《高并发系统设计40问》阅读笔记: 数据库/缓存/消息队列/分布式服务
本篇目录
说明
这个专栏比较一般,涉及的内容比较多(数据库/缓存/消息队列/分布式服务),但是蜻蜓点水,不如分别阅读每个方向的专栏,实战篇的三个案例挺好,值得学习。
试读链接:任意四章试读入口
新人优惠:极客时间新注册38元代金券

基本方法
- 水平扩展
- 缓存
- 异步
阿里巴巴的系统分层方法:
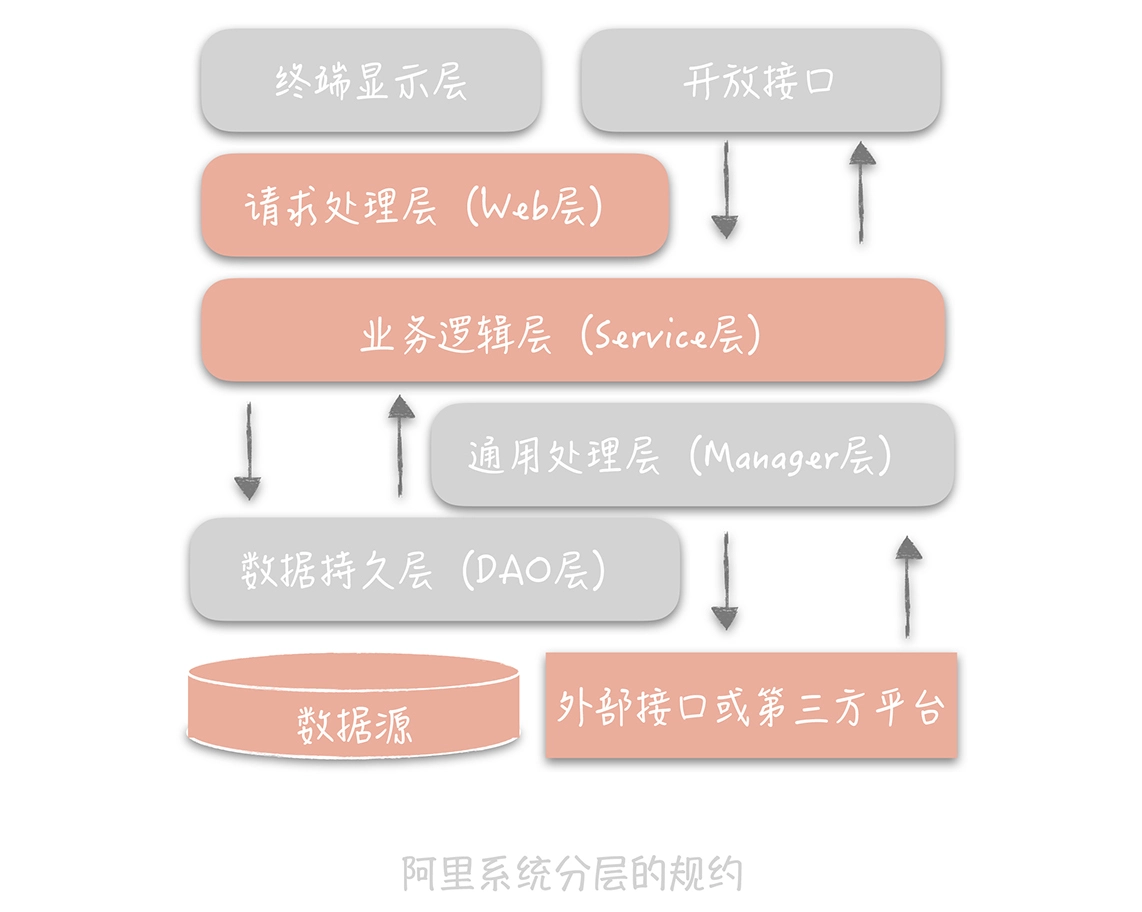
数据库优化
数据库优化方法:
- 使用数据库连接池,避免每次新建连接
- 主从复制,读写分离,主从延迟处理方法
- 数据库分库(垂直拆分):将多个表拆分到多个数据库中
- 数据库分表(水平拆分):将一个表拆分到多个数据库中
- 使用NoSQL方法:1. 具被水平扩展能力,mongo/es等 2. 如果需要模糊查询,使用基于倒排索引的 ES
主从延迟处理方法:
- 编码设计时,通过数据冗余的方式避免写入后立即查询
- 写数据库时,同步写入缓存
- 直连主库
分库分表后注意事项:
- 查询需要带有分区字段,否则会查询所有数据库
- 无法跨库 join
- 聚合查询性能变差,例如count()
- 不能用自增ID作为全局唯一主键
全局唯一主键获取方法:
- 使用 Snowflake 算法生成
- uuid 的问题:不是单调递增的
聚簇索引与基于LSM树的存储引擎:
- 聚簇索引中,索引和数据同时存储,数据插入更新导致随机IO,页分裂时需要移动数据
- LSM树牺牲读性能提高写性能:用多个有序的 SSTable 文件存储,写入时先写入 MemTable,然后择机生成/合并 SSTable
缓存优化
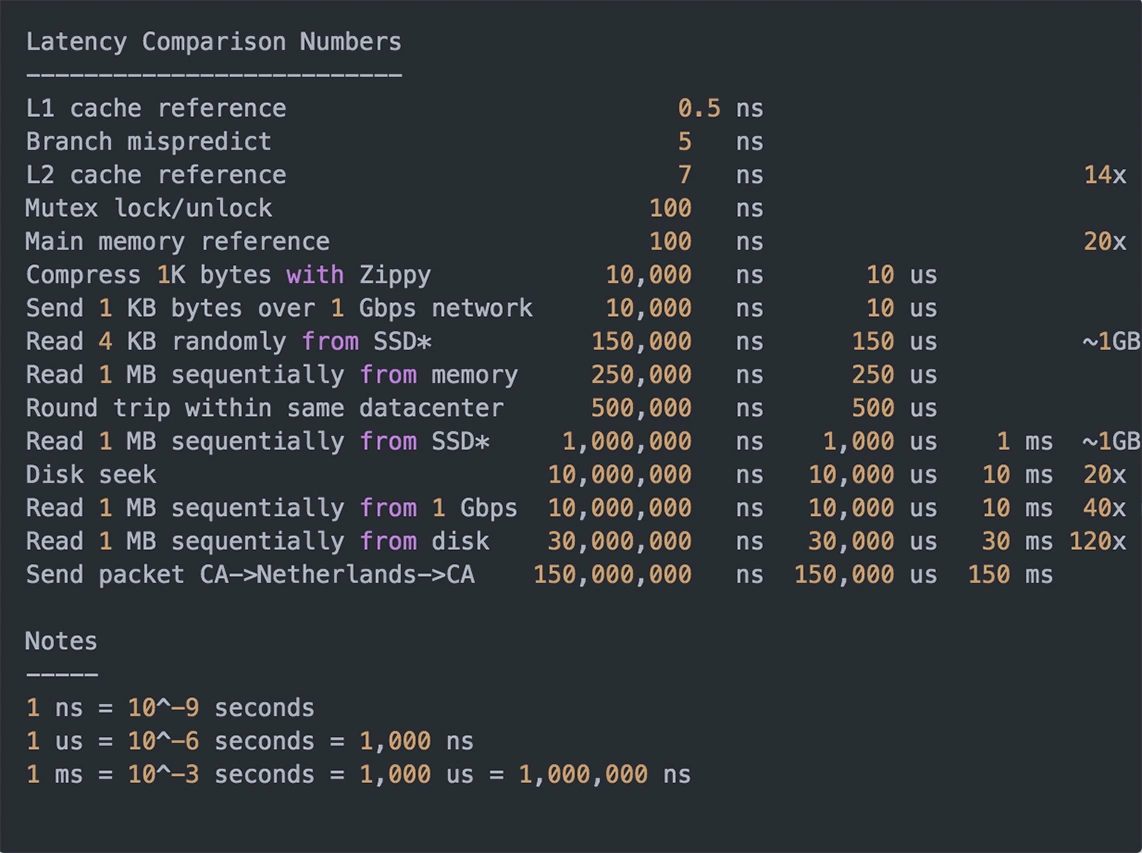
各类操作耗时:ssd磁盘读取耗时是内存读取耗时的1万倍。
缓存会引入数据不一致的问题。
Cache Aside 策略:
- 读取时,如果缓存中存在使用缓存数据,否则查询数据库并更新缓存
- 更新时,先更新数据库,然后删除缓存
- 如果并发操作A在B进行更新前读取了旧数据,B删除缓存后,A才开始更新缓存,这时会出现数据不一致。
