多机数据系统的正确性与一致性
本篇目录
什么是数据系统?
凡是需要在「本地」保存数据,并对外开放「读写」功能的系统,都是数据系统。套用微服务里的概念,数据系统都属于「有状态服务」,与之相对纯粹负责计算的系统属于「无状态服务」。典型的 Mysql 数据库、Redis 都是有状态的数据系统。
按照组成系统的机器数量,数据系统又可以分为「单机数据系统」和「分布式数据系统」。
一台 MySQL 属于单机数据系统,如果:
- 增加了一台 MySQL 作为备份机,实现读写分离后,这两台 MySQL 构成了一个分布式数据系统
- 增加了一台 MySQL,把当前 MySQL 上的一些表迁移到了新 MySQL 上,这两台 MySQL 构成了一个分布式数据系统。
1 和 2 是分布式数据系统的中两种截然不同的情况,需要解决的问题也是不同的,后面阐述。
单机数据系统和分布式数据系统有各自需要解决的但是又非常类似的问题,简单说就是:
- 数据正确性问题
- 读写一致性问题
单机的数据正确性
单机数据系统实现时可能要解决各种各种的问题,但是很多问题都可以转换为一个问题:
- 如果机器突然断电了,怎么办?
机器突然断电时,数据可能没写入磁盘、写了一半到磁盘、全部写入了磁盘,要怎么对待「处于中间状态」的数据,它们是可信的还是不可信的?后续的操作能不能使用它们?
个人认为这个问题是「数据的正确性」问题,磁盘上有不可信的数据,或者说脏数据。
数据库系统的处理方法是:
- 提供原子操作。在操作系统的磁盘与用户之间增加一层,在这一层中通过 binlog、redolog 的各种技术手段,让用户的数据提交动作,要么成功,要么失败,对用户而言不存在中间态,从而保证用户读写的数据是正确的,不是脏的。
ACID 原子、一致、隔离、持久,可以认为 A、C、D 都在解决正确性。
ACID中C的定义无论是维基百科还是数据库教材都没有一个特别明确的说明,所以我们采用最广泛使用的 MySQL 数据库对 C 的定义 https://dev.mysql.com/doc/refman/8.0/en/glossary.html#glos_acid
The database remains in a consistent state at all times — after each commit or rollback, and while transactions are in progress. If related data is being updated across multiple tables, queries see either all old values or all new values, not a mix of old and new values.
即数据状态始终是一致的,在事务的任何阶段,要么读到的都是旧数据、要么读到的都是新数据,读到的数据不能是「新旧混合」的。我更倾向于这是「正确性」,以和后面的「并发读写一致性」、「多副本场景的一致性」区别开。
撇开数据库,我们可以继续探讨,往单实例的 redis 中写数据到一半时,如果断电会怎样?
通过研究不同系统的处理方案,可以知道它们分别提供了怎样的保障,各自的优缺点以及适用场景。
单机的并发读写一致性
单机数据系统面临的另一个问题是:并发读写同一份数据时,读操作看到的应该是哪一份数据?写之前的、写了一半的、还是写完以后的?
单机并发读写一致性应该怎样?这是一个没有答案的问题! 因为并发行为的结果是什么,纯粹是一个「怎样约定规则」的问题,规则本身没有对错。
数据库的做法是:定义了读未提交、读已经提交、可重复读、串行化,4种行为规范。数据库说:反正这四种行为规范,我都能遵守,并且只能遵守一个,至于需要我遵守哪个,那就是你的问题了。
并发读写一致性的规则制定思路时,以「并发读写操作」等价于「串行读写」为最严格的一致性规则,然后在性能与严格之间进行协调,为了性能而妥协。
多机的数据正确性
多机数据系统通常构建在单机数据系统之上,组成多机系统的每台机器对外承诺「单机数据的正确性」和「单机并发读写的一致性」。但是只有单机的承诺是不够的,因为多机系统中的数据是分散在每台单机上的:
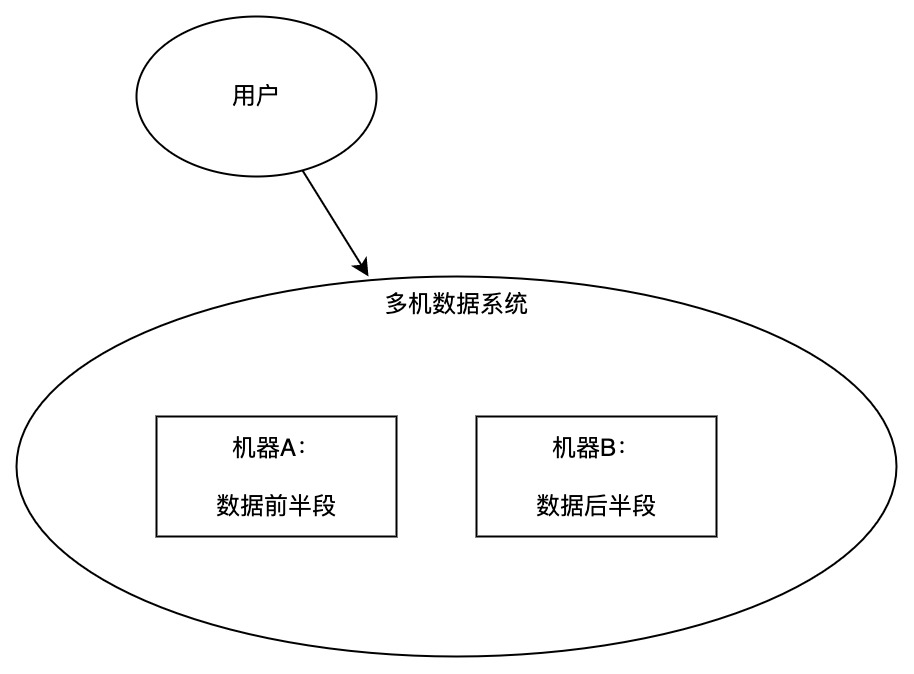
如上图所示,多机数据系统的「一份数据」被分成两段,存放在两台机器上(注意和数据多副本区别开,这里讨论的是没有数据备份的场景)。用户的一次操作,可能既要改前半段,又要改后半段。这意味着对用户而言的一次操作,实际要发送到两台机器上分别执行。
那么问题来了:两台机器中一台故障了怎么办?这个问题和单机的数据正确性,何其类似!一个是单机上操作了一半,一个是多机中部分机器完成操作部分未完成。类似的问题有类似的解决方法,即分布式事务,具体的实现方案譬如 2pc/tcc等,不是非常了解也就不展开了。。!@#¥%……&*.
