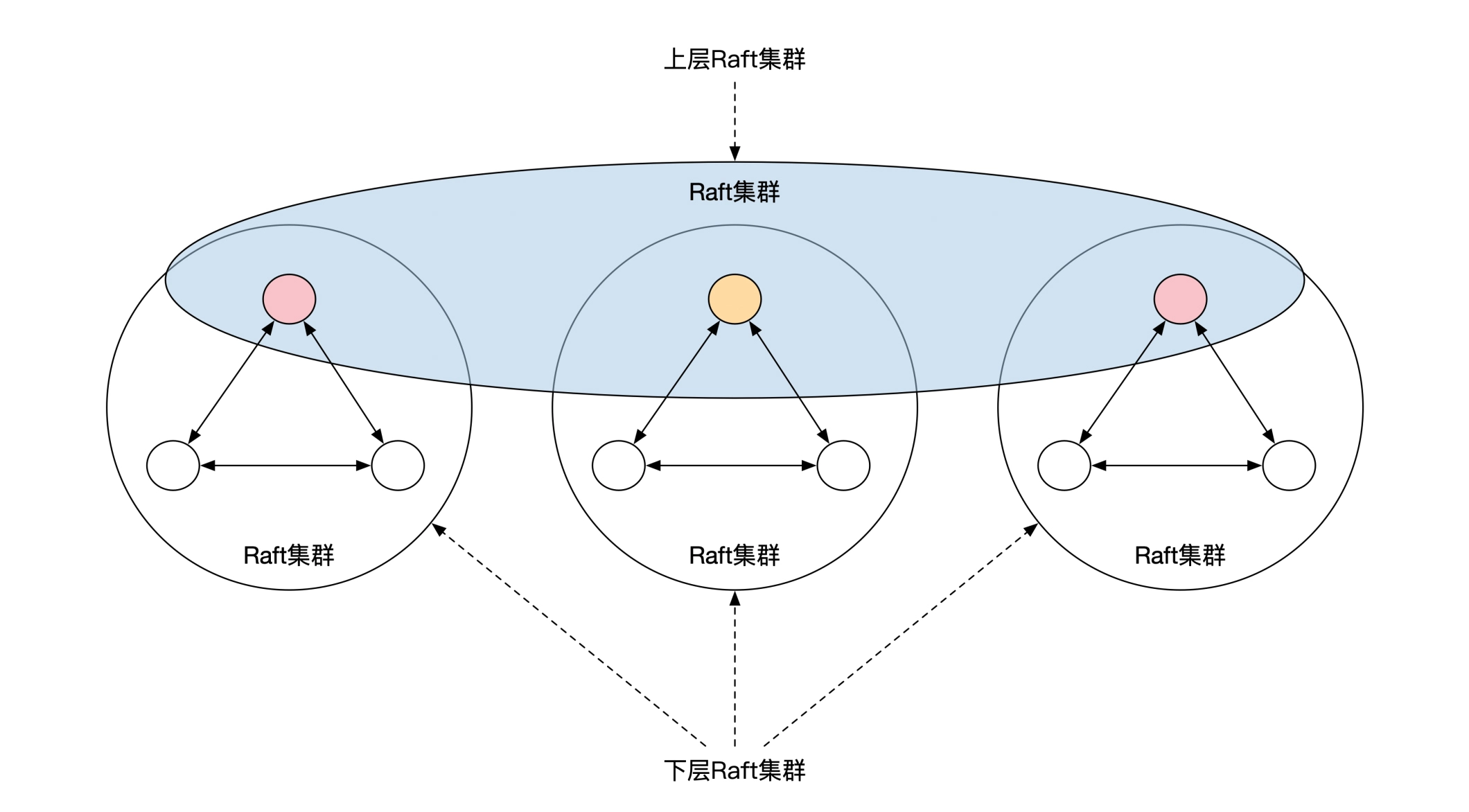
继续用「事件溯源架构+分布式算法」实现协调者的读写操作的线性一致性,最终架构如下:
+----------------+ +----------------+
| | raft | |
| Master |---------|> | Salves | <-- 协调者集群
| | | |