- 一种解决方法是「延迟双删」:B更新数据库前删除缓存,更新数据库后等等一段实际,再删一次缓存。(这种方法可以降低数据不一致的概率,但不能完全避免)
Write Through 策略:
- 更新时,缓存中有对应数据,直接更新缓存,然后缓存组件负责将更新同步到数据库
- 更新时,缓存中无对应数据,方式一(Write allocate),写入缓存,缓存组件负责同步到数据库,方式二(No-Write alocate),直接更新数据库
Read Through 策略:
- 读取时,如果缓存中不存在对应数据,由缓存组件负责从数据库中加载
缓存穿透/缓存击穿的处理方法:
- 回种空值,对应数据不存在时,在缓存中写入空值,这种方式会增加缓存空间的使用量(大量空值数据)
- 使用布隆过滤器,将所有存在的ID经过hash、取模后映射到二进制bit数组中,查询时先用布隆过滤器判断是否存在。布隆过滤器判定不存在则一定不存在,但是不存在的记录有可能被判定为存在
极热缓存失效后出现大量穿透的问题的处理(狗桩效应/ dog-pile effect) :
- 设置一个简单的分布式锁(例如 redis 的 setnx),穿透到数据库之前,先获取分布式锁,避免大量并发请求同时穿透数据库
消息队列
这章讲的很一般,没有什么实质性内容,建议阅读另一个专栏: 李玥《消息队列高手课》
分布式服务
这部分也泛泛而谈
多机房部署
北京同地双机房专线延迟:1ms~3ms。
国内异地双机房专线延迟:50ms内,北京到天津 10ms,北京到上海 30ms,北京到广州 50ms。
跨国双机房:100ms~200ms。
同城双活方案:
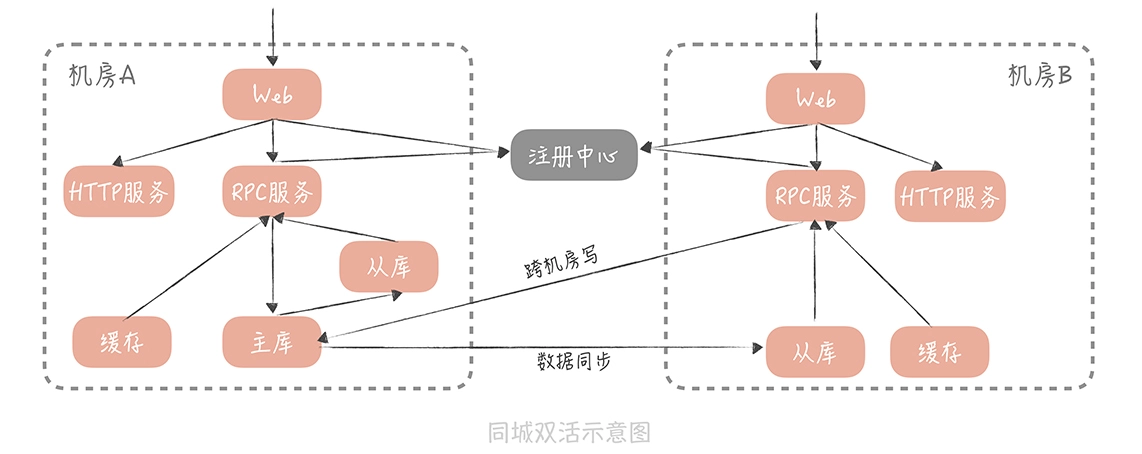
同城双活数据库方案:
- 主库部署在一个机房,另一个机房服务跨机房写库(延迟1~3ms)
- 每个机房都有从库,每个机房中的服务读取各自的从库
- 主库所在机房故障,另一个机房的从库提升为主库
- 服务间调用请求发送到同机房
实战案例
海量计数器的设计