多机的并发读写一致性
和单机类似,多机系统中也有并发读写的问题。多机中的并发读写行为如何约定?
目前还没找到阐述这个问题的资料,无法展开。。。
多机数据备份场景下的一致性
多机场景下,还有一个非常特殊的场景:数据备份。
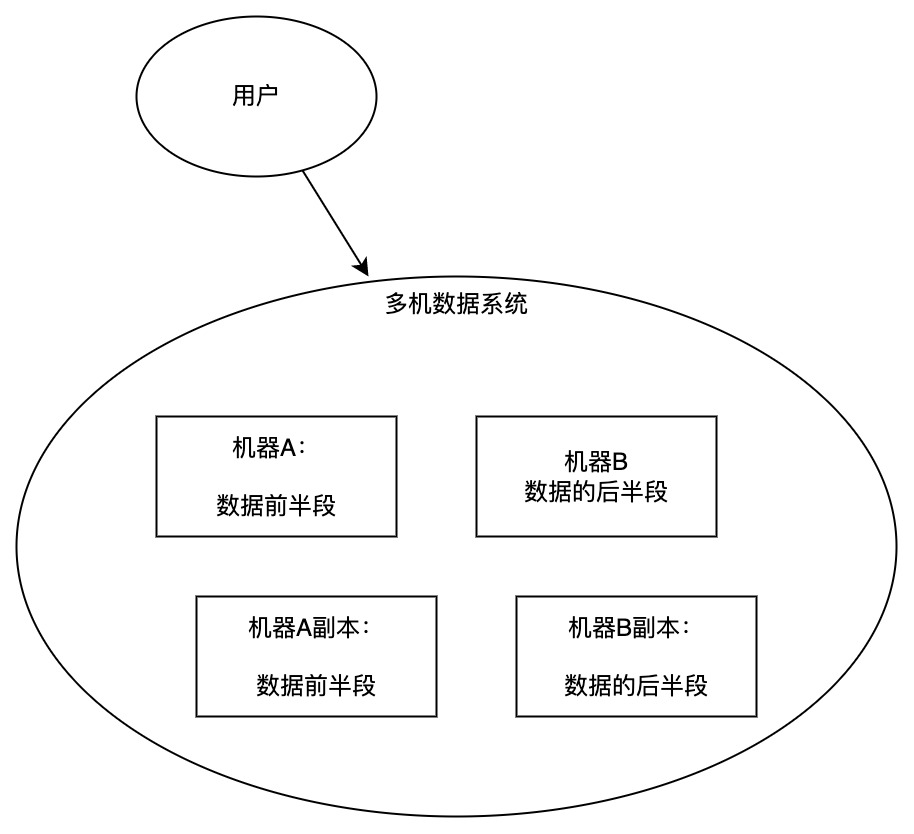
机器A副本完全镜像了机器A的数据,机器B副本完全镜像了机器B的数据。
数据从机器A同步到机器A副本是有延迟的,那么:
- 机器A副本要不要对外提供「读接口」,如果提供,用户会不会从机器A和机器A副本上读到两份不同的数据?
- 如果对机器A进行并发读写,这些读写操作是怎样同步到机器A副本上的,会不会有乱序?
这些问题总结为:多机数据备份场景下的读写一致性问题。
这是也是一个没有标准答案的问题,不同的系统提供不同的承诺。解决多机器数据备份场景问题的经典理论框架是 CAP。CAP 中的 C 指的是存在多副本情况的一种一致性约定。
多副本场景的下的一致性有很多种:譬如单会话单调写一致、单调读一直、自读自写,多会话的先读后写、线性一致性等。分布式数据库、redis集群、ES集群等等对外的承诺可能都是不同的,使用它们的时候首先要考虑它们承诺的是哪一种一致性。
授人以渔
以上内容都是从别的地方扒来的:
强烈推荐这个专栏,微观上搞定操作系统,宏观上搞定分布式,就可以大胆闯荡江湖了。
参考

推荐阅读
Copyright @2011-2019 All rights reserved. 转载请添加原文连接,合作请加微信lijiaocn或者发送邮件: [email protected],备注网站合作
友情链接: Some Online Tools Develop by Me 系统软件 程序语言 运营经验 水库文集 网络课程 微信网文