+----------------+ +----------------+
. |
/_\ | 正确性(分布式事务)
| _|_
| \ /
| '
********************************
+-------+ +-------------------+ +------------------+
| | | | raft | |
| User | +--|> | Data Master 1 | -------|> | Data Salves | <--- 数据集群
| | | | | | |
+-------+ | +-------------------+ +------------------+
| +--------+ |
| | | | +-------------------+ +------------------+
+-|>| router |--+ | | raft | |
| | | | Data Master 2 | -------|> | Data Salves | <--- 数据集群
+--------+ +---|> | | | |
+-------------------+ +------------------+
Spanner 的实现
数据备份:Spanner 通过 Paxos 算法将日志文件同步到多台机器,每台机器通过日志文件实时同步状态。
分布式事务:共识算法的主节点承担分布式锁的实现、承担事务协调者的职责。
spanner 简化架构:
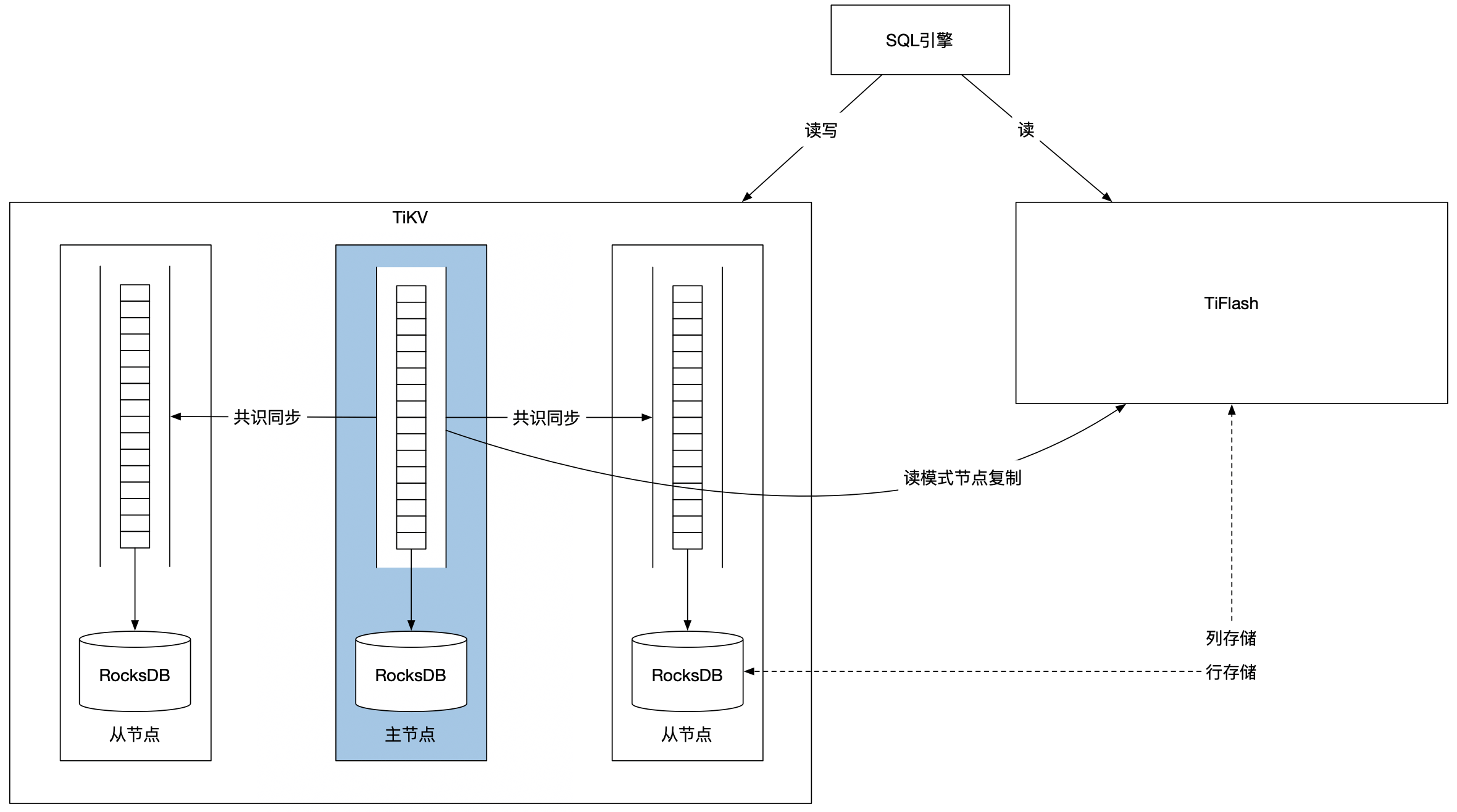
TiDB
用分布式的 TiKV 实现行数据的存储,TiKV 的节点使用 LSM 树实现,写入快查询慢。