根据 微博2020年用户发展报告,2020年9月微博日活跃用户 2.24 亿,每天 2 亿人次登陆微博,可以推断微博全平台里的微博数量非常庞大。每一条微博都要记录对应都转发数、评论数、点赞数、浏览数等等,即要实现海量的计数器。
- 阶段1: 建立一张计数表,以微博ID为主键,记录每个微博的相应计数
- 阶段2:以微博ID为分区键,选用哈希算法,进行分库分表
- 阶段3:抛弃数据库,以微博ID为 key,只在 redis 中保留计数器数据(引入丢数据风险)
- 阶段4:改造 redis,使用自定义的数据接口,降低内存占用
- 阶段5:改造 redis,实现冷热数据分离,将不经常访问的数据转移到 ssd 磁盘
高QPS的未读数设计
未读数是分别呈现给不同的用户的未读消息数,未读消息可能是一批针对所有用户的消息,例如系统通知,也可能是每个用户订阅的特定消息,例如关注的微博用户。
全员推送消息的场景:
- 面向全部用户的推送的消息是所有用户共享的一组有序消息列表,分别记录每个用户已阅的最后一个消息
- 用全局消息列表总数减去当前用户的最后一个已阅消息位置,得出当前用户的未读消息数
用户订阅消息的场景:
- 不同用户的订阅目标不同,未读消息数不同
- 在缓存中快照用户上一时刻关注的所有用户发布的消息数,用这些被关注用户的当前消息数减去该用户上一时刻的快照,得出当前用户的未读消息数
信息流的推拉模式
用户A发布一条消息后,需要尽快让关注它的 B/C/D 等收到消息:
推模式:
- 为 B/C/D 等每个人建立一个收件箱,将 A 发布的消息推送到所有粉丝的收件箱中
- B/C/D 获取信息流的操作简化,直接读取各自的收件箱即可
- 如果A的粉丝数量非常多,譬如千万乃至上亿,A 每发一条消息,会产生等量的写入
拉模式:
- B 同时关注了 A/C/D,A/C/D 发送消息时,是在各自的发件箱中记录一次
- B 获取信息流时,从构成关注关系的 A/C/D 的发件箱中查询消息
- 如果 B 关注的用户非常多,譬如几千个,每次要查询上千用户的已发布消息。解决方法:将每个用户最近5天的消息ID以用户ID为key,存放到缓存中
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文