用列式存储 TiFlash 用读状态机的方式同步 TiKV 数据,承接复杂查询功能。
动态分库实现
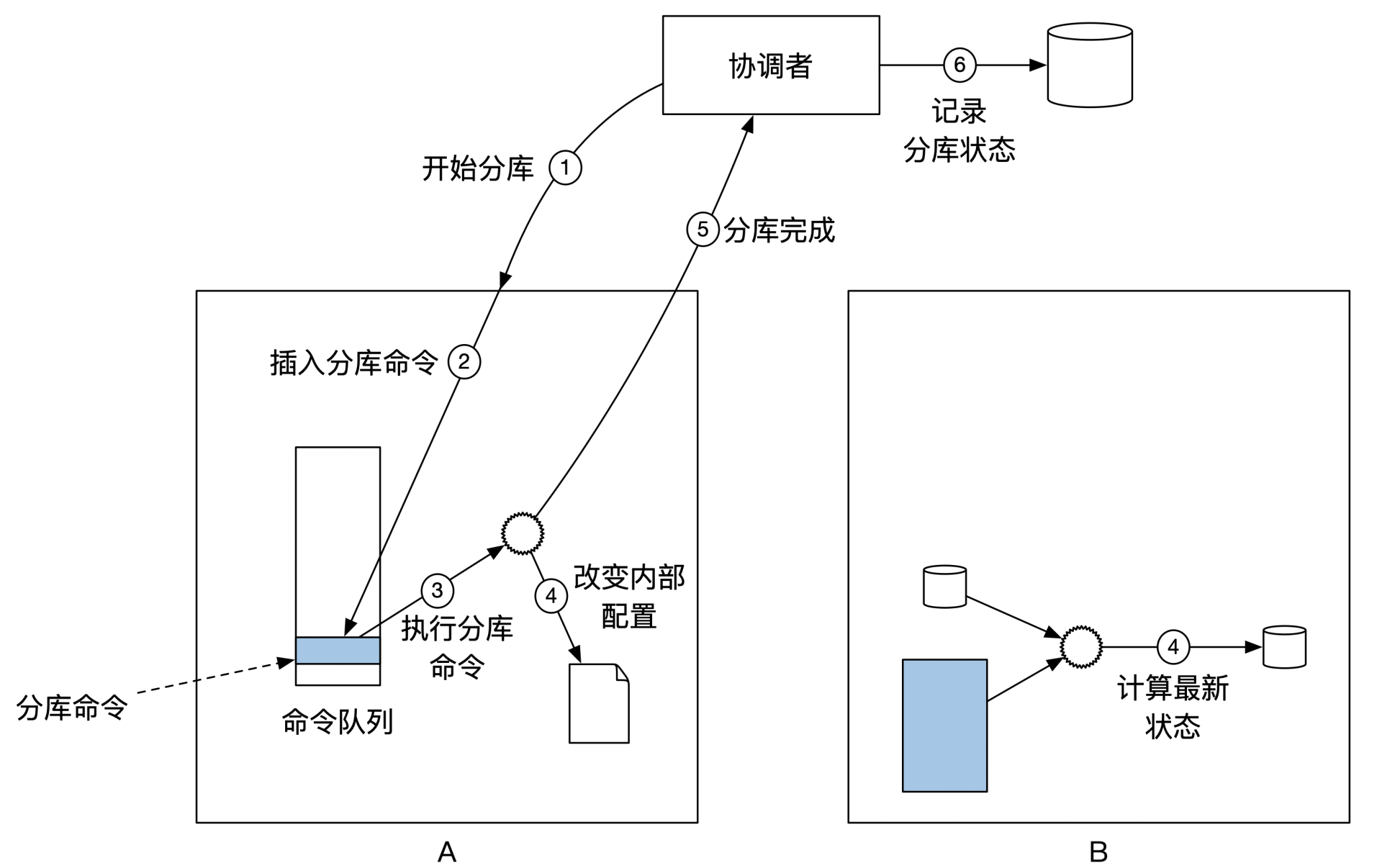
集群A数据复制到集群B:
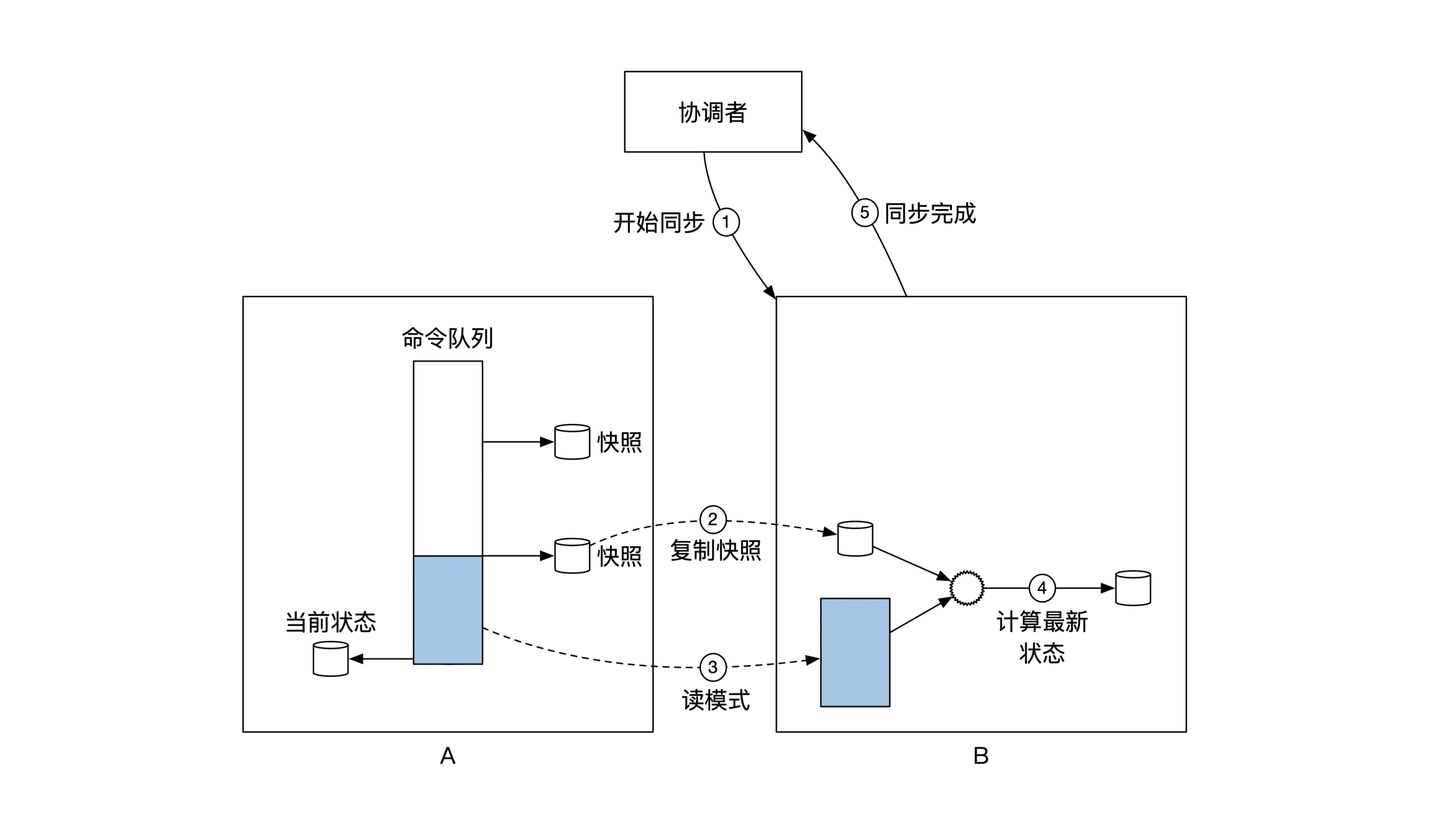
通知集群A进入分库模式:
- 时间段 [ 集群A进入分库模式后,集群B进入分库模式前 ],是系统不能正常响应的中间状态。
- 如果通过事先的数据复制,将该时间段缩小到秒以内,等同于网络重传时间,影响基本可以接受。
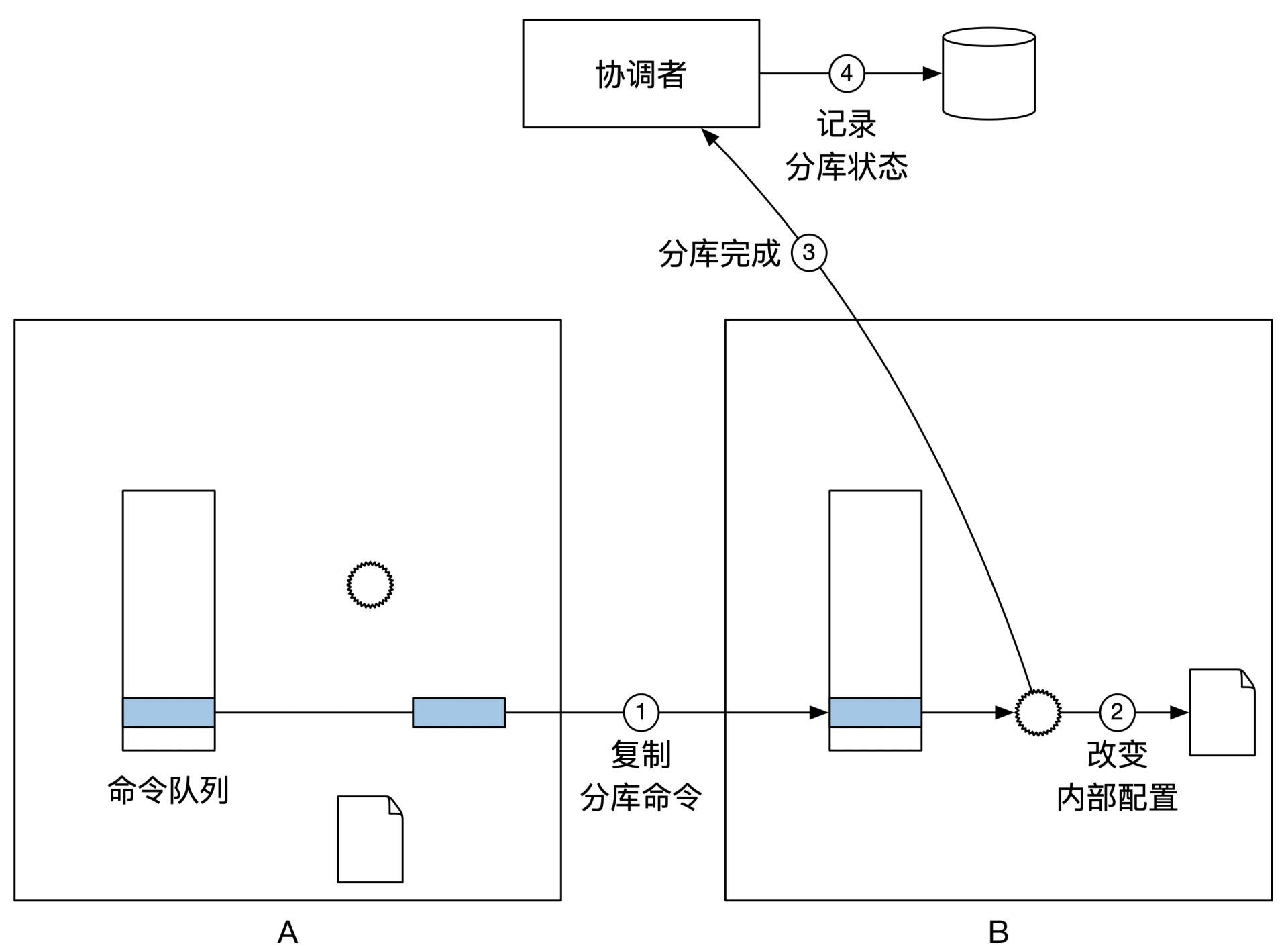
通知集群B进入分库模式:
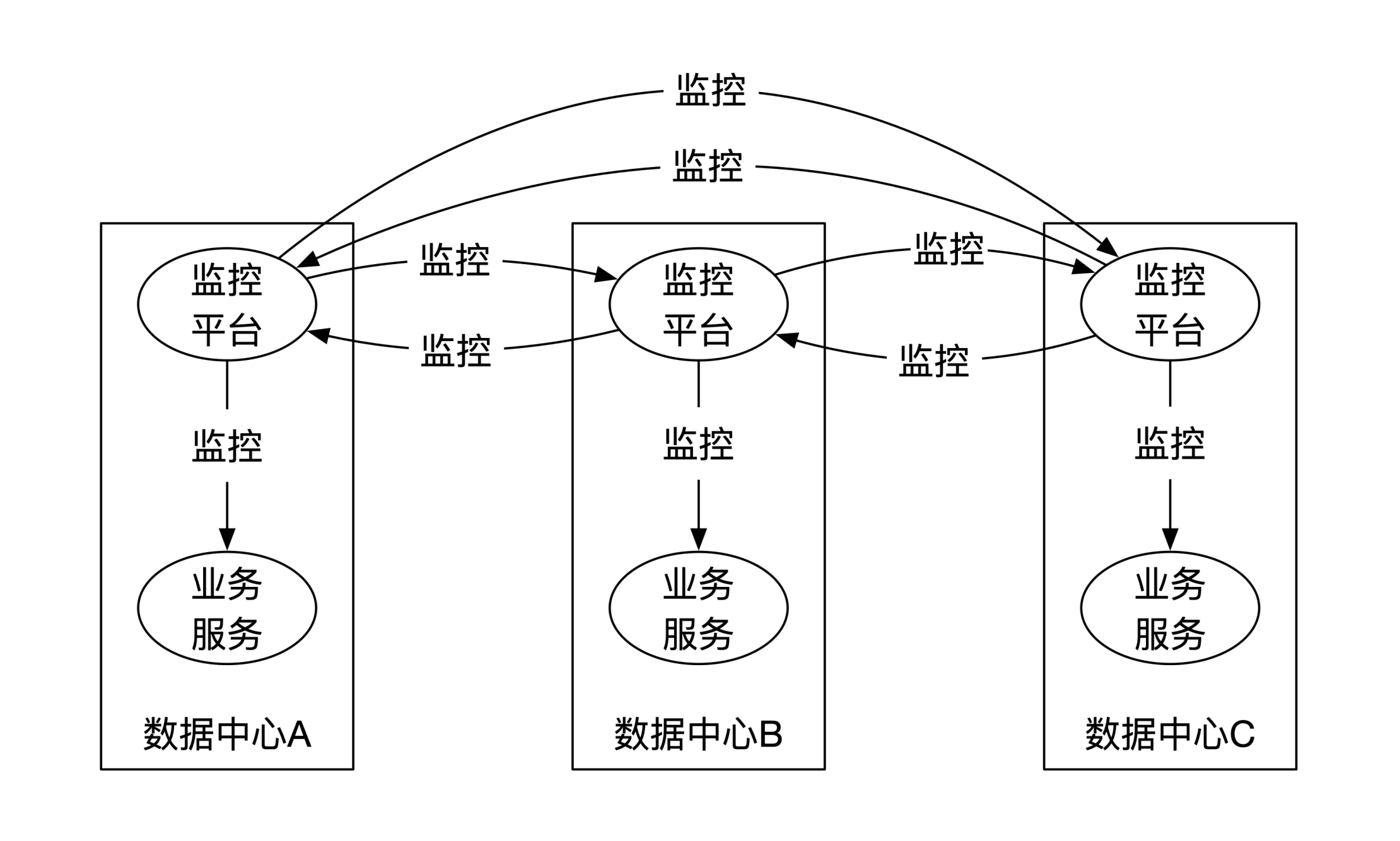
跨机房容灾
每个机房一个独立的监控系统,不同机房的监控系统互相监控:
两地三中心实现数据中心级别容灾:
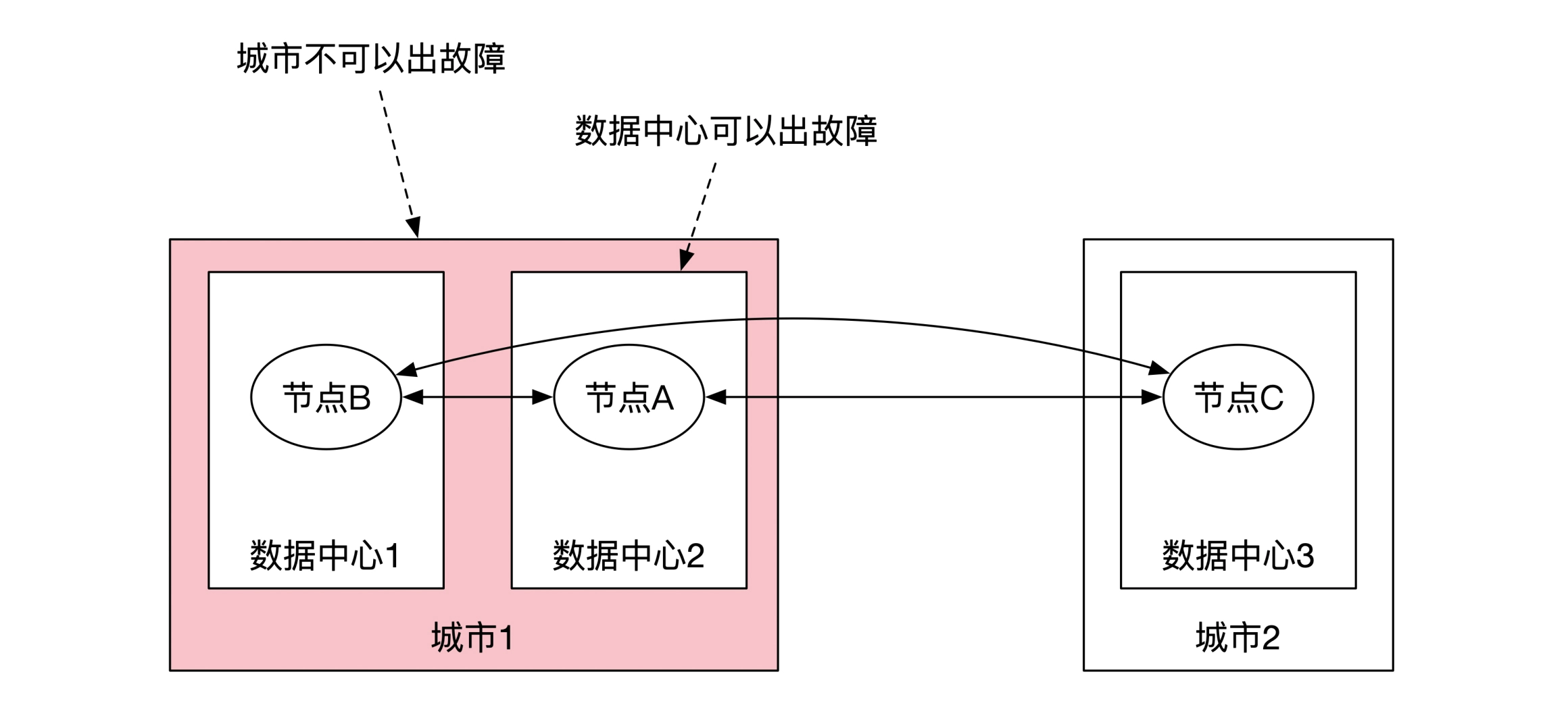
三地五中心实现城市级别容灾:
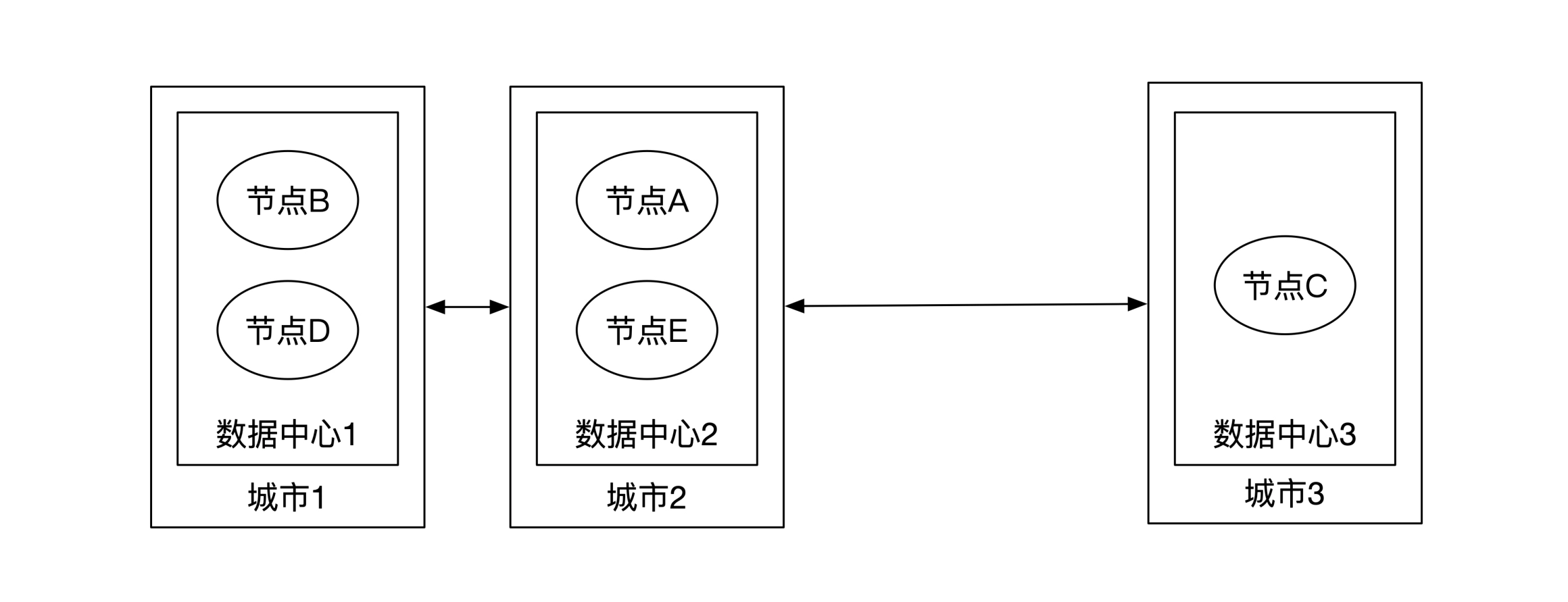
三地九中心实现城市级别容灾,同时减少跨城数据传输:
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文